

Для полного освоения Kubernetes нужно знать различные способы масштабирования кластерных ресурсов: по словам разработчиков системы, это одна из главных задач Kubernetes. Мы подготовили высокоуровневый обзор механизмов горизонтального и вертикального автомасштабирования и изменения размера кластеров, а также рекомендации, как их эффективно использовать.
Статью Kubernetes Autoscaling 101: Cluster Autoscaler, Horizontal Autoscaler, and Vertical Pod Autoscaler перевела команда, которая реализовала автомасштабирование в Kubernetes aaS от Mail.ru.
Почему важно подумать о масштабировании
Kubernetes — инструмент для управления ресурсами и оркестровки. Конечно, неплохо повозиться с классными функциями развертывания, мониторинга и управления подами (модуль pod — группа контейнеров, запускаемых в ответ на запрос).
Однако следует подумать и о таких вопросах:
- Как масштабировать модули и приложения?
- Как поддерживать контейнеры в рабочем и эффективном состоянии?
- Как реагировать на постоянные изменения в коде и рабочих нагрузках от пользователей?
Настройка кластеров Kubernetes для балансировки ресурсов и производительности может быть сложной задачей, она требует экспертных знаний о внутренней работе Kubernetes. Рабочая нагрузка на ваше приложение или сервисы может колебаться в течение дня или даже одного часа, поэтому балансировку лучше представлять как непрерывный процесс.
Уровни автомасштабирования Kubernetes
Эффективное автомасштабирование требует координации между двумя уровнями:
- Уровень pod'ов, включающий горизонтальное (Horizontal Pod Autoscaler, HPA) и вертикальное автомасштабирование (Vertical Pod Autoscaler, VPA). Это масштабирование имеющихся ресурсов для ваших контейнеров.
- Уровень кластера, которым управляет система автомасштабирования кластера (Cluster Autoscaler, CA), она увеличивает или уменьшает количество узлов внутри кластера.
Модуль горизонтального автомасштабирования (HPA)
Как следует из названия, HPA масштабирует количество реплик pod'ов. В качестве триггеров для изменения количества реплик большинство девопсов используют нагрузку на процессор и память. Однако можно масштабировать систему на основе пользовательских метрик, их сочетания или даже внешних метрик.
Высокоуровневая схема работы HPA:
- HPA непрерывно проверяет значения метрик, указанные при установке, с интервалом по умолчанию 30 секунд.
- HPA пытается увеличить количество модулей, если достигнут заданный порог.
- HPA обновляет количество реплик внутри контроллера развертывания/репликации.
- Контроллер развертывания/репликации затем разворачивает все необходимые дополнительные модули.
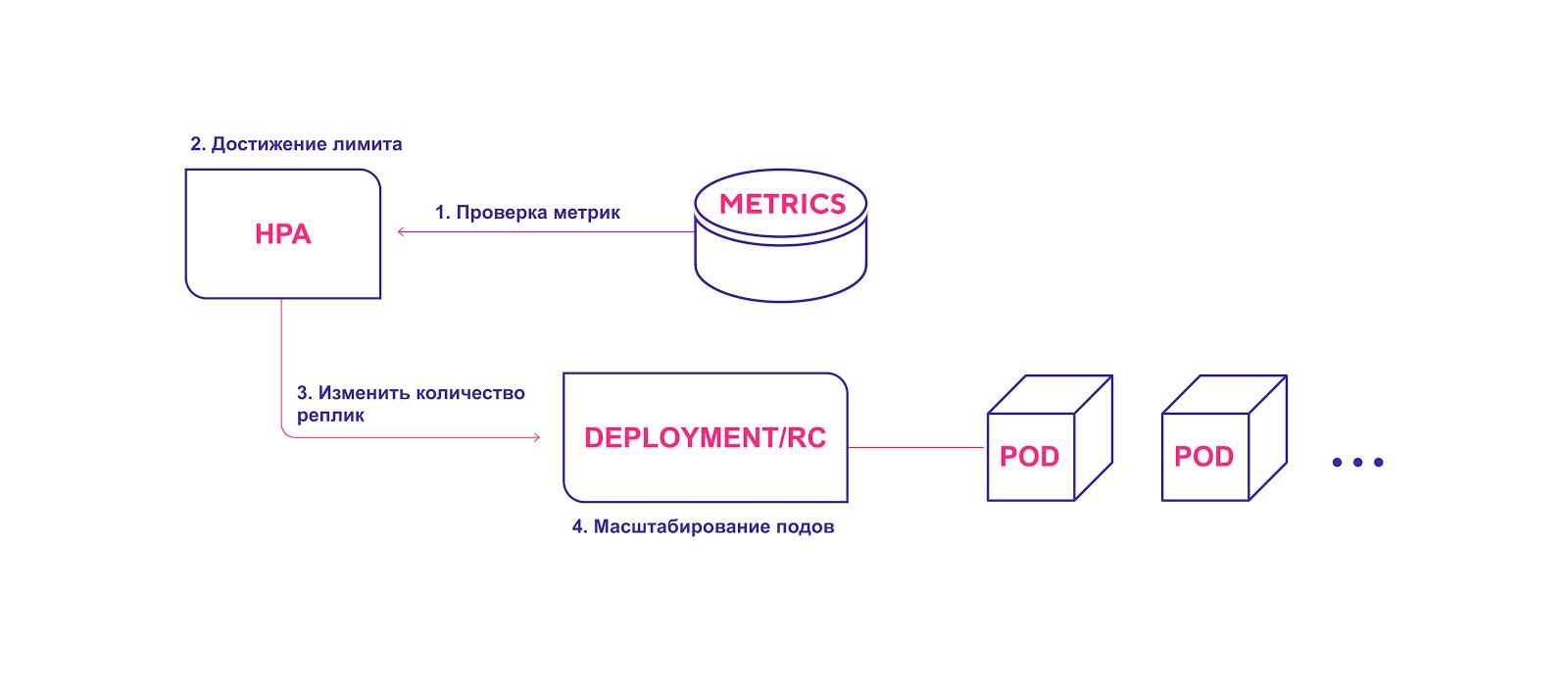
HPA запускает процесс развертывания модулей при достижении порогового значения метрик
При использовании HPA учитывайте следующее:
- Интервал проверки HPA по умолчанию составляет 30 секунд. Он устанавливается флагом horizontal-pod-autoscaler-sync-period в диспетчере контроллера.
- Относительная погрешность по умолчанию составляет 10%.
- После последнего увеличения количества модулей HPA ожидает стабилизации метрик в течение трех минут. Этот интервал устанавливается флагом horizontal-pod-autoscaler-upscale-delay.
- После последнего уменьшения количества модулей HPA ожидает стабилизации в течение пяти минут. Этот интервал устанавливается флагом horizontal-pod-autoscaler-downscale-delay.
- HPA лучше всего работает с объектами развертывания, а не с контроллерами репликации. Горизонтальное автомасштабирование несовместимо с последовательным обновлением (rolling update), которое напрямую манипулирует контроллерами репликации. При деплое количество реплик зависит непосредственно от объектов развертывания.
Вертикальное автомасштабирование pod'ов
Вертикальное автомасштабирование (VPA) выделяет больше (или меньше) времени процессора или памяти для существующих pod'ов. Подходит для pod'ов с сохранением состояния (stateful) или без него (stateless), но в основном предназначено для stateful-сервисов. Впрочем, вы можете применить VPA и для модулей без сохранения состояния, если нужно автоматически скорректировать объем изначально выделенных ресурсов.
VPA также реагирует на события OOM (out of memory, недостаточно памяти). Для изменения процессорного времени и объема памяти требуется перезапуск pod'ов. При перезапуске VPA соблюдает бюджет распределения (pods distribution budget, PDB), чтобы гарантировать минимально необходимое количество модулей.
Вы можете установить минимальный и максимальный объем ресурсов для каждого модуля. Так, можно ограничить максимальный объем выделяемой памяти пределом в 8 ГБ. Это полезно, если текущие узлы точно не могут выделить более 8 ГБ памяти на контейнер. Подробные спецификации и механизм работы описаны в официальном вики VPA.
Кроме того, у VPA есть интересная функция рекомендаций (VPA Recommender). Она отслеживает использование ресурсов и события OOM всех модулей, чтобы предложить новые значения памяти и процессорного времени на основе интеллектуального алгоритма с учетом исторических метрик. Также есть API-интерфейс, который принимает дескриптор pod и отдает предлагаемые значения ресурсов.
Стоит отметить, что VPA Recommender не отслеживает «лимит» ресурсов. Это может привести к тому, что модуль монополизирует ресурсы внутри узлов. Лучше установить предельное значение на уровне пространства имен, чтобы избежать огромного расхода памяти или процессорного времени.
Высокоуровневая схема работы VPA:
- VPA непрерывно проверяет значения метрик, указанные при установке, с интервалом по умолчанию 10 секунд.
- Если достигнут заданный порог, VPA пытается изменить выделенное количество ресурсов.
- VPA обновляет количество ресурсов внутри контроллера развертывания/репликации.
- При перезапуске модулей все новые ресурсы применяются к созданным инстансам.
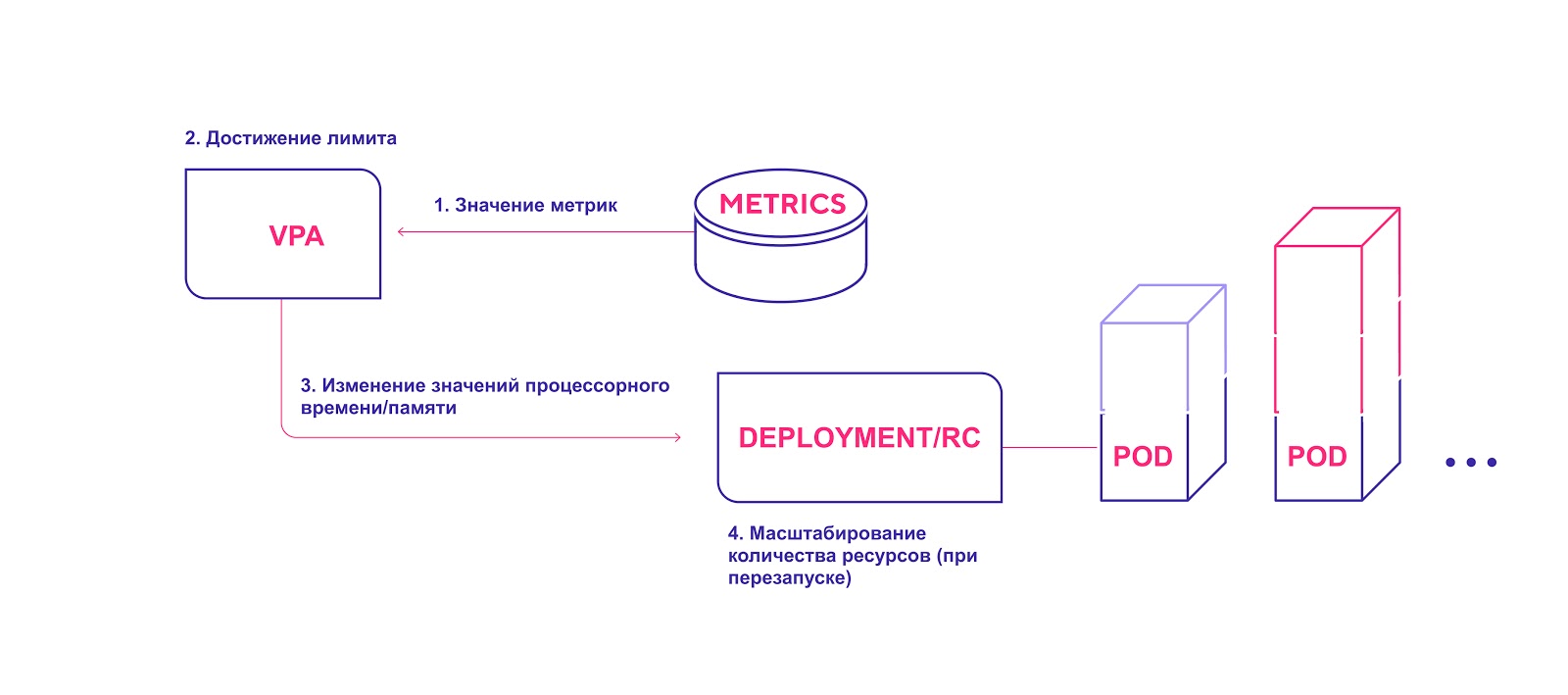
VPA добавляет необходимое количество ресурсов
Учитывайте следующие моменты при использовании VPA:
- Масштабирование требует обязательного перезапуска pod'а. Это нужно, чтобы избежать нестабильной работы после внесения изменений. Для надежности модули перезапускают и распределяют по узлам на основе новых выделенных ресурсов.
- VPA и HPA пока несовместимы друг с другом и не могут работать на одних и тех же pod'ах. Если вы применяете в одном кластере оба механизма масштабирования, убедитесь, что настройки не позволят им активироваться на одних и тех же объектах.
- VPA настраивает запросы контейнеров на ресурсы, исходя только из прошлого и текущего их использования. Он не устанавливает лимиты использования ресурсов. Могут возникнуть проблемы с некорректной работой приложений, которые начнут захватывать все больше ресурсов, это приведет к тому, что Kubernetes выключит данный pod.
- VPA пока на ранней стадии разработки. Будьте готовы, что в ближайшее время система может претерпеть некоторые изменения. Можно почитать об известных ограничениях и планах разработки. Так, в планах реализовать совместную работу VPA и HPA, а также развертывание модулей вместе с политикой вертикального автомасштабирования для них (например, специальная метка 'requires VPA').
Автомасштабирование кластера Kubernetes
Автомасштабирование кластера (Cluster Autoscaler, CA) изменяет количество узлов, исходя из количества ожидающих модулей pod. Система периодически проверяет наличие ожидающих модулей — и увеличивает размер кластера, если требуется больше ресурсов и если кластер не выходит за пределы установленных лимитов. CA взаимодействует с поставщиком облачных услуг, запрашивает у него дополнительные узлы или освобождает бездействующие. Первая общедоступная версия CA была представлена в Kubernetes 1.8.
Высокоуровневая схема работы СA:
- CA проверяет наличие модулей в состоянии ожидания с интервалом по умолчанию 10 секунд.
- Если один или несколько модулей находятся в состоянии ожидания из-за того, что в кластере недостаточно доступных ресурсов для их распределения, он пытается подготовить один или несколько дополнительных узлов.
- Когда поставщик облачных услуг выделяет необходимый узел, тот присоединяется к кластеру и готов обслуживать модули pod.
- Планировщик Kubernetes распределяет ожидающие модули на новый узел. Если после этого некоторые модули все равно остаются в состоянии ожидания, процесс повторяется — и в кластер добавляются новые узлы.
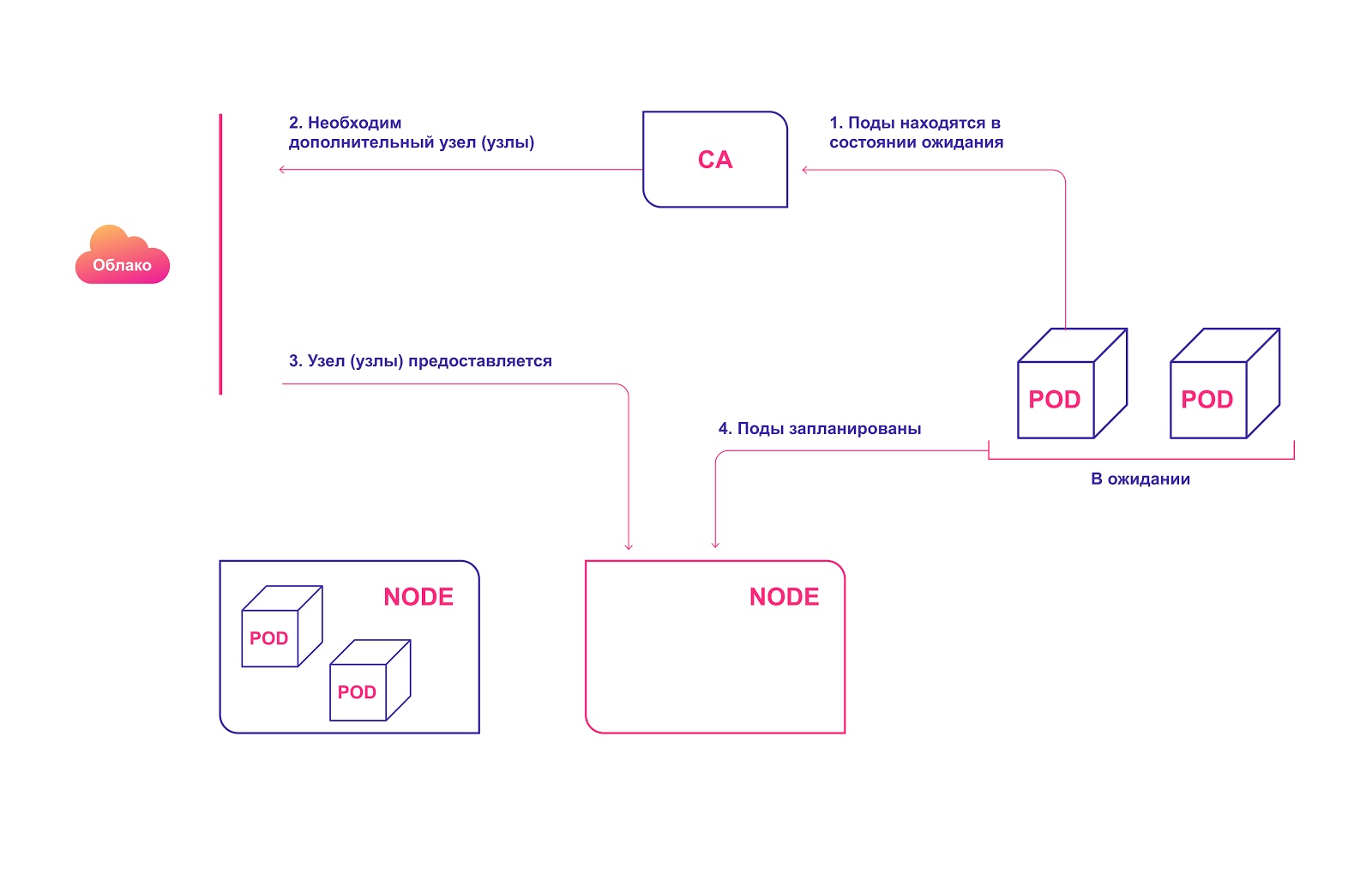
Автоматическое выделение узлов кластера в облаке
Учитывайте следующее при использовании СA:
- CA гарантирует, что у всех модулей в кластере есть место для запуска, независимо от уровня нагрузки на процессор. Кроме того, он пытается гарантировать, что в кластере нет ненужных узлов.
- CA регистрирует необходимость масштабирования примерно через 30 секунд.
- После того как узел становится ненужным, CA по умолчанию ожидает 10 минут, прежде чем масштабировать систему.
- В системе автомасштабирования есть понятие расширителей (expanders). Это различные стратегии для выбора группы узлов, в которую будут добавлены новые.
- Ответственно применяйте опцию cluster-autoscaler.kubernetes.io/safe-to-evict (true). Если установить много pod'ов или если многие из них будут разбросаны по всем узлам, вы в значительной степени потеряете возможность уменьшать масштаб кластера.
- Используйте PodDisruptionBudgets, чтобы предотвратить удаление pod'ов, из-за чего часть вашего приложения может полностью выйти из строя.
Как системы автомасштабирования Kubernetes взаимодействуют между собой
Для идеальной гармонии следует применить автомасштабирование и на уровне pod'ов (HPA/VPA), и на уровне кластера. Они относительно просто взаимодействуют между собой:
- HPA или VPA обновляют реплики pod'ов или ресурсы, выделенные для существующих pod'ов.
- Если для запланированного масштабирования не хватает узлов, CA замечает наличие pod'ов в состоянии ожидания.
- CA выделяет новые узлы.
- Модули распределяются по новым узлам.
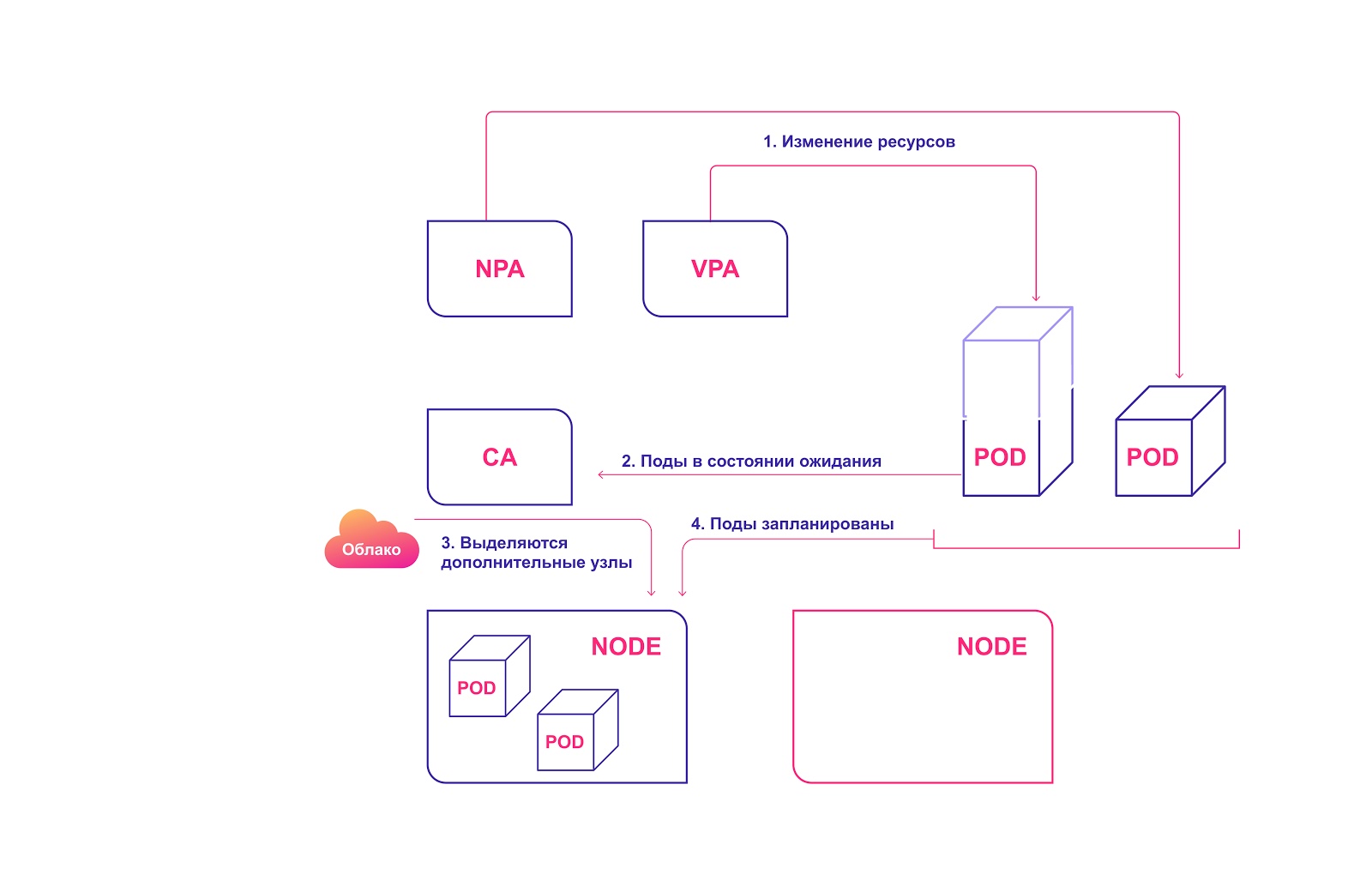
Совместная система систем масштабирования Kubernetes
Типичные ошибки в автомасштабировании Kubernetes
Существует несколько типичных проблем, с которыми девопсы сталкиваются, когда пытаются применить автомасштабирование.
HPA и VPA зависят от метрик и некоторых исторических данных. Если выделено недостаточно ресурсов, модули будут свернуты и не смогут генерировать метрики. В этом случае автомасштабирование никогда не состоится.
Сама операция масштабирования чувствительна ко времени. Нам хочется, чтобы модули и кластер масштабировались быстро — до того, как пользователи заметят какие-то проблемы и сбои. Поэтому следует учитывать среднее время масштабирования pod'ов и кластера.
Идеальный сценарий — 4 минуты:
- 30 секунд. Обновление целевых метрик: 30−60 секунд.
- 30 секунд. HPA проверяет значения метрик: 30 секунд.
- Менее 2 секунд. Модули pod созданы и переходят в состояние ожидания: 1 секунда.
- Менее 2 секунд. CA видит ожидающие модули и отправляет вызовы на подготовку узлов: 1 секунда.
- 3 минуты. Облачный провайдер выделяет узлы. K8s ждет, пока они не будут готовы: до 10 минут (зависит от нескольких факторов).
Худший (более реалистичный) сценарий — 12 минут:
- 30 секунд. Обновление целевых метрик.
- 30 секунд. HPA проверяет значения метрик.
- Менее 2 секунд. Модули pod созданы и переходят в состояние ожидания.
- Менее 2 секунд. CA видит ожидающие модули и отправляет вызовы на подготовку узлов.
- 10 минут. Облачный провайдер выделяет узлы. K8s ждет, пока они не будут готовы. Время ожидания зависит от нескольких факторов, таких как задержка поставщика, задержка ОС, работа вспомогательных инструментов.
Не путайте механизмы масштабирования облачных провайдеров с нашей CA. Последняя работает внутри кластера Kubernetes, в то время как механизм облачного провайдера работает на основе распределения узлов. Он не знает, что происходит с вашими pod'ами или приложением. Эти системы работают параллельно.
Как управлять масштабированием в Kubernetes
- Kubernetes — инструмент управления ресурсами и оркестровки. Операции по управлению pod'ами и ресурсами кластера — ключевая веха в освоении Kubernetes.
- Усвойте логику масштабируемости pod'ов с учетом HPA и VPA.
- CA стоит использовать, только если вы хорошо понимаете потребности своих pod'ов и контейнеров.
- Для оптимальной настройки кластера нужно понять, как различные системы масштабирования работают вместе.
- При оценке времени масштабирования имейте в виду худший и лучший сценарии.



 vs Rancher Longhorn vs StorageOS vs Robin vs Portworx vs Linstor")
