
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Стандарт JPEG появился в 1992 году. С тех пор JPEG-изображения оказались неразрывно связаны с цифровой фотографией, они используются практически в каждом приложении, которое работает с изображениями фотографического качества. Причина того, что стандарт JPEG был так быстро принят всем миром, того, что он стал практически универсальным способом хранения изображений, заключается в том, что в нём одновременно используется несколько подходов к сжатию изображений. Один из этих подходов основан на понимании ограничений системы зрительного восприятия информации человеком, и того, какую информацию, наиболее важную, нужно сохранить, а от какой, менее важной, можно избавиться.

Процесс сжатия изображений с использованием метода JPEG требует выполнения нескольких шагов (ниже приведена соответствующая схема). Обычно изображение сначала преобразуется из цветового пространства RGB в цветовое пространство YCbCR. Причина необходимости этого шага заключается в том, чтобы сделать возможным субсэмплинг пикселей. Человеческий глаз более чувствителен к изменениям яркости, чем к изменениям цветности. Это позволяет произвести даунсэмплинг цветового канала, но сохранить канал яркости в полном разрешении. На этом шаге изображение может потерять 50% данных, а видимое ухудшение его качества будет минимальным. Затем изображение делится на блоки размером 8x8 пикселей (их называют MCU, Minimal Coding Unit, минимальная единица кодирования). В кодировании видео аналогом MCU являются макроблоки (Macroblock). Итак, MCU — это квадратные блоки пикселей, сжатие информации о которых выполняется на основании сведений об их схожести друг с другом. Сведения о пикселях каждого MCU переводятся из пространственной области в частотную область с использованием дискретного косинусного преобразования (Discrete Cosine Transformation, DCT). Благодаря выполнению этой операции можно легко избавиться от высокочастотной информации (мелких деталей) для ещё более сильного сжатия изображения. Чем больше высокочастотных компонентов убирают — тем меньше будет файл и тем ниже будет качество изображения. Для управления этим аспектом кодирования применяется опция Q (уровень сжатия), используемая программами для JPEG-кодирования.

Обработка изображения при JPEG-кодировании
Одна из многих разумных идей, включённая в стандарт, заключается в использовании схожести значения DC (яркости) между находящимися рядом друг с другом MCU. Это позволяет добиться дальнейшего сокращения размера файла изображения за счёт того, что кодируются лишь изменения значений, а не сами эти значения. На вышеприведённой схеме этот процесс представлен блоком DPCM coding. Это — отличная идея, но она создаёт одну небольшую проблему. Если значение DC для каждого MCU зависит от значения для предыдущего MCU, представляющего собой разницу значений, это значит, что если в данных некоего MCU будет ошибка — это повлияет на все MCU, идущие за ним.
Ситуацию ещё немного усугубляет то, что сжатые символы, кодирующие данные изображения (выше это представлено блоком Huffman coding) — это коды переменной длины (Variable Length Codes, VLC). Всего один неправильный бит может повредить все данные, расположенные в месте повреждения и дальше. В те давние времена, когда был изобретён формат JPEG, это было совершенно реальной проблемой, так как изображения часто передавались по каналам, которые могли не обладать надёжными механизмами коррекции ошибок (вроде соединений, создаваемых с помощью акустических модемов). Изображения, кроме того, хранились на носителях (вроде дискет), информация, записанная на которые, легко могла быть повреждена. Знание о том, что графическая информация, хранимая в JPEG-файлах, может пострадать из-за ошибок, привело к тому, что в стандарт добавили механизм, ограничивающий масштабы повреждения изображений. В основе этого механизма лежит идея о периодическом сбросе предыдущего значения DC в 0, что приводило к тому, что значение для следующего MCU должно было вычисляться в виде его разницы с 0. Это означало, что повреждённые значения DC влияли лишь на пиксели, расположенные до следующей «точки рестарта».
Реализована эта возможность с использованием рестарт-маркеров (Restart Marker). Речь идёт о 2-байтовых маркерах, расположенных между MCU с регулярным интервалом (например — через каждые 100 MCU). Если данные оказываются повреждёнными — несложно найти следующий рестарт-маркер (JPEG-маркеры всегда находятся на границах байтов, им предшествует значение 0xFF). После нахождения позиции следующего рестарт-маркера изображение может быть правильно декодировано начиная с этой позиции, так как известно количество MCU между такими маркерами.
После выпуска стандарта JPEG компьютерные сети и хранилища данных становились всё надёжнее, в них применялись системы обнаружения и коррекции ошибок (например — TCP/IP). Твердотельные накопители, используемые в цифровых фотоаппаратах, были достаточно надёжными и о рестарт-маркерах на какое-то время «забыли», так как они увеличивали размеры файлов не давая взамен никаких заметных преимуществ. В это время программное обеспечение создавалось, в основном, в расчёте на выполнение на одном процессоре с использованием одного потока. Тот факт, что JPEG-изображения нужно было декодировать за один проход, что было нужно из-за использования кодов переменной длины и данных об изменениях значений для MCU, не вызывал каких-либо проблем для программ, так как они, в любом случае, создавались в расчёте на однопоточный режим.
Правда, в последние годы произошли огромные изменения в компьютерах, и в том, как мы пользуемся JPEG-файлами. Практически каждое вычислительное устройство обладает несколькими CPU и работает под управлением операционной системы, поддерживающей несколько потоков (сюда входят даже телефоны). Другие изменения заключаются в том, что люди снимают, редактируют и просматривают миллиарды JPEG-фотографий на своих телефонах. Каждое новое поколение телефонов позволяет создавать фотографии всё большего и большего разрешения, хранящиеся во всё более объёмных файлах. Для любого, кто работает с огромным количеством снимков, очень важным оказывается время, необходимое для кодирования и декодирования графических файлов.
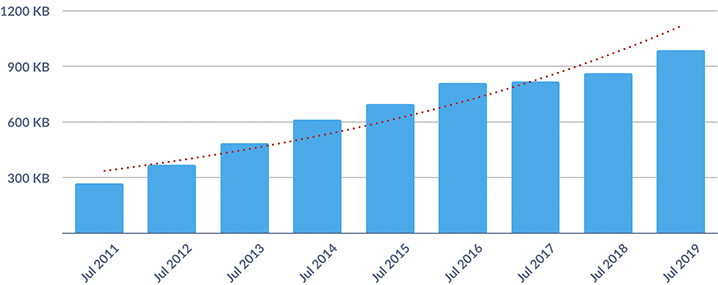
Средний размер изображений, запрашиваемых веб-страницей (по материалам HTTP Archive)
Компьютеры, с 1970-х годов, практически непрерывно становятся всё мощнее и мощнее. Обычно это непрерывное улучшение их характеристик описывают, прибегая к закону Мура. Соответствующий термин появился много лет назад благодаря эмпирическому наблюдению Гордона Мура, в соответствии с которым число транзисторов в компьютерах удваивается каждые 18 месяцев. Этот закон, в целом, остаётся справедливым в том, что касается количества транзисторов, но рост скорости работы компьютеров упёрся в физические ограничения кремния и в проблемы, связанные с питанием микросхем и выделением ими тепла. Так как в последние годы скорость работы отдельного процессора увеличивалась не слишком сильно, внимание индустрии переключилось на применение нескольких процессоров, которые могли бы справляться с различными задачами быстрее за счёт параллельной работы над ними. В современных вычислительных окружениях ценится возможность делить задачи на части и передавать выполнение этих частей разным процессорам. Не все задачи можно так разделить, так как в некоторых случаях следующие части задач могут зависеть от результатов, полученных при обработке их предыдущих частей. Кодирование и декодирование JPEG обычно тяжело разделить на несколько задач и обрабатывать эти задачи параллельно. Дело тут в том, что следующие MCU зависят от предыдущих, и в том, что в JPEG используются коды переменной длины.
Но… Благодаря использованию рестарт-маркеров VLC-данные сбрасываются у границ байтов (в позициях после маркера), сбрасываются и разницы DC-значений MCU. Это означает, что с использованием рестарт-маркеров и кодирование, и декодирование JPEG-изображений может быть разделено на несколько потоков. При кодировании изображение может быть разделено на фрагменты, каждый из которых может кодироваться отдельным процессором. Когда каждый из процессоров завершил свою задачу, то, что получилось у них на выходе, может быть «склеено» с использованием рестарт-маркеров. Задача декодирования может быть распределена между таким количеством процессоров, которое соответствует количеству рестарт-маркеров. Единственная дополнительная задача, которую нужно для этого решить, заключается в предварительном просмотре сжатых данных и в поиске рестарт-маркеров. Дело в том, что размеры данных, находящихся между маркерами, варьируются, и в JPEG-файлах нет «каталога», содержащего сведения о позициях рестарт-маркеров.
В многопоточных приложениях производительность редко находится в прямой зависимости от количества задействованных CPU. То есть — разделение задачи на 12 потоков, выполняющихся на 12 процессорных ядрах, не значит, что эта задача будет выполнена в 12 раз быстрее, чем в однопоточном режиме. При работе в многопоточном режиме на систему ложится дополнительная нагрузка по управлению потоками, и память обычно представляет собой единую сущность, совместно используемую процессорами. Проведём испытание на следующем изображении.

Изображение для испытания
Мы, в Optidash, реализовали вышеописанную идею использования рестарт-маркеров ради серьёзного ускорения декодирования и кодирования изображений. Вышеприведённое изображение было обработано с помощью одного из наших тестовых инструментов на 15-дюймовом MacBook Pro 2018 года с 6-ядерным процессором Intel i7. Вот результаты этого испытания.
Как видите, разделение задач кодирования и декодирования JPEG-файлов между несколькими процессорными ядрами даёт вполне ощутимые преимущества. Производительность при увеличении числа ядер, что зависит от конкретной задачи, редко меняется линейно. В данном случае то, какой выигрыш может дать использование нескольких ядер, ограничивается интенсивным использованием больших областей памяти.
Вот псевдокод, демонстрирующий то, как может быть устроен многопоточный JPEG-кодировщик:
Сталкивались ли вы с задачами обработки JPEG-файлов, для решения которых вам пригодилась бы многопоточная система кодирования и декодирования таких файлов?

Алгоритм кодирования данных JPEG
Процесс сжатия изображений с использованием метода JPEG требует выполнения нескольких шагов (ниже приведена соответствующая схема). Обычно изображение сначала преобразуется из цветового пространства RGB в цветовое пространство YCbCR. Причина необходимости этого шага заключается в том, чтобы сделать возможным субсэмплинг пикселей. Человеческий глаз более чувствителен к изменениям яркости, чем к изменениям цветности. Это позволяет произвести даунсэмплинг цветового канала, но сохранить канал яркости в полном разрешении. На этом шаге изображение может потерять 50% данных, а видимое ухудшение его качества будет минимальным. Затем изображение делится на блоки размером 8x8 пикселей (их называют MCU, Minimal Coding Unit, минимальная единица кодирования). В кодировании видео аналогом MCU являются макроблоки (Macroblock). Итак, MCU — это квадратные блоки пикселей, сжатие информации о которых выполняется на основании сведений об их схожести друг с другом. Сведения о пикселях каждого MCU переводятся из пространственной области в частотную область с использованием дискретного косинусного преобразования (Discrete Cosine Transformation, DCT). Благодаря выполнению этой операции можно легко избавиться от высокочастотной информации (мелких деталей) для ещё более сильного сжатия изображения. Чем больше высокочастотных компонентов убирают — тем меньше будет файл и тем ниже будет качество изображения. Для управления этим аспектом кодирования применяется опция Q (уровень сжатия), используемая программами для JPEG-кодирования.
Обработка изображения при JPEG-кодировании
Одна из многих разумных идей, включённая в стандарт, заключается в использовании схожести значения DC (яркости) между находящимися рядом друг с другом MCU. Это позволяет добиться дальнейшего сокращения размера файла изображения за счёт того, что кодируются лишь изменения значений, а не сами эти значения. На вышеприведённой схеме этот процесс представлен блоком DPCM coding. Это — отличная идея, но она создаёт одну небольшую проблему. Если значение DC для каждого MCU зависит от значения для предыдущего MCU, представляющего собой разницу значений, это значит, что если в данных некоего MCU будет ошибка — это повлияет на все MCU, идущие за ним.
Ситуацию ещё немного усугубляет то, что сжатые символы, кодирующие данные изображения (выше это представлено блоком Huffman coding) — это коды переменной длины (Variable Length Codes, VLC). Всего один неправильный бит может повредить все данные, расположенные в месте повреждения и дальше. В те давние времена, когда был изобретён формат JPEG, это было совершенно реальной проблемой, так как изображения часто передавались по каналам, которые могли не обладать надёжными механизмами коррекции ошибок (вроде соединений, создаваемых с помощью акустических модемов). Изображения, кроме того, хранились на носителях (вроде дискет), информация, записанная на которые, легко могла быть повреждена. Знание о том, что графическая информация, хранимая в JPEG-файлах, может пострадать из-за ошибок, привело к тому, что в стандарт добавили механизм, ограничивающий масштабы повреждения изображений. В основе этого механизма лежит идея о периодическом сбросе предыдущего значения DC в 0, что приводило к тому, что значение для следующего MCU должно было вычисляться в виде его разницы с 0. Это означало, что повреждённые значения DC влияли лишь на пиксели, расположенные до следующей «точки рестарта».
Реализована эта возможность с использованием рестарт-маркеров (Restart Marker). Речь идёт о 2-байтовых маркерах, расположенных между MCU с регулярным интервалом (например — через каждые 100 MCU). Если данные оказываются повреждёнными — несложно найти следующий рестарт-маркер (JPEG-маркеры всегда находятся на границах байтов, им предшествует значение 0xFF). После нахождения позиции следующего рестарт-маркера изображение может быть правильно декодировано начиная с этой позиции, так как известно количество MCU между такими маркерами.
Постоянное развитие масштабов использования цифровых изображений
После выпуска стандарта JPEG компьютерные сети и хранилища данных становились всё надёжнее, в них применялись системы обнаружения и коррекции ошибок (например — TCP/IP). Твердотельные накопители, используемые в цифровых фотоаппаратах, были достаточно надёжными и о рестарт-маркерах на какое-то время «забыли», так как они увеличивали размеры файлов не давая взамен никаких заметных преимуществ. В это время программное обеспечение создавалось, в основном, в расчёте на выполнение на одном процессоре с использованием одного потока. Тот факт, что JPEG-изображения нужно было декодировать за один проход, что было нужно из-за использования кодов переменной длины и данных об изменениях значений для MCU, не вызывал каких-либо проблем для программ, так как они, в любом случае, создавались в расчёте на однопоточный режим.
Правда, в последние годы произошли огромные изменения в компьютерах, и в том, как мы пользуемся JPEG-файлами. Практически каждое вычислительное устройство обладает несколькими CPU и работает под управлением операционной системы, поддерживающей несколько потоков (сюда входят даже телефоны). Другие изменения заключаются в том, что люди снимают, редактируют и просматривают миллиарды JPEG-фотографий на своих телефонах. Каждое новое поколение телефонов позволяет создавать фотографии всё большего и большего разрешения, хранящиеся во всё более объёмных файлах. Для любого, кто работает с огромным количеством снимков, очень важным оказывается время, необходимое для кодирования и декодирования графических файлов.
Средний размер изображений, запрашиваемых веб-страницей (по материалам HTTP Archive)
Превращение хорошей идеи в идею очень хорошую
Компьютеры, с 1970-х годов, практически непрерывно становятся всё мощнее и мощнее. Обычно это непрерывное улучшение их характеристик описывают, прибегая к закону Мура. Соответствующий термин появился много лет назад благодаря эмпирическому наблюдению Гордона Мура, в соответствии с которым число транзисторов в компьютерах удваивается каждые 18 месяцев. Этот закон, в целом, остаётся справедливым в том, что касается количества транзисторов, но рост скорости работы компьютеров упёрся в физические ограничения кремния и в проблемы, связанные с питанием микросхем и выделением ими тепла. Так как в последние годы скорость работы отдельного процессора увеличивалась не слишком сильно, внимание индустрии переключилось на применение нескольких процессоров, которые могли бы справляться с различными задачами быстрее за счёт параллельной работы над ними. В современных вычислительных окружениях ценится возможность делить задачи на части и передавать выполнение этих частей разным процессорам. Не все задачи можно так разделить, так как в некоторых случаях следующие части задач могут зависеть от результатов, полученных при обработке их предыдущих частей. Кодирование и декодирование JPEG обычно тяжело разделить на несколько задач и обрабатывать эти задачи параллельно. Дело тут в том, что следующие MCU зависят от предыдущих, и в том, что в JPEG используются коды переменной длины.
Но… Благодаря использованию рестарт-маркеров VLC-данные сбрасываются у границ байтов (в позициях после маркера), сбрасываются и разницы DC-значений MCU. Это означает, что с использованием рестарт-маркеров и кодирование, и декодирование JPEG-изображений может быть разделено на несколько потоков. При кодировании изображение может быть разделено на фрагменты, каждый из которых может кодироваться отдельным процессором. Когда каждый из процессоров завершил свою задачу, то, что получилось у них на выходе, может быть «склеено» с использованием рестарт-маркеров. Задача декодирования может быть распределена между таким количеством процессоров, которое соответствует количеству рестарт-маркеров. Единственная дополнительная задача, которую нужно для этого решить, заключается в предварительном просмотре сжатых данных и в поиске рестарт-маркеров. Дело в том, что размеры данных, находящихся между маркерами, варьируются, и в JPEG-файлах нет «каталога», содержащего сведения о позициях рестарт-маркеров.
Реальный пример
В многопоточных приложениях производительность редко находится в прямой зависимости от количества задействованных CPU. То есть — разделение задачи на 12 потоков, выполняющихся на 12 процессорных ядрах, не значит, что эта задача будет выполнена в 12 раз быстрее, чем в однопоточном режиме. При работе в многопоточном режиме на систему ложится дополнительная нагрузка по управлению потоками, и память обычно представляет собой единую сущность, совместно используемую процессорами. Проведём испытание на следующем изображении.
Изображение для испытания
Мы, в Optidash, реализовали вышеописанную идею использования рестарт-маркеров ради серьёзного ускорения декодирования и кодирования изображений. Вышеприведённое изображение было обработано с помощью одного из наших тестовых инструментов на 15-дюймовом MacBook Pro 2018 года с 6-ядерным процессором Intel i7. Вот результаты этого испытания.
| Количество ядер | Время декодирования, мс | Время кодирования, мс |
| 1 | 53 | 264 |
| 3 | 25 | 104 |
| 6 | 18 | 61 |
Как видите, разделение задач кодирования и декодирования JPEG-файлов между несколькими процессорными ядрами даёт вполне ощутимые преимущества. Производительность при увеличении числа ядер, что зависит от конкретной задачи, редко меняется линейно. В данном случае то, какой выигрыш может дать использование нескольких ядер, ограничивается интенсивным использованием больших областей памяти.
Вот псевдокод, демонстрирующий то, как может быть устроен многопоточный JPEG-кодировщик:
void ThreadedWriteJPEG(assorted JPEG parameters, int numThreads) {
int slice;
pthread_t tinfo;
// задаём счётчик, используемый для определения момента завершения работы
sliceRemaining = numThreads;
// Запускаем поток для каждого фрагмента
for (slice = 0; slice < numThreads; slice++) {
pthread_t tinfo;
// Используем структуру ‘slice’ для хранения сведений о работе каждого потока
// В эти сведения входят указатель на начало полосы пикселей
// и количество строк пикселей, которое нужно сжать
<настройка структуры slice для обеспечения работы каждого потока>
pthread_create(&tinfo, NULL, JPEGBuffer, &slices[slice]);
} // для каждого фрагмента
// ожидаем завершения всех рабочих потоков
WaitForThreads(&sliceRemaining);
// объединяем фрагменты в один файл и записываем его
WriteJPEGBuffer(slices, numThreads);
}
Сталкивались ли вы с задачами обработки JPEG-файлов, для решения которых вам пригодилась бы многопоточная система кодирования и декодирования таких файлов?



