
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Ранее в этом году И. Ким совместно с соавторами опубликовали статью [1], в которой предложили новую функцию потерь для задач классификации. По оценке авторов, с её помощью можно улучшить качество моделей как в сбалансированных, так и в несбалансированных задачах классификации в сочетании со стандартной кросс-энтропией.
Классификация бывает необходима, например, при создании рекомендательных систем, поэтому описанный метод интересен как с академической точки зрения, так и в контексте решения бизнес-задач.
В нашей статье мы проверим, как комплементарная кросс-энтропия влияет на задачу классификации текста на несбалансированном наборе данных. Наша цель заключается не в проведении широкого экспериментального исследования или создании решения, готового к применению, а в оценке его перспектив. Просим обратить внимание, что код, описанный в статье, может не подходить для применения на проекте и требовать определенной доработки.

Прежде, чем углубляться в разработку и реализацию эксперимента, давайте рассмотрим формулу функции потерь и проанализируем, чего мы можем от нее ожидать.
В статье комплементарная кросс-энтропия определяется следующим образом:
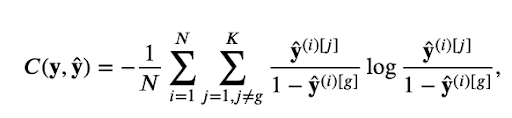
а полная функция потерь, используемая в обучении модели – это сумма со стандартной кросс-энтропией:
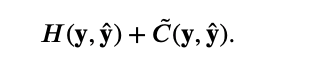
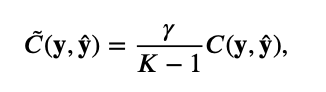
Прежде всего отметим, что знаменатели могут стать равными 0, когда модель идеально предсказывает правильный класс и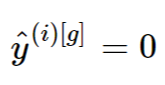 . Чтобы избежать деления на ноль, мы добавим очень маленький ε к знаменателю, так что он никогда не станет 0.
. Чтобы избежать деления на ноль, мы добавим очень маленький ε к знаменателю, так что он никогда не станет 0.
Другая проблема возникает, когда модель полностью неверна и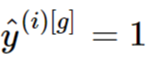 . В этом случае выражение под логарифмом становится равным 0, что делает все выражение неопределенным. Здесь мы будем использовать тот же подход, добавляя небольшой ε, чтобы избежать нулей.
. В этом случае выражение под логарифмом становится равным 0, что делает все выражение неопределенным. Здесь мы будем использовать тот же подход, добавляя небольшой ε, чтобы избежать нулей.
Когда задача включает в себя только два класса, выражение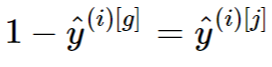 выполняется всегда, и вся комплементарная кросс-энтропия всегда равна нулю. Так что это имеет смысл только в том случае, если число классов в задаче равно трем или более.
выполняется всегда, и вся комплементарная кросс-энтропия всегда равна нулю. Так что это имеет смысл только в том случае, если число классов в задаче равно трем или более.
Наконец, невозможно использовать логиты непосредственно с этой функцией потерь, поскольку она содержит операцию вычитания под логарифмом. Это потенциально может привести к численной нестабильности процесса обучения.
Держа все вышеописанное в голове, можно приступить к разработке эксперимента.
Мы будем использовать простой классификационный датасет с Kaggle [2]. Он подразумевает задачу классификации тональности с пятью классами. Однако крайние классы (очень негативные и очень положительные) и их более умеренные аналоги обычно приписываются очень похожим текстам (см. рис. 1 для примера). Вероятно, это связано с определенной процедурой генерации этого набора данных.

Рис. 1. Примеры однотипных текстов, отнесенных к разным классам.
Чтобы упростить задачу, мы переназначим классы и сделаем три: отрицательный, нейтральный, положительный.
Мы хотели бы проверить, как функция потерь влияет на производительность моделей при нескольких различных степенях несбалансированности классов, поэтому мы сделаем выборку для достижения желаемых пропорций классов. Мы сохраним количество отрицательных примеров постоянными и уменьшим количество нейтральных и положительных примеров относительно него. Конкретные используемые пропорции приведены в таблице 1. Такой подход кажется вполне реалистичным, так как, например, в области отзывов о товарах или услугах пользователи чаще публикуют отрицательные отзывы, чем нейтральные и положительные.
Мы хотели бы проверить, как функция потерь влияет на производительность моделей при нескольких различных степенях несбалансированности классов, поэтому мы сделаем выборку для достижения желаемых пропорций классов. Мы сохраним количество отрицательных примеров постоянными и уменьшим количество нейтральных и положительных примеров относительно него. Конкретные используемые пропорции приведены в таблице 1. Такой подход кажется вполне реалистичным, так как, например, в области отзывов о товарах или услугах пользователи чаще публикуют отрицательные отзывы, чем нейтральные и положительные.
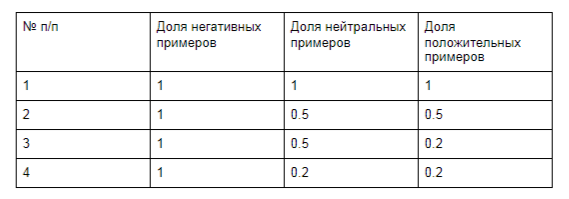
Таблица 1. Классовые пропорции, используемые в экспериментах. Коэффициенты даны относительно количества отрицательных примеров.
Мы сравним комплементарную кросс-энтропию со стандартной кросс-энтропией без весов классов. Мы также не будем рассматривать другие подходы к решению классового дисбаланса, такие как upsampling и downsampling, и добавление синтетических и/или дополненных примеров. Это поможет нам сохранить эксперимент емким и простым.
Наконец, мы разделили данные на train, validation и test сеты в пропорции 0.7 / 0.1 / 0.2.
Мы используем сбалансированную кросс-энтропию в качестве основной метрики производительности модели, таким образом следуя авторам оригинальной статьи. Мы также используем macro-averaged F1 в качестве дополнительной метрики.
Исходный код нашей реализации, включая предварительную обработку данных, функцию потерь, модель и эксперименты, доступны на GitHub [3]. Здесь мы просто рассмотрим его ключевые моменты.
Мы используем фреймворк PyTorch для этого эксперимента, но те же результаты могут быть легко воспроизведены с помощью TensorFlow или других фреймворков.
Реализация функции комплементарной кросс-энтропии довольно прямолинейна. Мы используем cross_entropy из PyTorch для стандартной кросс-энтропии, поэтому наша функция потерь принимает на вход логиты. Далее она переводит их в вероятности, чтобы вычислить комплементарную часть.
Предварительная обработка данных включает в себя стандартную токенизацию при помощи модели en из SpaCy.
Модель, которую мы используем, представляет собой bidirectional LSTM с одним полносвязным слоем поверх него. Dropout применяется к эмбеддингам и выходам LSTM. Модель не использует предобученные эмбеддинги и оптимизирует их в процессе обучения.
Детали процесса обучения: batch size 256, learning rate 3e-4, размер эмбеддингов 300, размер LSTM 128, уровень dropout 0,1, обучение в течение 50 эпох с остановкой после 5 эпох без улучшения качества на валидации. Мы используем одни и те же параметры как для экспериментов с комплементарной, так и для экспериментов со стандартной кросс-энтропией.
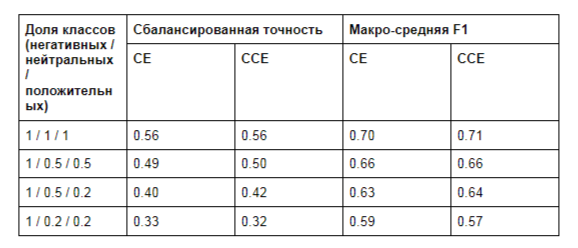
Таблица 2. Результаты экспериментов. CE для эксперимента со стандартной кросс-энтропией и ССЕ – для комплементарной.
Как видно из таблицы, комплементарная кросс-энтропия не дает существенных улучшений по сравнению со стандартной функцией кросс-энтропии при любой степени дисбаланса классов. Выигрыш в 1-2 процентных пункта можно интерпретировать как случайные колебания, обусловленные вероятностным характером процесса обучения. Мы также не видим никакого улучшения качества модели с новой функцией потерь в сравнении со стандартной моделью.
Ещё одну проблему комплементарной кросс-энтропии можно увидеть на графиках функции потерь (рис. 2).

Рис. 2. Графики потерь для степеней дисбаланса 1 / 0.2 / 0.2 (оранжевый) и 1 / 0.5 / 0.5 (зеленый).
Как можно видеть, значения упали далеко в отрицательную область. Это, вероятно, связано с проблемой численной нестабильности, которую мы обсуждали ранее. Интересно, что значения на валидации остались без изменений.
Мы описали наши эксперименты по применению комплементарной кросс-энтропии к задаче классификации текстов с различной степенью дисбаланса классов. В экспериментах эта функция потерь не позволила получить сколько-нибудь существенного преимущества по сравнению со стандартной кросс-энтропией с точки зрения качества получаемых моделей. Более того, потеря продемонстрировала теоретические и экспериментальные проблемы, которые затрудняют ее использование в реальных проектах.
[1] Y. Kim et al, 2020. Imbalanced Image Classification with Complement Cross Entropy. arxiv.org/abs/2009.02189
[2] www.kaggle.com/c/sentiment-analysis-on-movie-reviews/overview
[3] github.com/simbirsoft/cce-loss-text
Классификация бывает необходима, например, при создании рекомендательных систем, поэтому описанный метод интересен как с академической точки зрения, так и в контексте решения бизнес-задач.
В нашей статье мы проверим, как комплементарная кросс-энтропия влияет на задачу классификации текста на несбалансированном наборе данных. Наша цель заключается не в проведении широкого экспериментального исследования или создании решения, готового к применению, а в оценке его перспектив. Просим обратить внимание, что код, описанный в статье, может не подходить для применения на проекте и требовать определенной доработки.
Предварительный анализ
Прежде, чем углубляться в разработку и реализацию эксперимента, давайте рассмотрим формулу функции потерь и проанализируем, чего мы можем от нее ожидать.
В статье комплементарная кросс-энтропия определяется следующим образом:
а полная функция потерь, используемая в обучении модели – это сумма со стандартной кросс-энтропией:
Прежде всего отметим, что знаменатели могут стать равными 0, когда модель идеально предсказывает правильный класс и
. Чтобы избежать деления на ноль, мы добавим очень маленький ε к знаменателю, так что он никогда не станет 0.Другая проблема возникает, когда модель полностью неверна и
. В этом случае выражение под логарифмом становится равным 0, что делает все выражение неопределенным. Здесь мы будем использовать тот же подход, добавляя небольшой ε, чтобы избежать нулей.Когда задача включает в себя только два класса, выражение
выполняется всегда, и вся комплементарная кросс-энтропия всегда равна нулю. Так что это имеет смысл только в том случае, если число классов в задаче равно трем или более.Наконец, невозможно использовать логиты непосредственно с этой функцией потерь, поскольку она содержит операцию вычитания под логарифмом. Это потенциально может привести к численной нестабильности процесса обучения.
Проектирование эксперимента
Держа все вышеописанное в голове, можно приступить к разработке эксперимента.
Мы будем использовать простой классификационный датасет с Kaggle [2]. Он подразумевает задачу классификации тональности с пятью классами. Однако крайние классы (очень негативные и очень положительные) и их более умеренные аналоги обычно приписываются очень похожим текстам (см. рис. 1 для примера). Вероятно, это связано с определенной процедурой генерации этого набора данных.
Рис. 1. Примеры однотипных текстов, отнесенных к разным классам.
Чтобы упростить задачу, мы переназначим классы и сделаем три: отрицательный, нейтральный, положительный.
Мы хотели бы проверить, как функция потерь влияет на производительность моделей при нескольких различных степенях несбалансированности классов, поэтому мы сделаем выборку для достижения желаемых пропорций классов. Мы сохраним количество отрицательных примеров постоянными и уменьшим количество нейтральных и положительных примеров относительно него. Конкретные используемые пропорции приведены в таблице 1. Такой подход кажется вполне реалистичным, так как, например, в области отзывов о товарах или услугах пользователи чаще публикуют отрицательные отзывы, чем нейтральные и положительные.
Мы хотели бы проверить, как функция потерь влияет на производительность моделей при нескольких различных степенях несбалансированности классов, поэтому мы сделаем выборку для достижения желаемых пропорций классов. Мы сохраним количество отрицательных примеров постоянными и уменьшим количество нейтральных и положительных примеров относительно него. Конкретные используемые пропорции приведены в таблице 1. Такой подход кажется вполне реалистичным, так как, например, в области отзывов о товарах или услугах пользователи чаще публикуют отрицательные отзывы, чем нейтральные и положительные.
Таблица 1. Классовые пропорции, используемые в экспериментах. Коэффициенты даны относительно количества отрицательных примеров.
Мы сравним комплементарную кросс-энтропию со стандартной кросс-энтропией без весов классов. Мы также не будем рассматривать другие подходы к решению классового дисбаланса, такие как upsampling и downsampling, и добавление синтетических и/или дополненных примеров. Это поможет нам сохранить эксперимент емким и простым.
Наконец, мы разделили данные на train, validation и test сеты в пропорции 0.7 / 0.1 / 0.2.
Мы используем сбалансированную кросс-энтропию в качестве основной метрики производительности модели, таким образом следуя авторам оригинальной статьи. Мы также используем macro-averaged F1 в качестве дополнительной метрики.
Детали проекта
Исходный код нашей реализации, включая предварительную обработку данных, функцию потерь, модель и эксперименты, доступны на GitHub [3]. Здесь мы просто рассмотрим его ключевые моменты.
Мы используем фреймворк PyTorch для этого эксперимента, но те же результаты могут быть легко воспроизведены с помощью TensorFlow или других фреймворков.
Реализация функции комплементарной кросс-энтропии довольно прямолинейна. Мы используем cross_entropy из PyTorch для стандартной кросс-энтропии, поэтому наша функция потерь принимает на вход логиты. Далее она переводит их в вероятности, чтобы вычислить комплементарную часть.
Предварительная обработка данных включает в себя стандартную токенизацию при помощи модели en из SpaCy.
Модель, которую мы используем, представляет собой bidirectional LSTM с одним полносвязным слоем поверх него. Dropout применяется к эмбеддингам и выходам LSTM. Модель не использует предобученные эмбеддинги и оптимизирует их в процессе обучения.
Детали процесса обучения: batch size 256, learning rate 3e-4, размер эмбеддингов 300, размер LSTM 128, уровень dropout 0,1, обучение в течение 50 эпох с остановкой после 5 эпох без улучшения качества на валидации. Мы используем одни и те же параметры как для экспериментов с комплементарной, так и для экспериментов со стандартной кросс-энтропией.
Результаты экспериментов
Таблица 2. Результаты экспериментов. CE для эксперимента со стандартной кросс-энтропией и ССЕ – для комплементарной.
Как видно из таблицы, комплементарная кросс-энтропия не дает существенных улучшений по сравнению со стандартной функцией кросс-энтропии при любой степени дисбаланса классов. Выигрыш в 1-2 процентных пункта можно интерпретировать как случайные колебания, обусловленные вероятностным характером процесса обучения. Мы также не видим никакого улучшения качества модели с новой функцией потерь в сравнении со стандартной моделью.
Ещё одну проблему комплементарной кросс-энтропии можно увидеть на графиках функции потерь (рис. 2).
Рис. 2. Графики потерь для степеней дисбаланса 1 / 0.2 / 0.2 (оранжевый) и 1 / 0.5 / 0.5 (зеленый).
Как можно видеть, значения упали далеко в отрицательную область. Это, вероятно, связано с проблемой численной нестабильности, которую мы обсуждали ранее. Интересно, что значения на валидации остались без изменений.
В заключение
Мы описали наши эксперименты по применению комплементарной кросс-энтропии к задаче классификации текстов с различной степенью дисбаланса классов. В экспериментах эта функция потерь не позволила получить сколько-нибудь существенного преимущества по сравнению со стандартной кросс-энтропией с точки зрения качества получаемых моделей. Более того, потеря продемонстрировала теоретические и экспериментальные проблемы, которые затрудняют ее использование в реальных проектах.
Примечания
[1] Y. Kim et al, 2020. Imbalanced Image Classification with Complement Cross Entropy. arxiv.org/abs/2009.02189
[2] www.kaggle.com/c/sentiment-analysis-on-movie-reviews/overview
[3] github.com/simbirsoft/cce-loss-text

