
Сегодня мы изучим канальный «протокол покрывающего дерева» STP. Многих людей эта тема пугает из-за кажущейся сложности, потому что они не могут понять, что именно делает протокол STP. Надеюсь, что в конце этого видеоурока или на следующем уроке вы поймете, как работает это «дерево». Прежде чем приступить к уроку, хочу показать вам новый дизайн моего рабочего стола на эту неделю.
Вы тоже можете настроить свой десктоп подобным образом, если воспользуетесь ссылкой в правом верхнем углу этого видео. И пожалуйста, не забывайте «лайкать» и делиться с друзьями моими видеоуроками.
Как и в прошлый раз, сегодня мы обсудим очередную тему согласно расписанию ICND2, представленному на сайте Cisco. Это раздел 1.3 «Настройка, проверка и неполадки протоколов STP», подпункт 1.3а «Режимы STP (PVST+ и RPVST+)» и 1.3b «Выбор корневого свитча STP (Root bridge)».
Поскольку это обширная тема, я перенес рассмотрение подраздела 1.3b на следующий урок «День 37», туда же я добавлю раздел 1.4. Итак, сегодня мы рассмотрим, что представляет собой STP, изучим режимы этого протокола PVST+ и RPVST+, а затем рассмотрим идентификатор корневого свитча Bridge ID и стоимость маршрута до корневого порта Port Cost.

Для начала нам нужно понять, что собой представляет петля коммутации, возникающая на 2 уровне модели OSI (на уровне фреймов), и какие проблемы с ней связаны. Мы уже обсуждали зацикливание трафика в одной из предыдущих серий, и тот урок можно считать введением в сегодняшнюю тему. Приведу пример: у нас имеется свитч А и свитч В, соединенные друг с другом двумя линиями связи, первого пользователя зовут Джо, а второго – Джим.

Если Джо отсылает сообщение Джиму, то он отправляет фрейм свитчу А. Свитч А не знает MAC-адрес Джима, поэтому он отправляет бродкаст-фрейм через все порты, кроме того, через который поступило сообщение Джо. Когда бродкаст-фрейм принимается портами свитча В, то пакет, пришедший по одному интерфейсу, отсылается Джиму, а пакет, пришедший по второму интерфейсу, переадресуется на первый порт и отправляется обратно свитчу А.

В то же время запрос, пришедший по первому интерфейсу, переадресовывается второму порту и тоже отправляется свитчу А.
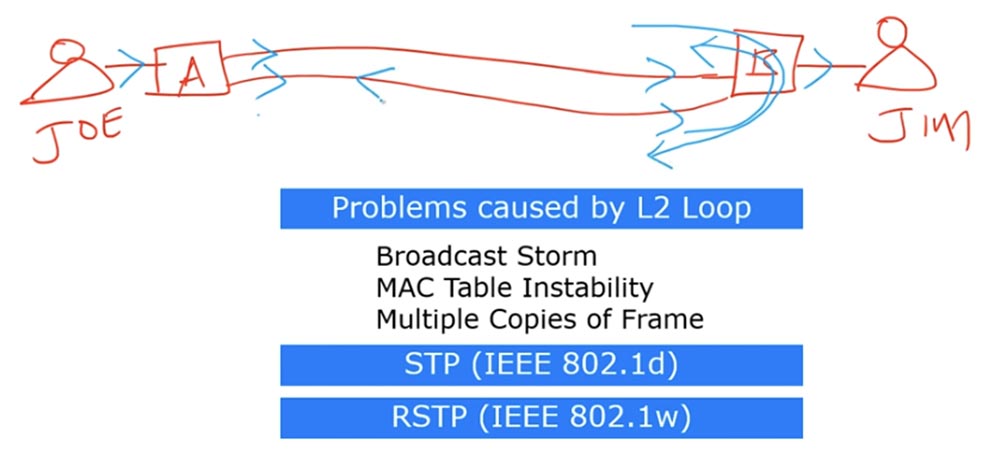
Получив эти бродкаст-фреймы, свитч А отсылает их обратно: фрейм, поступивший по первому интерфейсу, отсылается по второму, а поступивший по второму отправляется в сеть через первый интерфейс. Этот процесс повторяется снова и снова, образуя петлю широковещательных запросов. Если в сеть поступает другой бродкаст, он точно так же зацикливается вместе с первым. В результате возникает явление, получившее название Broadcast storm, или широковещательный шторм. Сеть наводняет такое количество бродкаст-фреймов, что она выходит из строя. Этот шторм может прекратиться только тогда, когда отключится одно из устройств или соединение разорвется. Если линия останется работоспособной, то вскоре после начала такого шторма один из свитчей прекратит работу из-за переполнения памяти. Во втором случае петля может возникнуть по причине пересылки фрейма с юникастовым MAC-адресом. Эта проблема носит название «нестабильности таблицы MAC-адресов». Она происходит, когда между свитчами имеется более двух соединений. Я нарисую схему, в которой свитчи А, В и С соединены друг с другом и между ними тоже может образоваться петля.
Свитч А имеет три интерфейса: f0/1, f0/2 и f0/3. Предположим, что пользователь имеет компьютер с MAC-адресом ААА и отправляет бродкаст-фрейм свитчу А. Свитч принимает этот фрейм через интерфейс f0/1. В сети есть еще один пользователь, компьютер которого имеет MAC-адрес ВВВ. Таким образом, у нас имеется адрес источника ААА и адрес назначения ВВВ.
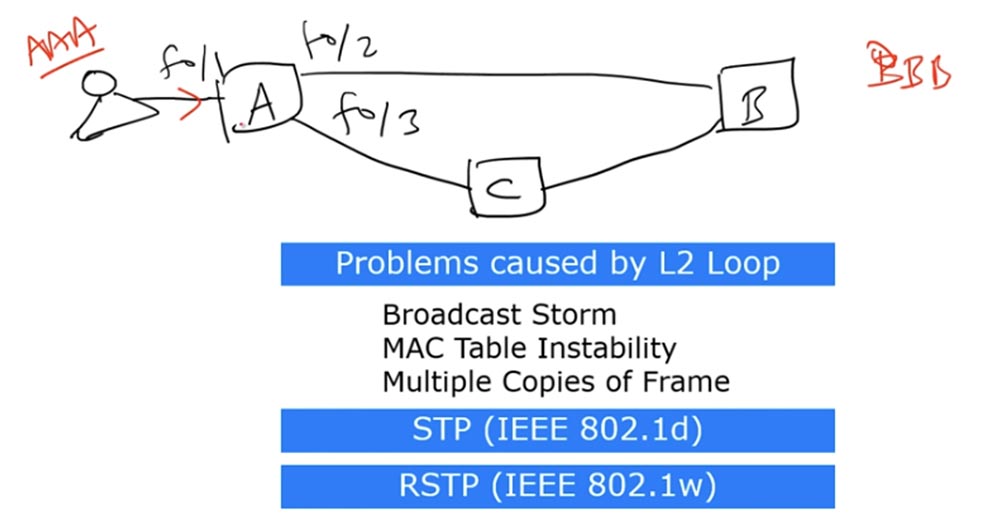
Свитч А не знает, как добраться до MAC-адреса назначения BBB, но зато знает, что до MAC-адреса источника ААА можно добраться через интерфейс f0/1 и помещает запись об этом в свою таблицу MAC-адресов. Далее свитч А рассылает запрос об адресе назначения по двум остальным интерфейсам — f0/2 и f0/3.
Получив запрос ААА, свитч В видит, что он пришел из источника f0/2 и помещает в свою таблицу MAC-адресов запись, что устройство ААА достижимо через интерфейс f0/2. Кроме того, у него уже есть запись, что назначению BBB соответствует интерфейс f0/1, поэтому он отсылает запрос адресату.
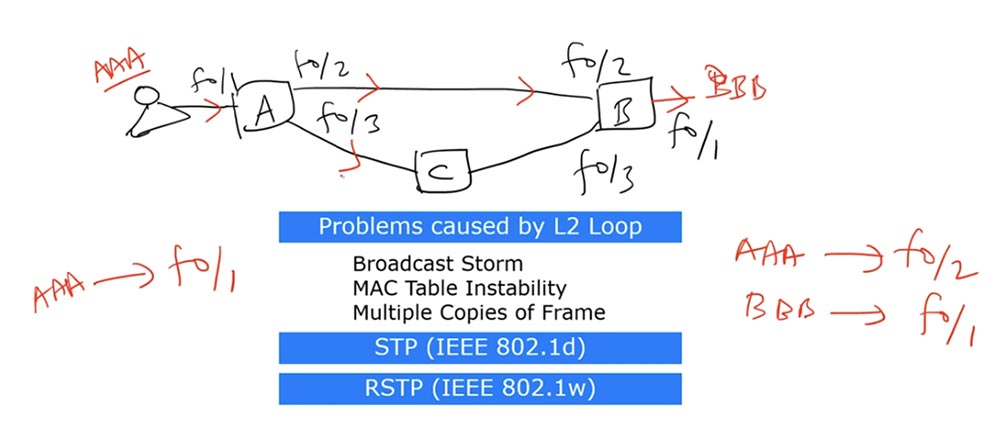
Поскольку свитч А выслал бродкаст-фрейм, тот отправился не только через интерфейс f0/2 к свитчу B, но и через интерфейс f0/3 к свитчу С, который, в свою очередь, переслал его интерфейсу f0/3 свитча В.
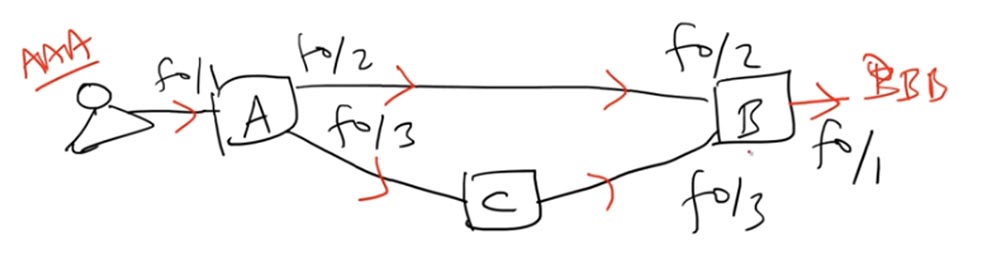
Получив фрейм, свитч В думает так: «я знаю, что источник ААА ранее располагался на интерфейсе f0/2, но сейчас фрейм от него пришел ко мне через интерфейс f0/3, значит, я должен обновить свою таблицу MAC-адресов и заменить f0/2 на f0/3».
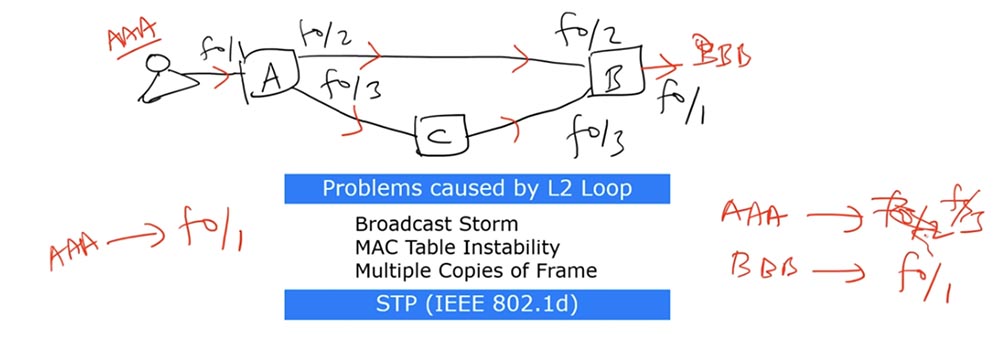
Далее фрейм отправится обратно к свитчу А и очень его «удивит»: раньше свитч А думал, что источник ААА соединен интерфейсом f0/1, а теперь выясняется, что сообщение от него пришло с интерфейса f0/2. При обратном направлении фрейма через свитч В и С свитч А получит сообщение, которое смутит его еще раз – теперь получается, что источник ААА расположен на интерфейсе f0/3.
Таким образом, таблица MAC-адресов этого свитча постоянно будет обновляться между этими тремя интерфейсами, то есть возникнет вышеупомянутая проблема нестабильности таблицы MAC-адресов. Как и в первом случае, здесь образуется петля фреймов, приводящая к обновлению таблицы каждые несколько секунд.
Существует и третья проблема зацикливания – множественные копии фрейма. Пользователь ААА отправляет фрейм свитчу А, то отправляет его через интерфейс f0/2 свитчу В, который доставляет его назначению BBB через интерфейс f0/1. Здесь не возникает никаких проблем.
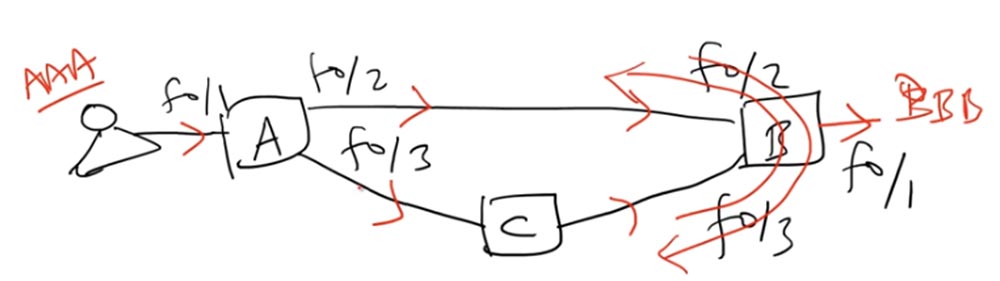
Но одновременно свитч А отправляет этот же фрейм через свой второй интерфейс f0/3 свитчу С, который пересылает его свитчу B. Получив пакет, или фрейм, от свитча С, свитч В видит, что он адресован BBB, и отправляет его адресату. Таким образом, пользователь BBB дважды получает один и тот же пакет. Здесь возникает проблема – если это рассылка данных, совершаемых приложением, то один и тот же фрейм не должен приходить пользователю два раза.
Таковы три проблемы, которые могут быть вызваны петлями фреймов. Все они решаются одним способом, о котором мы говорили ранее – использованием протокола STP. В одном из предыдущих видео, не помню его номер, когда мы обсуждали режимы портов, уже говорилось об этом протоколе, который служит для предотвращения образования петель трафика в сети.
Итак, петля образуется, когда три устройства соединены друг с другом, образуя замкнутый контур сети, и принадлежат одному широковещательному домену. Для такого случая алгоритм, используемый протоколом STP, назначает один из свитчей корневым коммутатором — Root Bridge. Давайте выберем в качестве корневого коммутатора свитч А.

Каждый порт, подключенный к корневому свитчу, должен быть в состоянии передачи Forwarding, это левые порты свитча C и B. Эти порты обеспечивают передачу пакетов, или фреймов, в направлении корневого свитча А. По линии соединения свитчей С и В один из портов должен быть в состоянии блокировки Blocking.
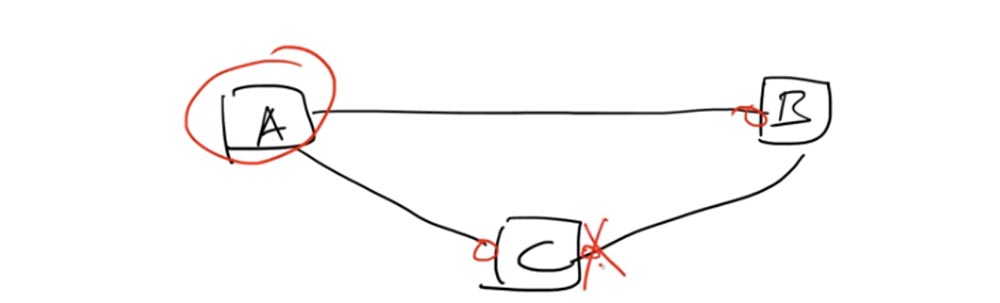
Это означает, что он не отсылает трафик. Свитч В может продолжать отсылать трафик свитчу С, но его правый порт не будет обрабатывать этот трафик, хотя физически будет продолжать работать. Это осуществляется при помощи идентификатора моста, или идентификатора свитча BID – Bridge ID.
Вы должны помнить, что протокол STP был создан задолго до того, как появились Ethernet-свитчи. Тогда вместо термина switch – коммутатор использовался термин bridge – мост, и многие протоколы до сих пор используют классическую терминологию технических стандартов. Так что сейчас BID – это идентификатор свитча.
Информация, которой корневой свитч обменивается с другими свитчами, называется BPDU. Устройства обмениваются сообщениями BPDU каждые 2 секунды – это время носит название «таймер hello». Сообщение BPDU содержит идентификатор корневого свитча BID и стоимость маршрута до корневого свитча, или Root Path Cost (фактически это расстояние до корневого свитча). Стоимость пути на каждом порту служит для вычисления кратчайшего пути до корневого свитча, но мы не будем углубляться в данное понятие.
Логически схема работает так: благодаря заблокированному правому порту свитча С трафик, идущий в направлении свитч А – свитч В – свитч С не поступает свитчу А, то есть не замыкается в петлю. С направляет трафик А, тот отправляет его В, свитч В направляет его С, и в этом месте петля разрывается.
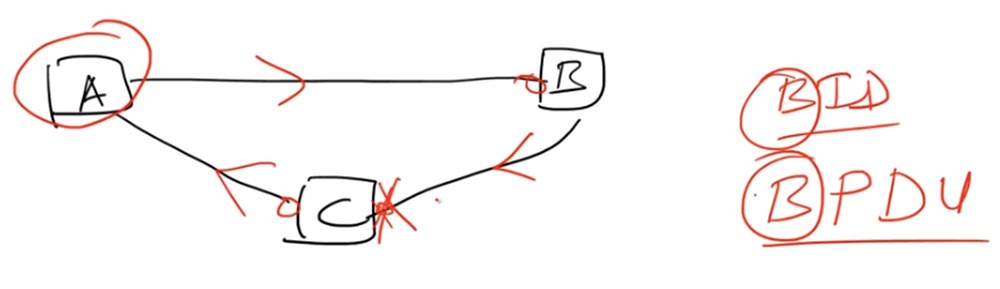
Вот как работает протокол STP, который является стандартом IEEE 802.1d. Это очень старый стандарт, недостатком которого является максимальное время обновления информации при обрыве связи, равное 50 секундам. Кроме состояния блокировки порта Blocking, он поддерживает ещё 2 промежуточных состояния — Listening (Прослушивание) и Learning (Обучение — подготовка к пересылке), после которых переходит к состоянию передачи Forwarding.
Каждые 2 секунды свитчи обмениваются сообщением hello – C посылает его В и А, А посылает hello C и В и так далее. Если какое устройство не получает этого сообщения, оно ожидает его еще в течение 10-ти кратного периода таймера hello, то есть 20 секунд. После этого оно ожидает какого-либо действия, перейдя в состояние Listening, которое длится 15 секунд, затем переходит в состояние Learning и пребывает в нем ещё 15 с. Таким образом, общий период бездействия составляет 50с. Для современных сетей это достаточно длительный промежуток времени.
Для улучшения этой ситуации был введен другой стандарт — IEEE 802.1w, или Rapid STP – быстрый протокол STP, обозначаемый как RSTP. Он лишен промежуточных состояний и переходит из состояния Blocking к состоянию Forwarding.
В STP существуют корневые порты Root Port – это порты, через которые осуществляется связь с корневым свитчем. В RSTP добавлено понятие альтернативных портов Alternative Port, не связанных с корневым свитчем. В случае, если между корневым портом RP и корневым свитчем происходит обрыв связи, альтернативный порт ALT сразу превращается в корневой порт RP, и связь осуществляется по другому маршруту.
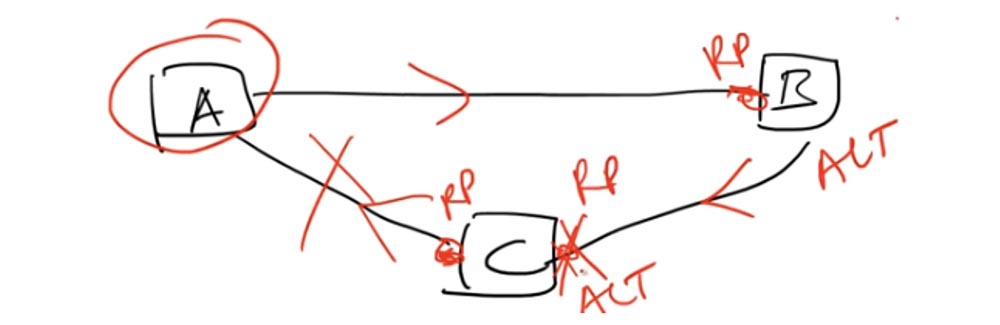
При самом сложном развитии событий весь этот процесс занимает максимум 10 с, а 10 с бездействия намного лучше, чем 50 секунд. Вот в чем состоит основная разница между STP и RSTP.
Сейчас Cisco использует STP различными способами, но первоначально он предназначался для работы в одном широковещательном домене с Native VLAN, поэтому STP воспринимался как часть VLAN1. При этом считалось, что весь трафик является частью этого единого широковещательного домена. По мере развития сетевых устройств Cisco стала использовать STP другими способами, создав PVSTP (Per-VLAN Spanning Tree), проприетарный протокол, предназначенный для работы с несколькими VLAN. Это означало, что каждая VLAN будет иметь свой STP, то есть свой собственный корневой свитч Root Bridge.

Точно так же, как Cisco усовершенствовала STP, создав RSTP, она разработала «ускоренную» версию PVSTP – RPVSTP. Оба эти протокола осуществляли инкапсуляцию по проприетарному протоколу ISL и не поддерживали стандарт 802.1q, поскольку были разработаны еще до его принятия. Для обеспечения совместимости стандартов Cisco усовершенствовала эти протоколы, добавив в них поддержку 802.1q. Новые протоколы, поддерживающие и ISL, и 802.1q, получили название PVSTP+ и RPVSTP+. Теперь они являются индустриальными стандартами для сетей Cisco.
Процесс STP характеризуется показателем стоимости пути на каждом порту Port Cost. В качестве основы для этого показателя использовалась характеристика Port Speed – скорость порта в мб/с. Так, по стандарту IEEE 1998 скорости 10 Мб/с соответствовала стоимость порта 100, скорости 100 Мб/с – стоимость 19, 1 Гб/с – стоимость 4 и 10 Гб/с – стоимость 2. Этот стандарт не учитывал скорости 100 Гб/с и 1 Тб/с, поэтому в 2004 году был разработан новый IEEE, где относительный показатель стоимости порта изменяется от 2 миллионов до 20.

Чем больше скорость, тем меньше стоимость, поэтому при расчете маршрутов выбираются порты с меньшей стоимостью. Если имеются две линии – FastEthernet и GigabitEthernet, то последняя линия связи будет иметь намного меньшую стоимость, поэтому при выборе маршрута к корневому свитчу порт GigabitEthern будет иметь приоритет. Сам корневой свитч имеет нулевую стоимость порта. В следующем видео мы рассмотрим процесс выбора маршрута, так что вам многое станет понятным. Пока что просто запомните, каков принцип определения стоимости.
Следующая тема – это идентификатор отправителя Bridge ID. В STP он содержит 2 байта информации о приоритете свитча и 6 байтов MAC-адреса.
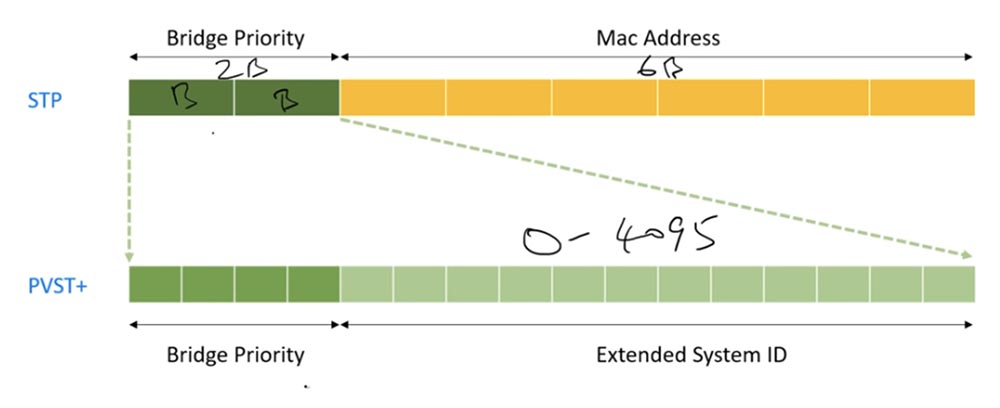
Более продвинутый PVSTP состоит из 16 бит. Первые 12 бит носят название Extended System ID, или расширенный системный идентификатор. В нем размещаетсяразмещается идентификатор сети VLAN — номер сети в диапазоне 0-4095, и MAC-адрес. Еще 4 бита служат для обозначения приоритета моста, или свитча. Если вы вспомните нашу магическую бинарную таблицу, то увидите, что если все 4 бита равны 0, то мы получим нулевой приоритет.
Если биты будут расположены в порядке 0001, это означает, что под 1 располагается число 4096, то есть приоритет будет равен 4096. В зависимости от 16 комбинаций бит, в качестве приоритета будет использовано одно из этих чисел – от 0 до 61440, причем каждое последующее больше предыдущего на 4096.
По умолчанию все свитчи Cisco имеют приоритет 32768, но вы можете выбрать в качестве приоритета любое из этих чисел. При использовании Extended System ID к этому числу добавляется номер сети VLAN, то есть если у вас имеется VLAN1, приоритет Bridge ID составит 32768+1= 32769.

У нас также имеется MAC-адрес. Предположим, что Bridge ID одного устройства равен 32769: ААА: ААА: ААА, а другого — 32769: ВВВ: ВВВ: ВВВ. Числовое значение приоритета у них равно, но преимущество будет за устройством с меньшим MAC-адресом, то есть за ААА: ААА: ААА. Для того, чтобы лучше понять, как работает Bridge ID, вы можете пересмотреть это видео ещё раз.
Мы не можем изменить MAC-адрес второго устройства, но можем изменить числовое значение приоритета 32769. Если нужно, чтобы это устройство обладало большим приоритетом, можно поменять значение приоритета на 0 или любое число, меньшее 32769. Если мы возьмем 0 и номер сети VLAN1, то получим числовое значение приоритета 1. В этом случае независимо от значения MAC-адреса это устройство будет иметь больший приоритет, чем первое.
Если вы захотите скачать это видео с нашего сайта, можете воспользоваться купоном на 50% скидку, которая действует до конца 22 ноября 2017 года. Напоминаю, что сегодня мы рассмотрели очень важную тему, поэтому советую просмотреть этот видеоурок ещё раз.
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас оформив заказ или порекомендовав знакомым, 30% скидка для пользователей Хабра на уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps от $20 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?
Вы тоже можете настроить свой десктоп подобным образом, если воспользуетесь ссылкой в правом верхнем углу этого видео. И пожалуйста, не забывайте «лайкать» и делиться с друзьями моими видеоуроками.
Как и в прошлый раз, сегодня мы обсудим очередную тему согласно расписанию ICND2, представленному на сайте Cisco. Это раздел 1.3 «Настройка, проверка и неполадки протоколов STP», подпункт 1.3а «Режимы STP (PVST+ и RPVST+)» и 1.3b «Выбор корневого свитча STP (Root bridge)».
Поскольку это обширная тема, я перенес рассмотрение подраздела 1.3b на следующий урок «День 37», туда же я добавлю раздел 1.4. Итак, сегодня мы рассмотрим, что представляет собой STP, изучим режимы этого протокола PVST+ и RPVST+, а затем рассмотрим идентификатор корневого свитча Bridge ID и стоимость маршрута до корневого порта Port Cost.
Для начала нам нужно понять, что собой представляет петля коммутации, возникающая на 2 уровне модели OSI (на уровне фреймов), и какие проблемы с ней связаны. Мы уже обсуждали зацикливание трафика в одной из предыдущих серий, и тот урок можно считать введением в сегодняшнюю тему. Приведу пример: у нас имеется свитч А и свитч В, соединенные друг с другом двумя линиями связи, первого пользователя зовут Джо, а второго – Джим.
Если Джо отсылает сообщение Джиму, то он отправляет фрейм свитчу А. Свитч А не знает MAC-адрес Джима, поэтому он отправляет бродкаст-фрейм через все порты, кроме того, через который поступило сообщение Джо. Когда бродкаст-фрейм принимается портами свитча В, то пакет, пришедший по одному интерфейсу, отсылается Джиму, а пакет, пришедший по второму интерфейсу, переадресуется на первый порт и отправляется обратно свитчу А.
В то же время запрос, пришедший по первому интерфейсу, переадресовывается второму порту и тоже отправляется свитчу А.
Получив эти бродкаст-фреймы, свитч А отсылает их обратно: фрейм, поступивший по первому интерфейсу, отсылается по второму, а поступивший по второму отправляется в сеть через первый интерфейс. Этот процесс повторяется снова и снова, образуя петлю широковещательных запросов. Если в сеть поступает другой бродкаст, он точно так же зацикливается вместе с первым. В результате возникает явление, получившее название Broadcast storm, или широковещательный шторм. Сеть наводняет такое количество бродкаст-фреймов, что она выходит из строя. Этот шторм может прекратиться только тогда, когда отключится одно из устройств или соединение разорвется. Если линия останется работоспособной, то вскоре после начала такого шторма один из свитчей прекратит работу из-за переполнения памяти. Во втором случае петля может возникнуть по причине пересылки фрейма с юникастовым MAC-адресом. Эта проблема носит название «нестабильности таблицы MAC-адресов». Она происходит, когда между свитчами имеется более двух соединений. Я нарисую схему, в которой свитчи А, В и С соединены друг с другом и между ними тоже может образоваться петля.
Свитч А имеет три интерфейса: f0/1, f0/2 и f0/3. Предположим, что пользователь имеет компьютер с MAC-адресом ААА и отправляет бродкаст-фрейм свитчу А. Свитч принимает этот фрейм через интерфейс f0/1. В сети есть еще один пользователь, компьютер которого имеет MAC-адрес ВВВ. Таким образом, у нас имеется адрес источника ААА и адрес назначения ВВВ.
Свитч А не знает, как добраться до MAC-адреса назначения BBB, но зато знает, что до MAC-адреса источника ААА можно добраться через интерфейс f0/1 и помещает запись об этом в свою таблицу MAC-адресов. Далее свитч А рассылает запрос об адресе назначения по двум остальным интерфейсам — f0/2 и f0/3.
Получив запрос ААА, свитч В видит, что он пришел из источника f0/2 и помещает в свою таблицу MAC-адресов запись, что устройство ААА достижимо через интерфейс f0/2. Кроме того, у него уже есть запись, что назначению BBB соответствует интерфейс f0/1, поэтому он отсылает запрос адресату.
Поскольку свитч А выслал бродкаст-фрейм, тот отправился не только через интерфейс f0/2 к свитчу B, но и через интерфейс f0/3 к свитчу С, который, в свою очередь, переслал его интерфейсу f0/3 свитча В.
Получив фрейм, свитч В думает так: «я знаю, что источник ААА ранее располагался на интерфейсе f0/2, но сейчас фрейм от него пришел ко мне через интерфейс f0/3, значит, я должен обновить свою таблицу MAC-адресов и заменить f0/2 на f0/3».
Далее фрейм отправится обратно к свитчу А и очень его «удивит»: раньше свитч А думал, что источник ААА соединен интерфейсом f0/1, а теперь выясняется, что сообщение от него пришло с интерфейса f0/2. При обратном направлении фрейма через свитч В и С свитч А получит сообщение, которое смутит его еще раз – теперь получается, что источник ААА расположен на интерфейсе f0/3.
Таким образом, таблица MAC-адресов этого свитча постоянно будет обновляться между этими тремя интерфейсами, то есть возникнет вышеупомянутая проблема нестабильности таблицы MAC-адресов. Как и в первом случае, здесь образуется петля фреймов, приводящая к обновлению таблицы каждые несколько секунд.
Существует и третья проблема зацикливания – множественные копии фрейма. Пользователь ААА отправляет фрейм свитчу А, то отправляет его через интерфейс f0/2 свитчу В, который доставляет его назначению BBB через интерфейс f0/1. Здесь не возникает никаких проблем.
Но одновременно свитч А отправляет этот же фрейм через свой второй интерфейс f0/3 свитчу С, который пересылает его свитчу B. Получив пакет, или фрейм, от свитча С, свитч В видит, что он адресован BBB, и отправляет его адресату. Таким образом, пользователь BBB дважды получает один и тот же пакет. Здесь возникает проблема – если это рассылка данных, совершаемых приложением, то один и тот же фрейм не должен приходить пользователю два раза.
Таковы три проблемы, которые могут быть вызваны петлями фреймов. Все они решаются одним способом, о котором мы говорили ранее – использованием протокола STP. В одном из предыдущих видео, не помню его номер, когда мы обсуждали режимы портов, уже говорилось об этом протоколе, который служит для предотвращения образования петель трафика в сети.
Итак, петля образуется, когда три устройства соединены друг с другом, образуя замкнутый контур сети, и принадлежат одному широковещательному домену. Для такого случая алгоритм, используемый протоколом STP, назначает один из свитчей корневым коммутатором — Root Bridge. Давайте выберем в качестве корневого коммутатора свитч А.
Каждый порт, подключенный к корневому свитчу, должен быть в состоянии передачи Forwarding, это левые порты свитча C и B. Эти порты обеспечивают передачу пакетов, или фреймов, в направлении корневого свитча А. По линии соединения свитчей С и В один из портов должен быть в состоянии блокировки Blocking.
Это означает, что он не отсылает трафик. Свитч В может продолжать отсылать трафик свитчу С, но его правый порт не будет обрабатывать этот трафик, хотя физически будет продолжать работать. Это осуществляется при помощи идентификатора моста, или идентификатора свитча BID – Bridge ID.
Вы должны помнить, что протокол STP был создан задолго до того, как появились Ethernet-свитчи. Тогда вместо термина switch – коммутатор использовался термин bridge – мост, и многие протоколы до сих пор используют классическую терминологию технических стандартов. Так что сейчас BID – это идентификатор свитча.
Информация, которой корневой свитч обменивается с другими свитчами, называется BPDU. Устройства обмениваются сообщениями BPDU каждые 2 секунды – это время носит название «таймер hello». Сообщение BPDU содержит идентификатор корневого свитча BID и стоимость маршрута до корневого свитча, или Root Path Cost (фактически это расстояние до корневого свитча). Стоимость пути на каждом порту служит для вычисления кратчайшего пути до корневого свитча, но мы не будем углубляться в данное понятие.
Логически схема работает так: благодаря заблокированному правому порту свитча С трафик, идущий в направлении свитч А – свитч В – свитч С не поступает свитчу А, то есть не замыкается в петлю. С направляет трафик А, тот отправляет его В, свитч В направляет его С, и в этом месте петля разрывается.
Вот как работает протокол STP, который является стандартом IEEE 802.1d. Это очень старый стандарт, недостатком которого является максимальное время обновления информации при обрыве связи, равное 50 секундам. Кроме состояния блокировки порта Blocking, он поддерживает ещё 2 промежуточных состояния — Listening (Прослушивание) и Learning (Обучение — подготовка к пересылке), после которых переходит к состоянию передачи Forwarding.
Каждые 2 секунды свитчи обмениваются сообщением hello – C посылает его В и А, А посылает hello C и В и так далее. Если какое устройство не получает этого сообщения, оно ожидает его еще в течение 10-ти кратного периода таймера hello, то есть 20 секунд. После этого оно ожидает какого-либо действия, перейдя в состояние Listening, которое длится 15 секунд, затем переходит в состояние Learning и пребывает в нем ещё 15 с. Таким образом, общий период бездействия составляет 50с. Для современных сетей это достаточно длительный промежуток времени.
Для улучшения этой ситуации был введен другой стандарт — IEEE 802.1w, или Rapid STP – быстрый протокол STP, обозначаемый как RSTP. Он лишен промежуточных состояний и переходит из состояния Blocking к состоянию Forwarding.
В STP существуют корневые порты Root Port – это порты, через которые осуществляется связь с корневым свитчем. В RSTP добавлено понятие альтернативных портов Alternative Port, не связанных с корневым свитчем. В случае, если между корневым портом RP и корневым свитчем происходит обрыв связи, альтернативный порт ALT сразу превращается в корневой порт RP, и связь осуществляется по другому маршруту.
При самом сложном развитии событий весь этот процесс занимает максимум 10 с, а 10 с бездействия намного лучше, чем 50 секунд. Вот в чем состоит основная разница между STP и RSTP.
Сейчас Cisco использует STP различными способами, но первоначально он предназначался для работы в одном широковещательном домене с Native VLAN, поэтому STP воспринимался как часть VLAN1. При этом считалось, что весь трафик является частью этого единого широковещательного домена. По мере развития сетевых устройств Cisco стала использовать STP другими способами, создав PVSTP (Per-VLAN Spanning Tree), проприетарный протокол, предназначенный для работы с несколькими VLAN. Это означало, что каждая VLAN будет иметь свой STP, то есть свой собственный корневой свитч Root Bridge.
Точно так же, как Cisco усовершенствовала STP, создав RSTP, она разработала «ускоренную» версию PVSTP – RPVSTP. Оба эти протокола осуществляли инкапсуляцию по проприетарному протоколу ISL и не поддерживали стандарт 802.1q, поскольку были разработаны еще до его принятия. Для обеспечения совместимости стандартов Cisco усовершенствовала эти протоколы, добавив в них поддержку 802.1q. Новые протоколы, поддерживающие и ISL, и 802.1q, получили название PVSTP+ и RPVSTP+. Теперь они являются индустриальными стандартами для сетей Cisco.
Процесс STP характеризуется показателем стоимости пути на каждом порту Port Cost. В качестве основы для этого показателя использовалась характеристика Port Speed – скорость порта в мб/с. Так, по стандарту IEEE 1998 скорости 10 Мб/с соответствовала стоимость порта 100, скорости 100 Мб/с – стоимость 19, 1 Гб/с – стоимость 4 и 10 Гб/с – стоимость 2. Этот стандарт не учитывал скорости 100 Гб/с и 1 Тб/с, поэтому в 2004 году был разработан новый IEEE, где относительный показатель стоимости порта изменяется от 2 миллионов до 20.
Чем больше скорость, тем меньше стоимость, поэтому при расчете маршрутов выбираются порты с меньшей стоимостью. Если имеются две линии – FastEthernet и GigabitEthernet, то последняя линия связи будет иметь намного меньшую стоимость, поэтому при выборе маршрута к корневому свитчу порт GigabitEthern будет иметь приоритет. Сам корневой свитч имеет нулевую стоимость порта. В следующем видео мы рассмотрим процесс выбора маршрута, так что вам многое станет понятным. Пока что просто запомните, каков принцип определения стоимости.
Следующая тема – это идентификатор отправителя Bridge ID. В STP он содержит 2 байта информации о приоритете свитча и 6 байтов MAC-адреса.
Более продвинутый PVSTP состоит из 16 бит. Первые 12 бит носят название Extended System ID, или расширенный системный идентификатор. В нем размещаетсяразмещается идентификатор сети VLAN — номер сети в диапазоне 0-4095, и MAC-адрес. Еще 4 бита служат для обозначения приоритета моста, или свитча. Если вы вспомните нашу магическую бинарную таблицу, то увидите, что если все 4 бита равны 0, то мы получим нулевой приоритет.
Если биты будут расположены в порядке 0001, это означает, что под 1 располагается число 4096, то есть приоритет будет равен 4096. В зависимости от 16 комбинаций бит, в качестве приоритета будет использовано одно из этих чисел – от 0 до 61440, причем каждое последующее больше предыдущего на 4096.
По умолчанию все свитчи Cisco имеют приоритет 32768, но вы можете выбрать в качестве приоритета любое из этих чисел. При использовании Extended System ID к этому числу добавляется номер сети VLAN, то есть если у вас имеется VLAN1, приоритет Bridge ID составит 32768+1= 32769.
У нас также имеется MAC-адрес. Предположим, что Bridge ID одного устройства равен 32769: ААА: ААА: ААА, а другого — 32769: ВВВ: ВВВ: ВВВ. Числовое значение приоритета у них равно, но преимущество будет за устройством с меньшим MAC-адресом, то есть за ААА: ААА: ААА. Для того, чтобы лучше понять, как работает Bridge ID, вы можете пересмотреть это видео ещё раз.
Мы не можем изменить MAC-адрес второго устройства, но можем изменить числовое значение приоритета 32769. Если нужно, чтобы это устройство обладало большим приоритетом, можно поменять значение приоритета на 0 или любое число, меньшее 32769. Если мы возьмем 0 и номер сети VLAN1, то получим числовое значение приоритета 1. В этом случае независимо от значения MAC-адреса это устройство будет иметь больший приоритет, чем первое.
Если вы захотите скачать это видео с нашего сайта, можете воспользоваться купоном на 50% скидку, которая действует до конца 22 ноября 2017 года. Напоминаю, что сегодня мы рассмотрели очень важную тему, поэтому советую просмотреть этот видеоурок ещё раз.
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас оформив заказ или порекомендовав знакомым, 30% скидка для пользователей Хабра на уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps от $20 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?




