
Это вторая часть расшифровки доклада Ивана Углянского (dbg_nsk) с JPoint 2020, посвященного связи Java с нативным кодом. В прошлой части мы поговорили про традиционный способ связи — через Java Native Interface (JNI), рассмотрели специфичные ему проблемы и оценили производительность. Картина получилась удручающей, поэтому давайте разбираться, чем можно заменить JNI?
Если не JNI, то кто?
Если на JNI писать так больно, то возникает очевидная идея: может, не стоит заставлять Java-программистов писать код на C или C++ — непривычных и не самых дружественных языках? Что конкретно предлагается: как можно больше всего писать на стороне Java, а саму связь с нативным кодом как-то генерировать автоматически, переложив эту задачу на плечи сторонних библиотек.
Таких библиотек за время существования Java написали огромное множество, и одно только их перечисление займет немало времени.
Я выбрал три из них, которые считаю наиболее важными для Java-экосистемы сегодня: самые популярные, либо бурно развивающиеся прямо сейчас, либо предлагающие уникальную функциональность.
JNA
Начнем, конечно, с JNA, что расшифровывается как Java Native Access. Это довольно старая (с 2007 года) и одна из самых популярных на сегодняшний день библиотек для связи с нативным кодом. Если вы хотите её использовать в своём проекте, нужно добавить вот такую зависимость в pom.xml:
<dependency>
<groupId>net.java.dev.jna</groupId>
<artifactId>jna</artifactId>
<version>5.5.9</version>
<dependency>После этого вы пишете абсолютно обычный код на C, без всяких заклинаний типа JNIEXPORT или JNICALL:

А затем на стороне Java создаете вот такой интерфейс MyNativeLibrary.
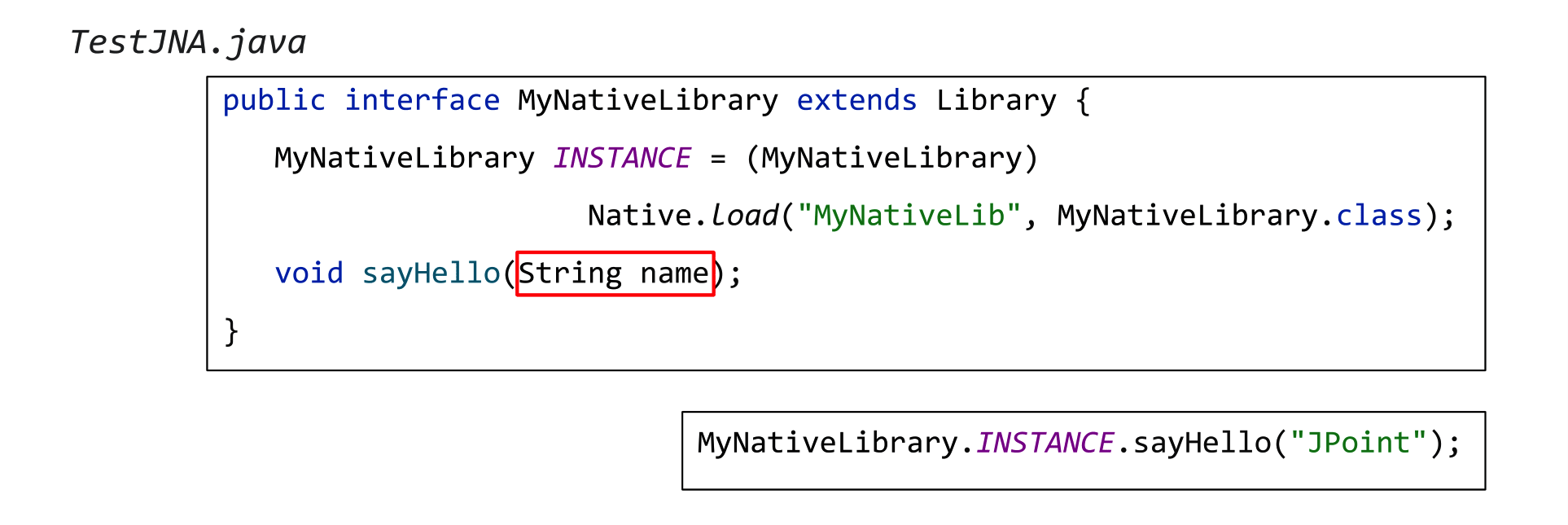
В нём есть не native, а обычный Java метод sayHello, который принимает обычную же Java-строку. Это аналог того нативного метода sayHello, который вы описали в С-шном коде. После этого вы указываете через создание INSTANCE и вызов Native.load, в какой библиотеке искать этот метод, вызываете sayHello и… всё работает!
Вы не написали ни одного ключевого слова native, ничего специфичного на стороне самого нативного кода (кроме разве что экспортирования метода), но только что совершили максимально комфортный переход в нативный код из Java!
Безусловно, вызовы таких тривиальных нативных функций обычно не очень интересны. Чаще нативные функции работают с нативными же данными — принимают или возвращают сишные структуры (иногда по значению), указатели, zero-terminated строчки и т.д. JNA и здесь не подводит: она позволяет работать с аналогами соответствующих сущностей на стороне Java. Вместо указателей можно работать с классом Pointer из JNA, есть поддержка C-like массивов, строк, даже vararg.
Но это еще не все! Если вы хотите воспользоваться какой-то популярной С-шной библиотекой, то вам даже на Java писать ничего не понадобится, никаких новых интерфейсов или подгрузок библиотек. Для JNA есть немало заранее заготовленных интерфейсов для работы с популярными библиотеками для разных платформ: LibC, X11, udev, Kernel32, Pdh, Psapi и многие многие другие.
JNA на GitHub
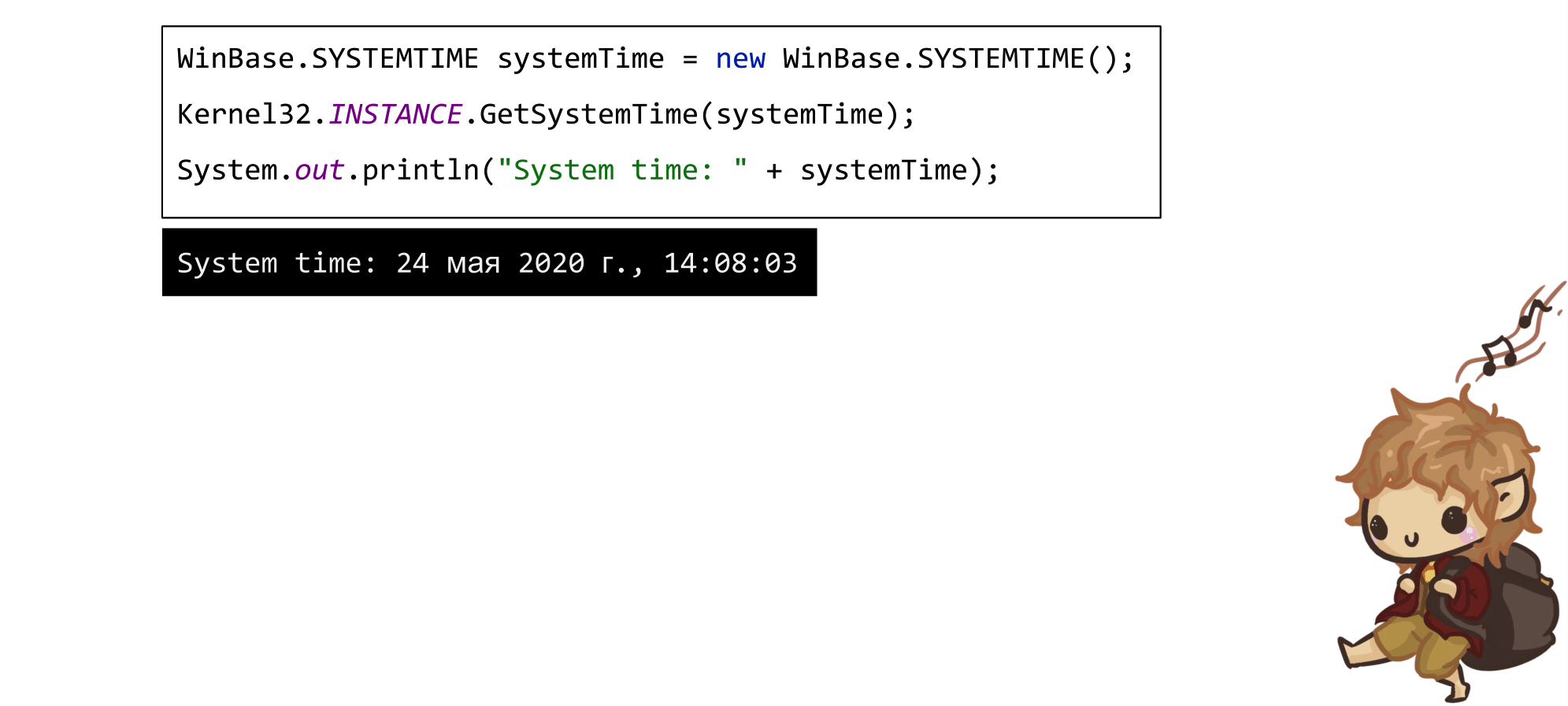
Допустим, вы хотите получить информацию от операционной системы, вызвав, например, функцию из Kernel32. Вы подключаете зависимость с заготовками, аллоцируете в куче структуру SYSTEMTIME, указатель на нее передаете в системный метод GetSystemTime и получаете результат.
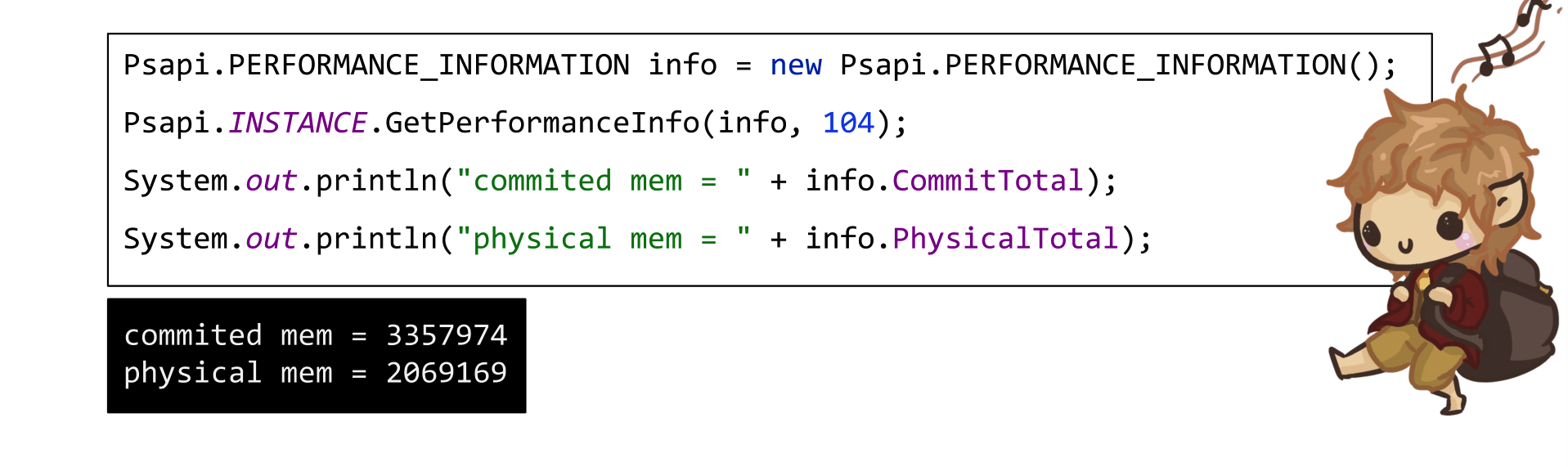
Чуть более сложный пример: захотели через Psapi узнать, сколько у вас памяти закоммичено и сколько вообще есть физической. Снова аллоцируете в куче структуру PERFORMANCE_INFORMATION, передаете ее в функцию GetPerformanceInfo из библиотеки Psapi — и у вас появляется низкоуровневая информация о состоянии памяти, которую так просто через Java не получить.
Всё это выглядит очень круто и по сравнению с JNI и работает из коробки, буквально как по волшебству.
Производительность JNA
Но, конечно, за любое волшебство нужно платить. В случае с JNA, в первую очередь, мы заплатим производительностью. Вызовы нативного кода через JNA работают крайне неспешно.
В прошлой части мы проводили эксперимент: сравнивали производительность вызова пустого нативного метода через JNI, с вызовом такого же пустого, но уже Java-метода.
Тогда получилось, что натив вызывается в 6 раз медленнее.
А теперь сравним вызовы пустого натива через JNI и через JNA.
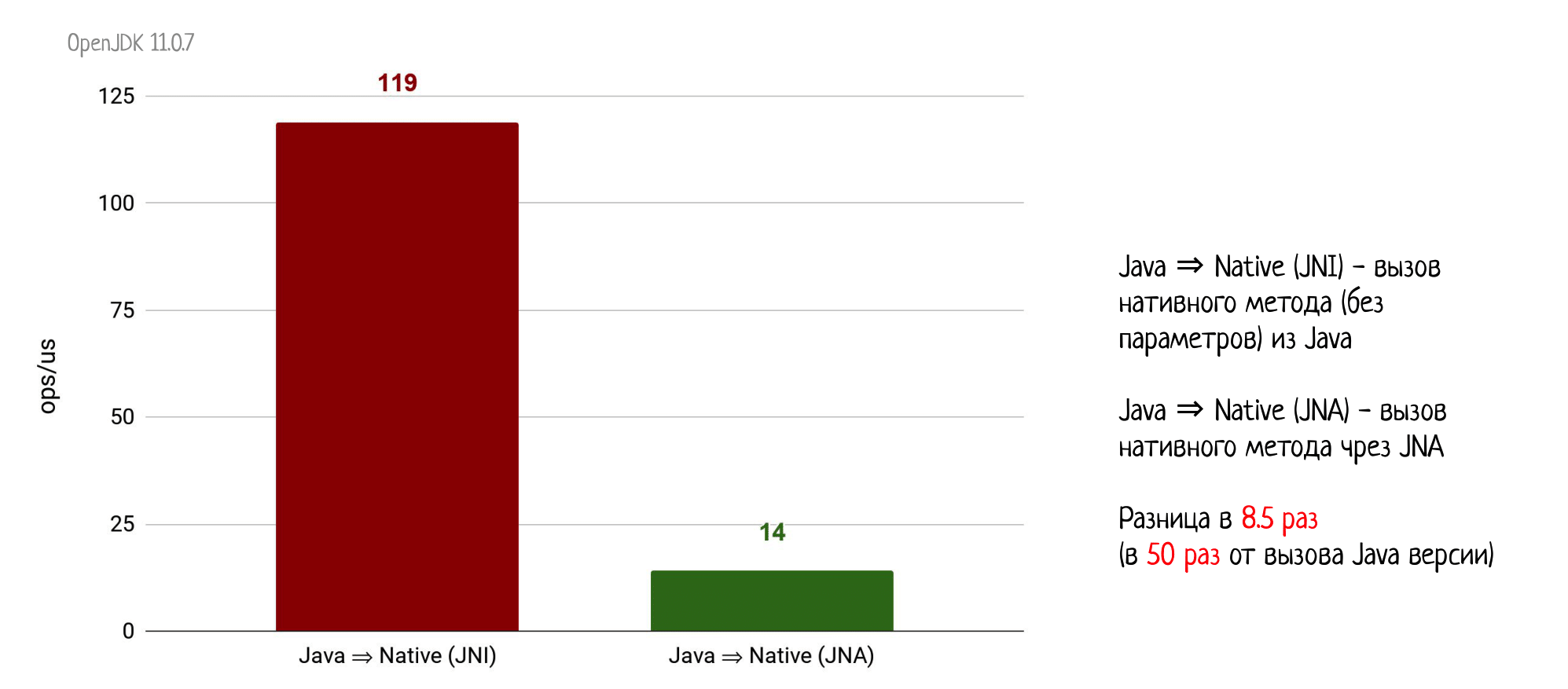
Получим просадку производительности ещё в 8,5 раз! Получается, что вызов натива через JNA работает уже в 50 раз медленнее, чем обычный Java-вызов. Не будем уже глумиться и повторять эксперимент по возвращению обратно из натива в Java-код, там разница окажется еще более трагичной.
Почему так?
Начнем с того, что JNA базируется на JNI, поэтому быстрее она работать уж точно не может. Это такое естественное ограничение сверху.
Далее снова сверяемся с нашей картой, где теперь особую роль играет первый пункт назначения:
Откуда вообще брать реализацию нативных методов, если мы даже не объявляем native-методы в Java и не пишем различные JNIEXPORT в нативе? Как виртуальная машина найдет правильные реализации в нативных библиотеках?
С этим помогает сама JNA: когда вызывается Java метод sayHello, на самом деле исполнение приходит в com.sun.jna.Function.invoke(…), где через рефлексию собирается информация о том, что за метод хотели позвать. Кроме того, происходит подготовка параметров, обработка всяких сложных случаев, типа передачи по значению и так далее. Все это занимает много времени.

Потом наконец происходит переход в натив, но не в ваш, а в специальный натив из библиотеки JNA, который называется invokeVoid. Там на C написан огромный dispatch в зависимости от того, какие аргументы вы передаете и какой метод хотите позвать. И только после этого исполнение наконец добирается до C-метода sayHello, чего вы изначально и хотели.
В результате сразу получаем просадку производительности за счет двух дополнительных уровней косвенности.
Корректность JNA
Другая проблема JNA — она жутко мусорит Java-обертками вокруг нативных сущностей. Например, для работы с указателями создаются объекты Pointer в памяти, причем куда больше, чем хотелось бы (JNA нередко создает копии оберток даже тогда, когда без этого можно было обойтись).
Работа с обертками — это, во-первых, неприятная нагрузка на GC, да и в целом — дополнительные накладные расходы на поддержание связи завертки с самой нативной сущность. Но что ещё важнее — неаккуратное использование этих заверток может ударить по корректности работы вашего приложения.
Приведу простой пример.
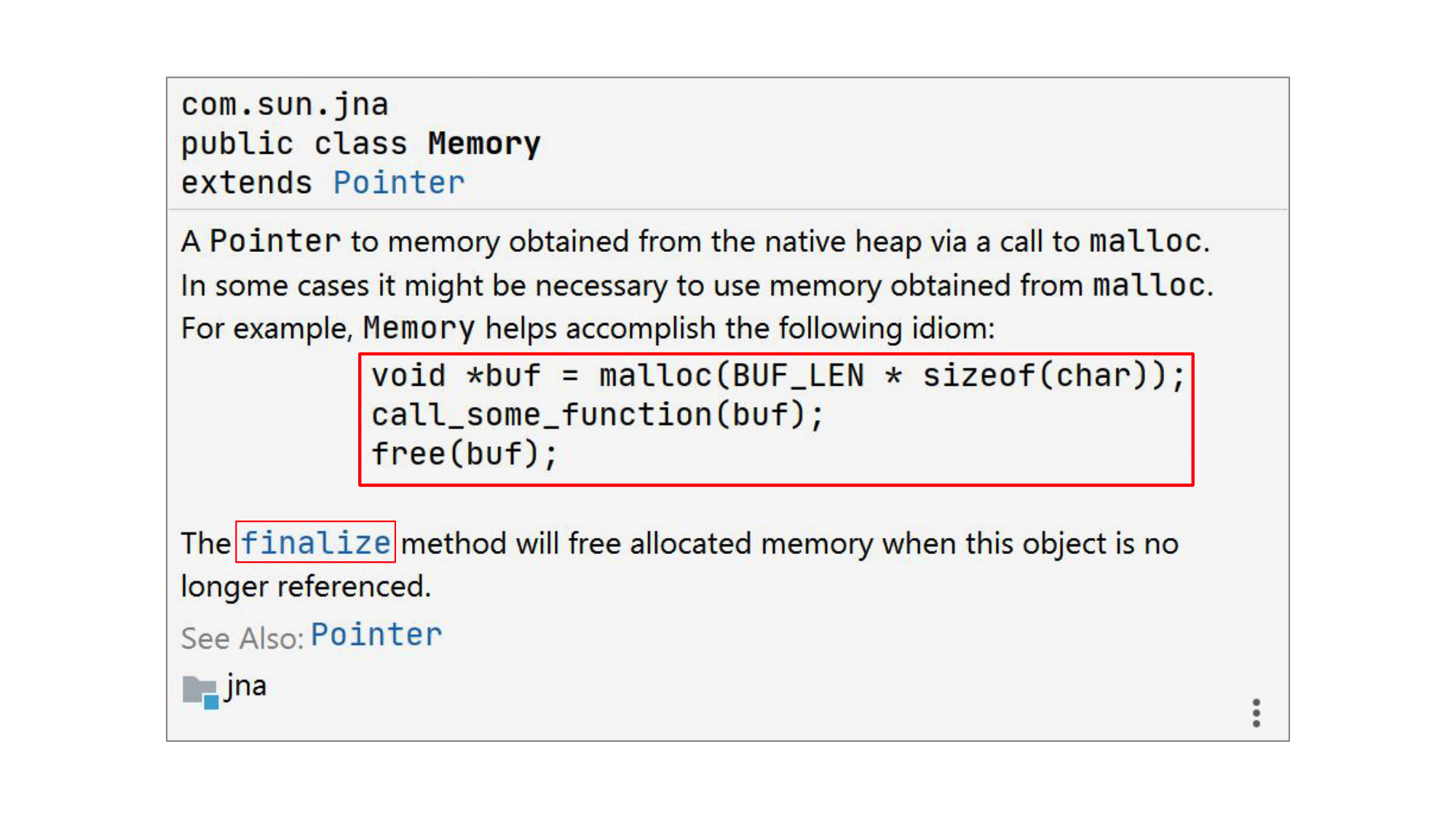
Есть в JNA такой замечательный класс com.sun.jna.Memory. Он появился исключительно из-за заботы создателей JNA о Java-программистах.
Дело в том, что в C часто встречается такой паттерн: вы malloc-ом выделяете себе память по некий буфер, передаете его в функцию, где с ним работают, а по возвращении из функции вызываете free, чтобы очистить память.
Memory — это класс в JNA, предназначенный для обработки именной такой ситуации, но уже со стороны Java. Единственное что: ну зачем же руками писать free на стороне Java, это же неудобно! У нас для этого есть отличный механизм, который называется финализацией и позволяет вызывать метод finalize перед тем, как объект будет собран сборщиком мусора. Именно в таком методе finalize класса Memory создатели JNA и решили вызывать метод free.
Хотя появление в этом рассказе финализации уже может насторожить (ведь она часто вызывает проблемы с GC), в целом пока всё выглядит вполне нормально. Но вот вам реальный пример из нашей практики, демонстрирующий, к чему все это может привести.
У нас был клиент, который активно пользовался JNA. По ходу работы его приложения в памяти создавался тот самый объект Memory. Кроме того, у клиента был свой собственный класс StringByReference, предназначенный для передачи строчки по ссылке. Он был написан по всем канонам JNA, тоже использовал финализацию для очистки ресурсов, а также содержал ссылку на тот самый объект класса Memory.
Эти два объекта выглядели так:
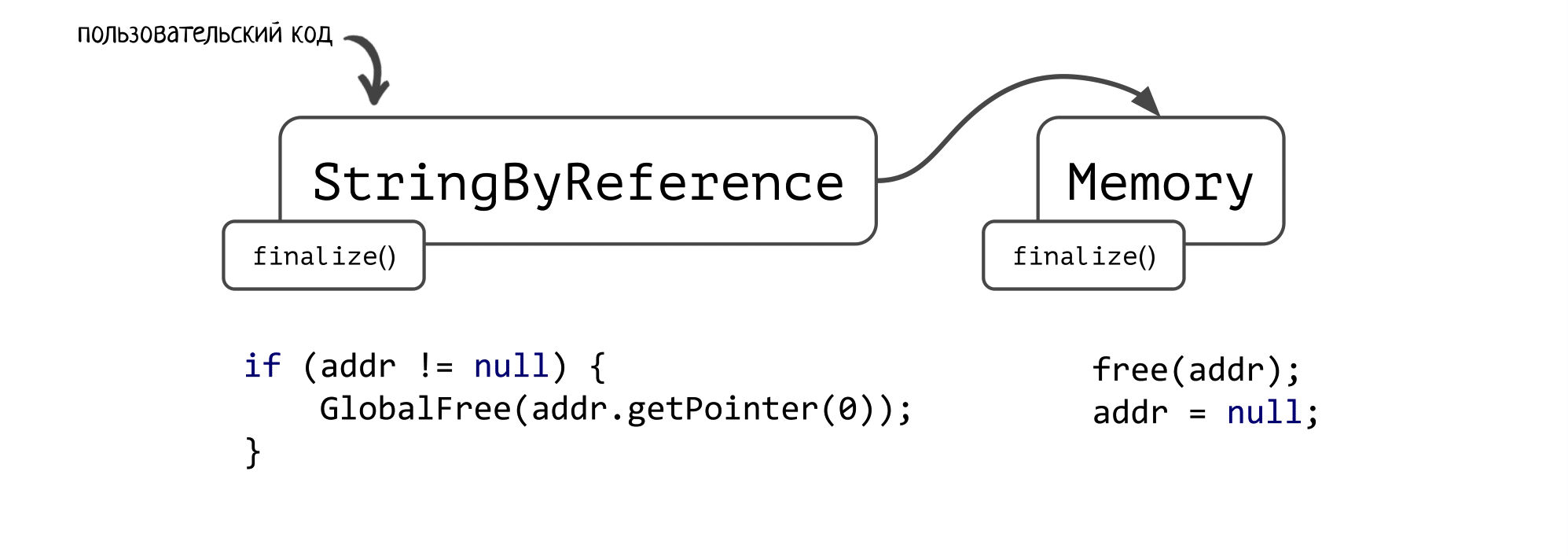
В классе Memory есть поле addr — сырой адрес соответствующей нативной памяти.
В финализаторе вызывается нативный free, чтобы эту память почистить, а затем поле addr зануляется.
А в finalize() пользовательского класса проверялось: если поле addr ещё не null, то вызываем GlobalFree от указателя, который лежит по этому адресу.
И вот здесь начинается самое интересное! Чей финализатор вызовется первее? В спецификации про это ничего не сказано — порядок вызова финализаторов неопределен.
Если сначала сработает финализатор Memory, то мы чистим память, адрес на которую записан в addr. Затем переходим в финализатор StringByReference, где не делаем ничего, т.к. в addr уже лежит null. Результат — утечка нативной памяти, адрес на которую был записан в уже освобожденной в первом финализаторе ячейке.
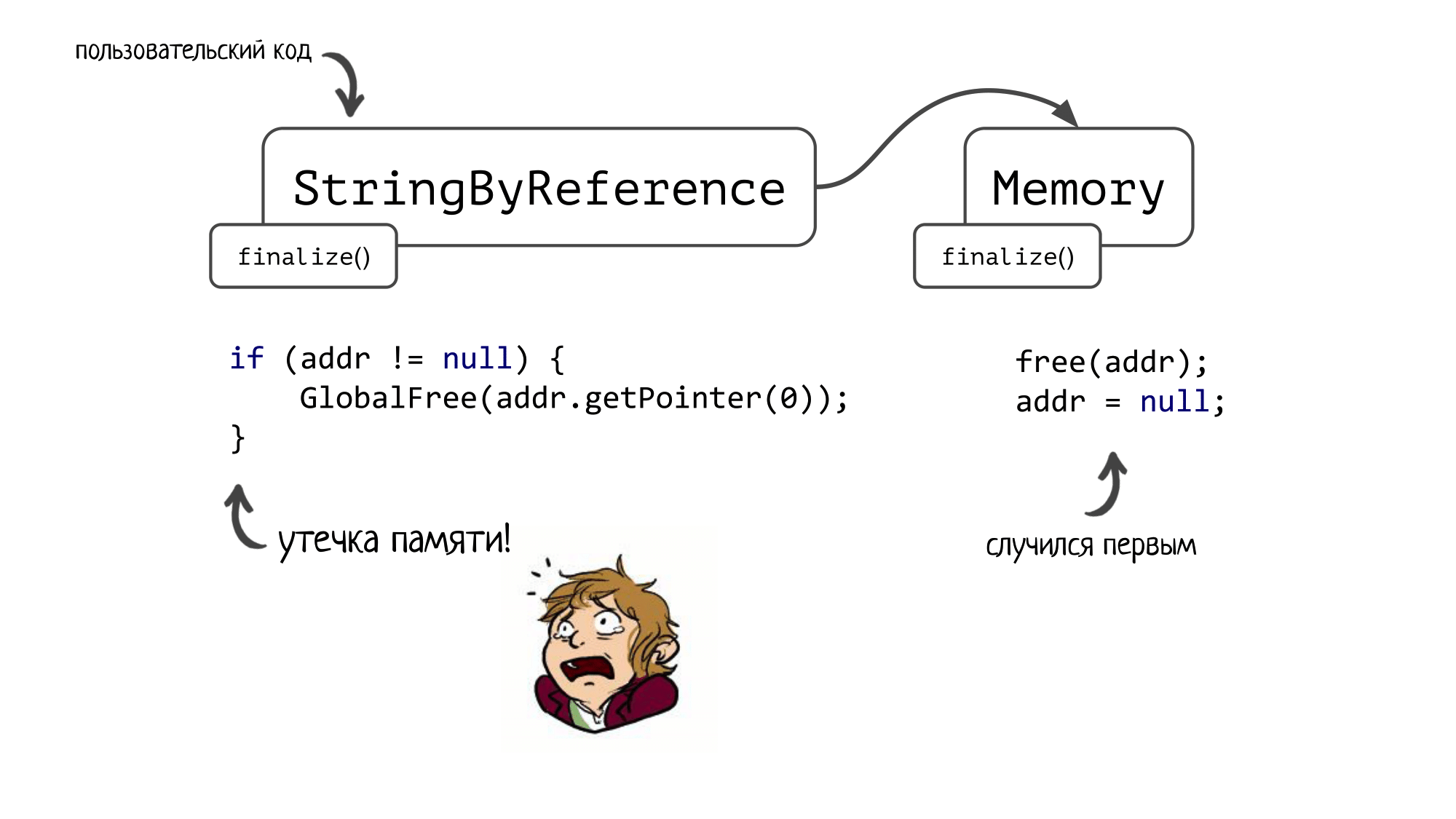
Но это ещё полбеды! А теперь представьте, что сначала срабатывает финализатор для StringByReference, и при этом в addr лежит мусор (а это очень даже может быть, т.к. JNA любит мусорить неправильно сконструированными завертками вокруг native сущностей, в т.ч. Memory). Мы вызовем GlobalFree от какой-то битой памяти и схлопочем спорадичный развал, причем проявиться он может не сразу, а спустя минут 10 работы нашего приложения.
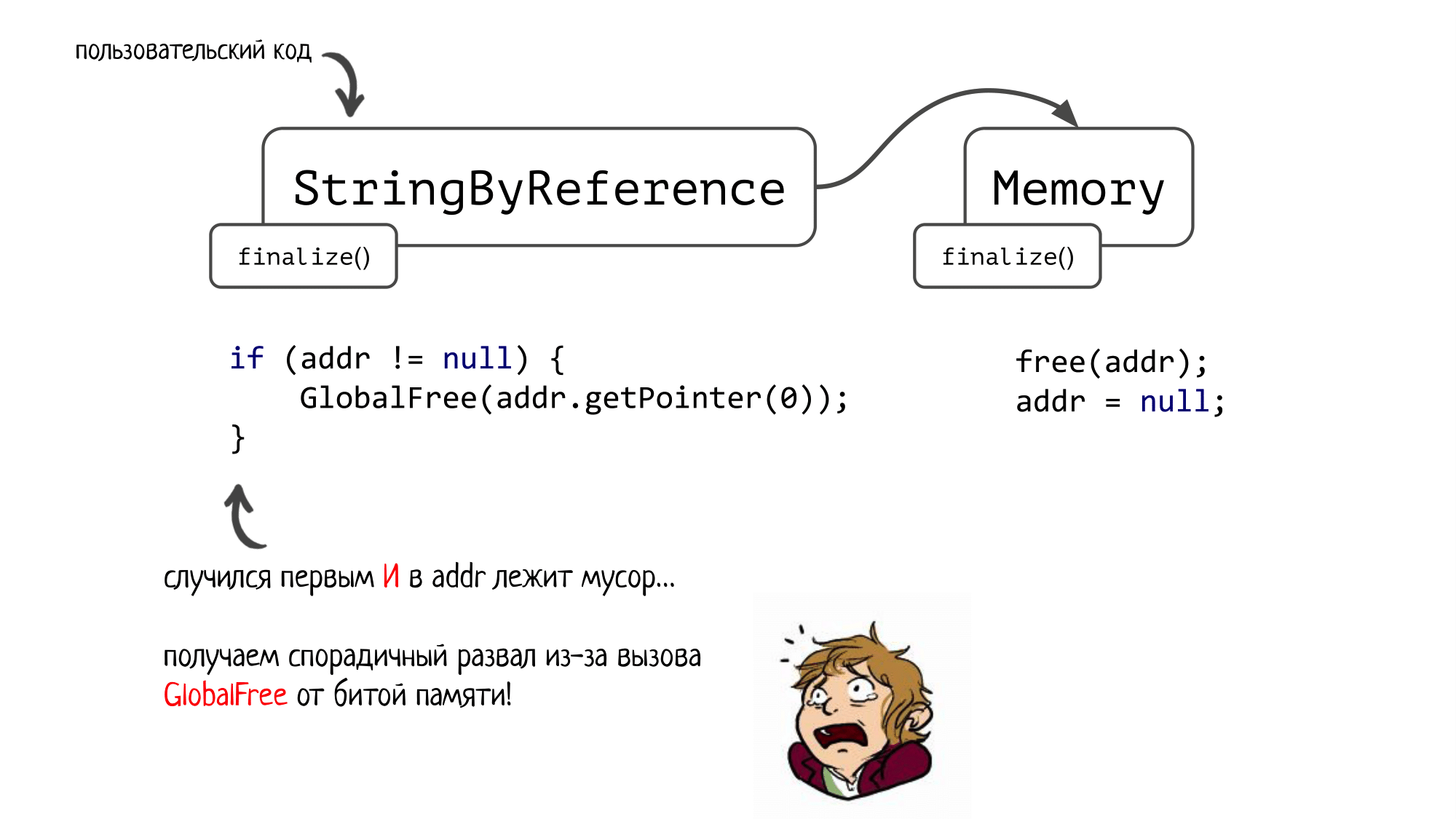
Можно, конечно, поспорить, кто здесь виноват — JNA или пользователь, который написал такой класс. Но когда к нам в саппорт приходили люди, у которых не работали нативы, я всегда в первую очередь спрашивал: «А у вас, случайно, не JNA?». И чаще всего они удивлялись, говорили «Да, именно JNA» и спрашивали, а как же я это узнал.
К сожалению, в JNA подобных проблем огромное множество. И зачастую вы можете получить спорадичный и трудноотлаживаемый баг, когда просто пытаетесь вызвать нативный метод с минимальным количеством усилий.
Какой подход выбрать?
Итак, теперь у нас уже есть два подхода: мы можем вызывать нативы через JNI или можем использовать JNA. Чтобы понять, какой подход лучше, я предлагаю ввести таблицу сравнения по несколькими критериям.
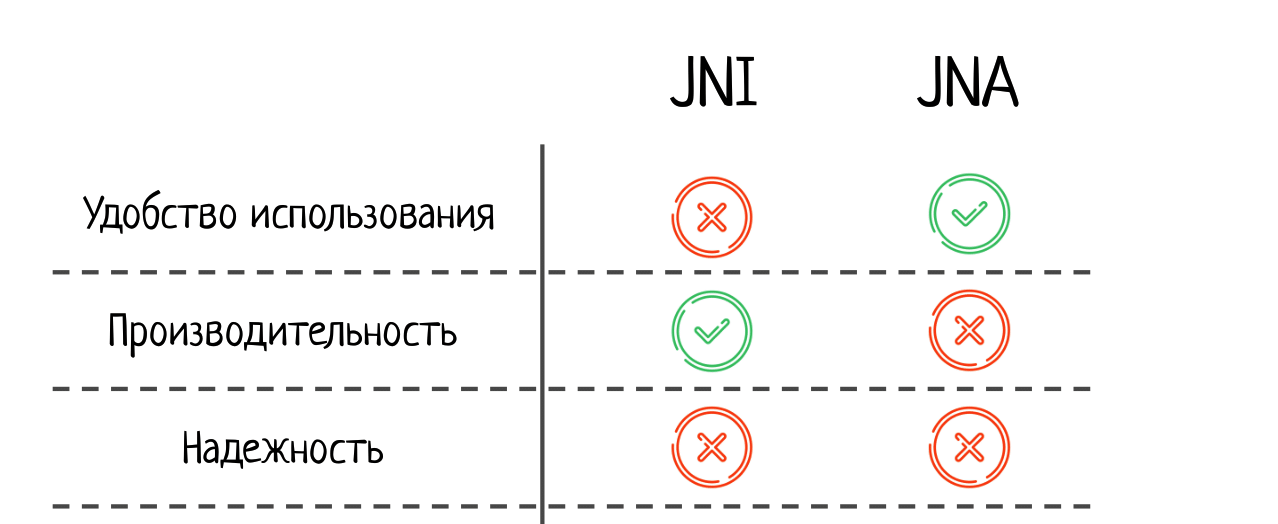
Первое — насколько удобно использовать тот или иной подход. Тут JNA, конечно, выигрывает. Это потрясающе удобно, особенно, если вам нужно взаимодействовать с популярной библиотекой, для которой уже есть заготовки. Все работает из коробки, как по волшебству.
Второе — производительность. Тут JNA значительно проигрывает, JNI быстрее на порядок. Если для вас производительность критична, можно даже не смотреть в сторону JNA.
Третье — надёжность. Здесь обе технологии получают «незачет». В JNI легко ошибиться «руками» (см. первую часть доклада), а JNA же ненадежен потому, что может произойти высокоуровневая и сложно прогнозируемая ошибка из-за внутреннего устройства самого JNA.
Следующий критерий — заготовки для библиотек, насколько легко взять готовую библиотеку и использовать её. В JNI по умолчанию такого нет, нужно написать чуть-чуть С-шного кода, и только потом вызывать методы из библиотеки. В JNA заготовок много, что значительно облегчает взаимодействие с нативным кодом.
Далее — документация. В JNI отличная и подробная спека, в которой указано, что можно делать, а чего нельзя. Но и у JNA здесь все хорошо: т.к. это уже довольно старый фреймворк, то для него написано много качественной документации.
И последний пункт — работает ли с C++. Это тоже может быть важно, ведь огромное количество библиотек написаны не на чистом Си, а на плюсах. Из коробки JNI с плюсами не работает. Конечно, вы при этом всегда можете написать extern “C”, задать бинарный интерфейс и уже с ним взаимодействовать через JNI, но это не моментально, нужно делать дополнительную работу. Это же касается и JNA.

Другой вариант — Java Native Runtime
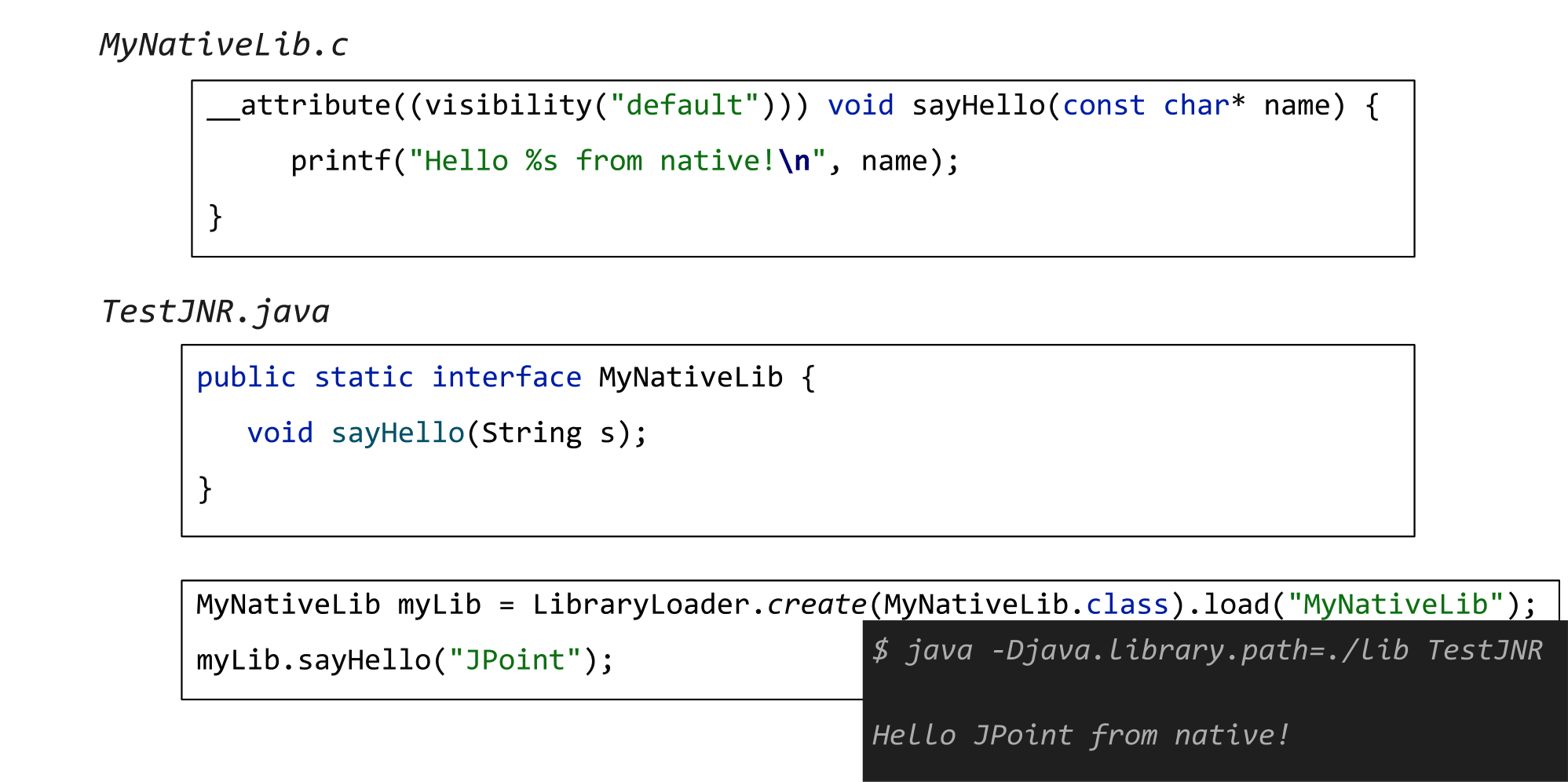
Поехали дальше! Следующая наша остановка — JNR или Java Native Runtime. Чтобы взаимодействовать с нативным кодом через него, нужно добавить вот такую зависимость в ваш pom.xml:
<dependency>
<groupId>com.github.jnr</groupId>
<artifactId>jnr-ffi</artifactId>
<version>2.1.14</version>
<dependency>После этого снова пишете обычный сишный код без всяких заклинаний, а затем — чуть-чуть другие интерфейсы на стороне Java. Пишете метод sayHello без модификатора native, чуть по-другому задаете, где брать нативную библиотеку и… вы снова быстро и безболезненно попадаете в нативный код!
Наверное, сейчас вы спрашиваете себя: «Зачем он пишет про очередной клон JNA? Мы ведь только что прочитали несколько страниц про него, что мы теперь будем все фреймворки так разбирать?»
Действительно, снаружи JNR очень похож на JNA, но при этом у него есть ряд кардинальных преимуществ. И, конечно, главное из них — это производительность.
Напоминаю, что вот такой позорный результат бенчмарка мы получали у JNA.
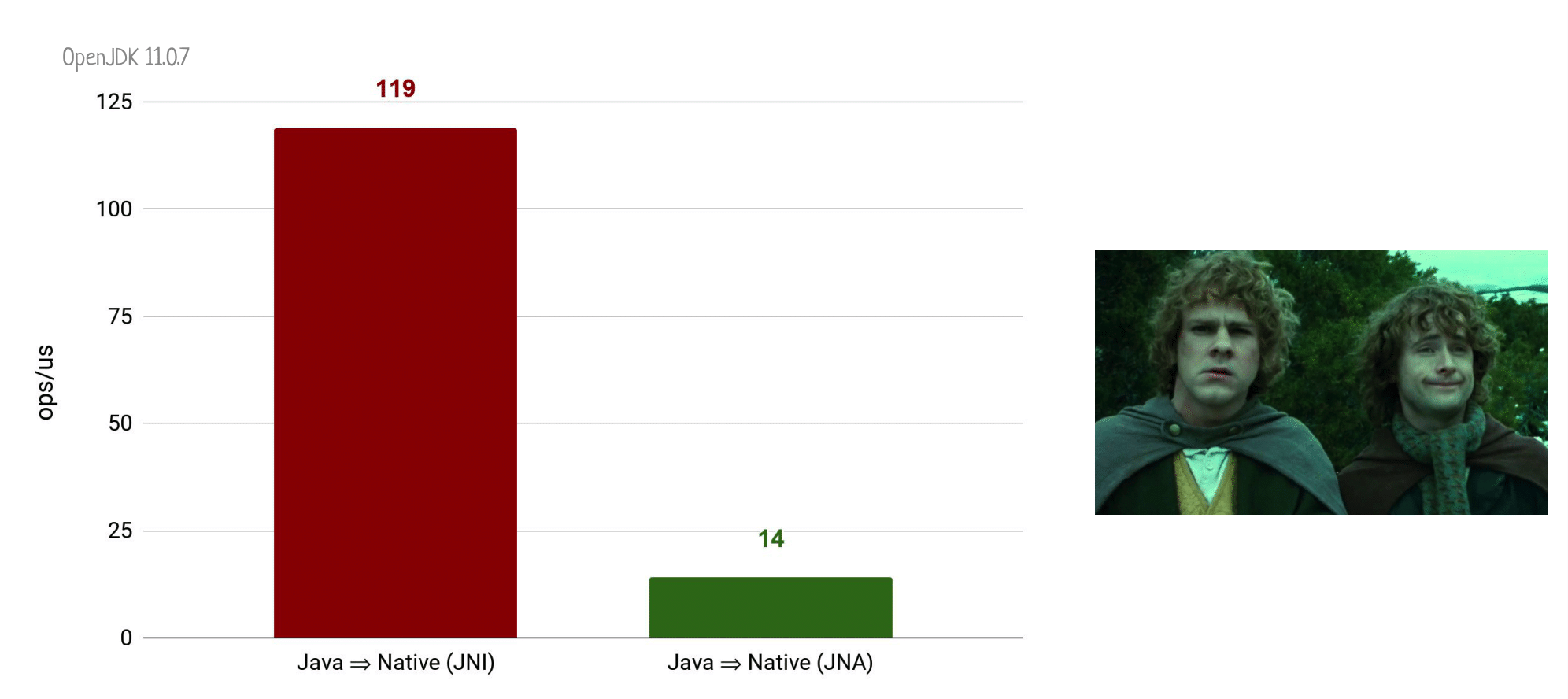
А если мы проведем абсолютно аналогичный эксперимент с вызовом пустого нативного метода через JNR, то моментально получим ускорение где-то в 6 раз.
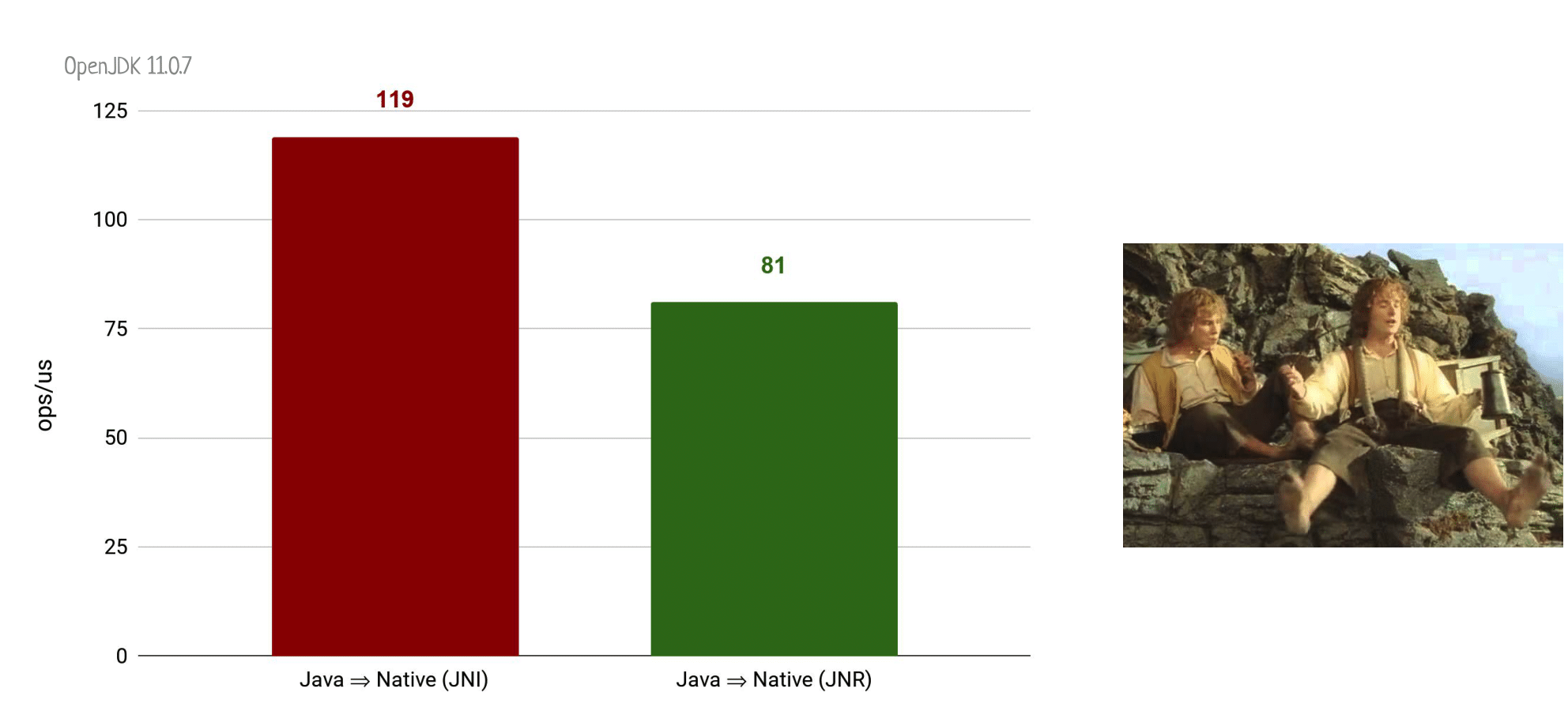
Это всё ещё не дотягивает до вызова натива через старый добрый JNI, но уже гораздо быстрее JNA.
Более того, в JNR есть интересная фича: вы можете добавить к функции соответствующую нативному методу аннотацию @IngoreError:

Это означает, что нет смысла разбираться после вызова натива, произошла ли какая-то ошибка, анализировать и обрабатывать error-коды. Вместо этого просто игнорируем их, даже если что пошло не так. Зачастую это вполне приемлемое поведение. Вешаем аннотацию и получаем… 112 попугаев. Почти столько же, сколько у вызова натива через JNI!
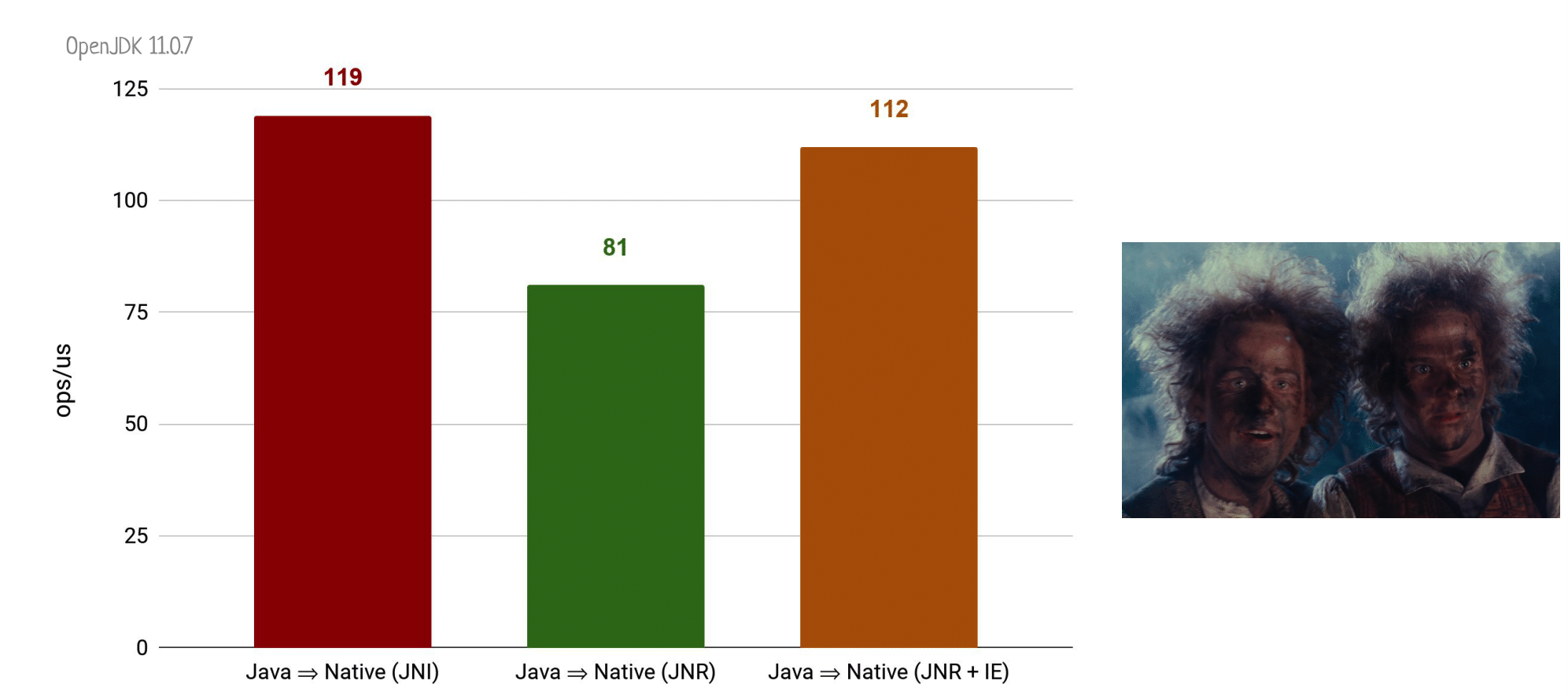
И это очень круто, потому что перед нами всё ещё остро стоит вопрос, а где брать нативы?
Как и всегда, JNR не может быть быстрее JNI, потому что внутри он на нем базируется — здесь полная аналогия с JNA.
Но вот как конкретно искать нативные методы — в JNR этот вопрос решён иначе. Со стороны Java генерируется суперлегковесный байткодный wrapper, который чаще всего проинлайнится и который в свою очередь вызывает некий нативный метод. Но в этот раз код этого нативного метода тоже сгенерирован на лету!

То есть буквально во время исполнения сгенерируются asm-инструкции, реализующие поиск уже вашего нативного метода и переход в него. Сгенерированный код максимально близок к оптимальному. Например, в случае вызова пустого метода без параметров и возвращаемого значения тело нативного wrapper-а будет состоять из единственной инструкции jump, которая моментально переведет вас в правильный нативный метод.
Таким образом, у нас сохраняется два дополнительных уровня косвенности, но реализованы они настолько эффективно, что ухудшения производительности почти не наблюдается.
Вообще JNR — крутая штука, она используется в проекте JRuby, про нее часто говорят и она активно развивается. Если вы посмотрите репозиторий JNR, то окажется, что буквально последний коммит был вчера-сегодня. И это отлично — если в JNR обнаруживается проблема, то её очень скоро чинят.
Из минусов — asm-завертки генерируются не на всех платформах, например, на Windows вы не получите такого мощного ускорения нативных вызовов по сравнению с JNA.
Да и в целом — библиотека очень posix-центрична, те же завертки присутствуют только для популярных posix-ных библиотек, для остальных придется их писать руками.
Наконец, документации почти нет. Чтобы понять, как этим пользоваться для нетривиальных сценариев, нужно пойти в репозиторий JRuby и там посмотреть, как именно люди используют JNR.
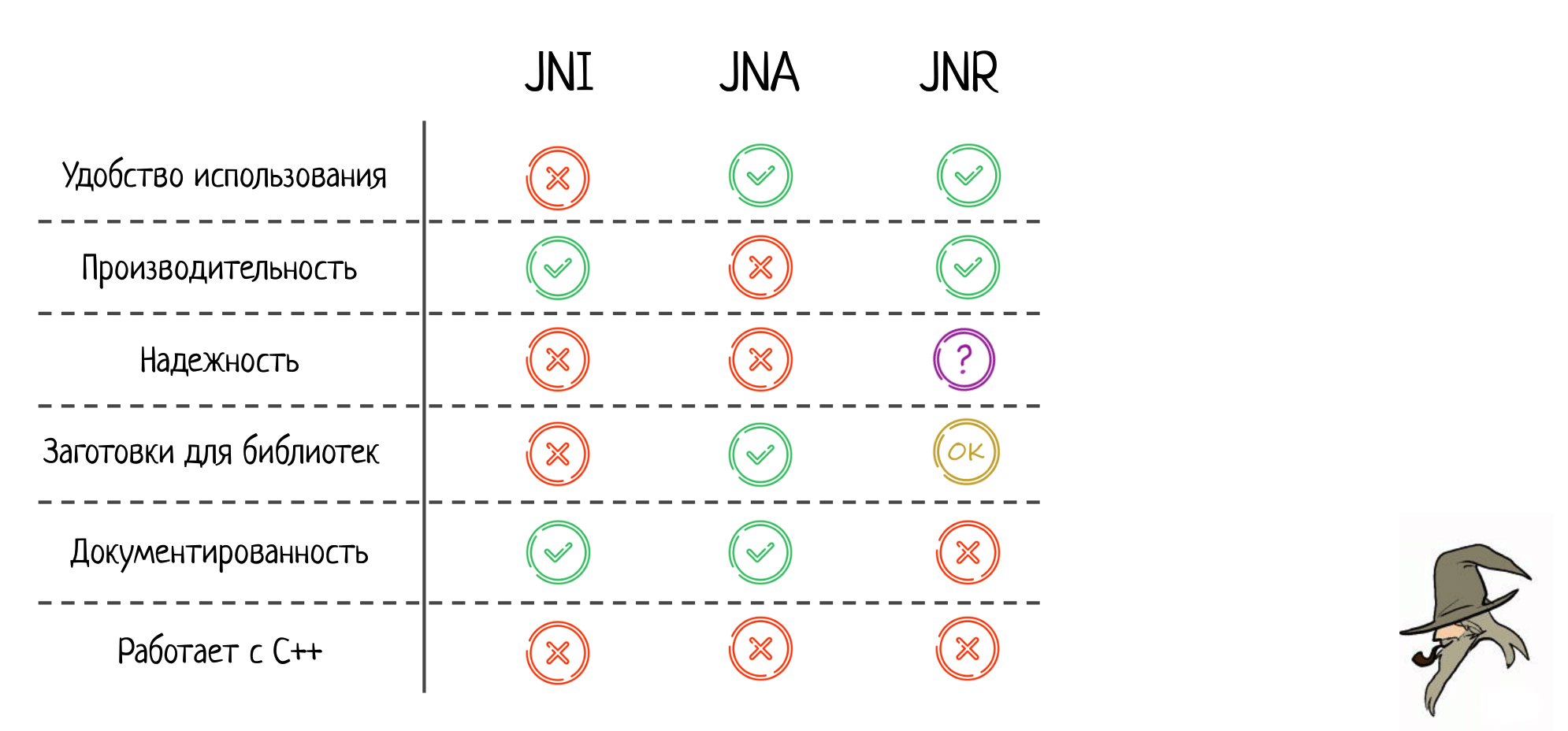
Соответствующим образом заполняем нашу табличку: JNR получает твердую пятерку по удобству; производительность почти дотягивает до натива, что очень впечатляет.
Про надёжность: не могу принять четкого решения. JNR не замечен ни за чем плохим, и в его коде я тоже криминального ничего не увидел. Но, возможно, дело в меньшей популярности среди пользователей, чем у той же JNA. Когда больше людей начнут этим пользоваться, могут проявиться и новые проблемы.
Заготовки для библиотек есть, но они слабенькие, документированность никуда не годится, с C++ из коробки JNR тоже не работает.
Что же работает с плюсами?
А с нативным кодом, написанным на C++, отлично работает библиотека JavaCPP. Если хотите использовать ее в своем проекте, то добавляете следующую зависимость в свой pom.xml:
<dependency>
<groupId>org.bytedeco</groupId>
<artifactId>javacpp</artifactId>
<version>1.5.3</version>
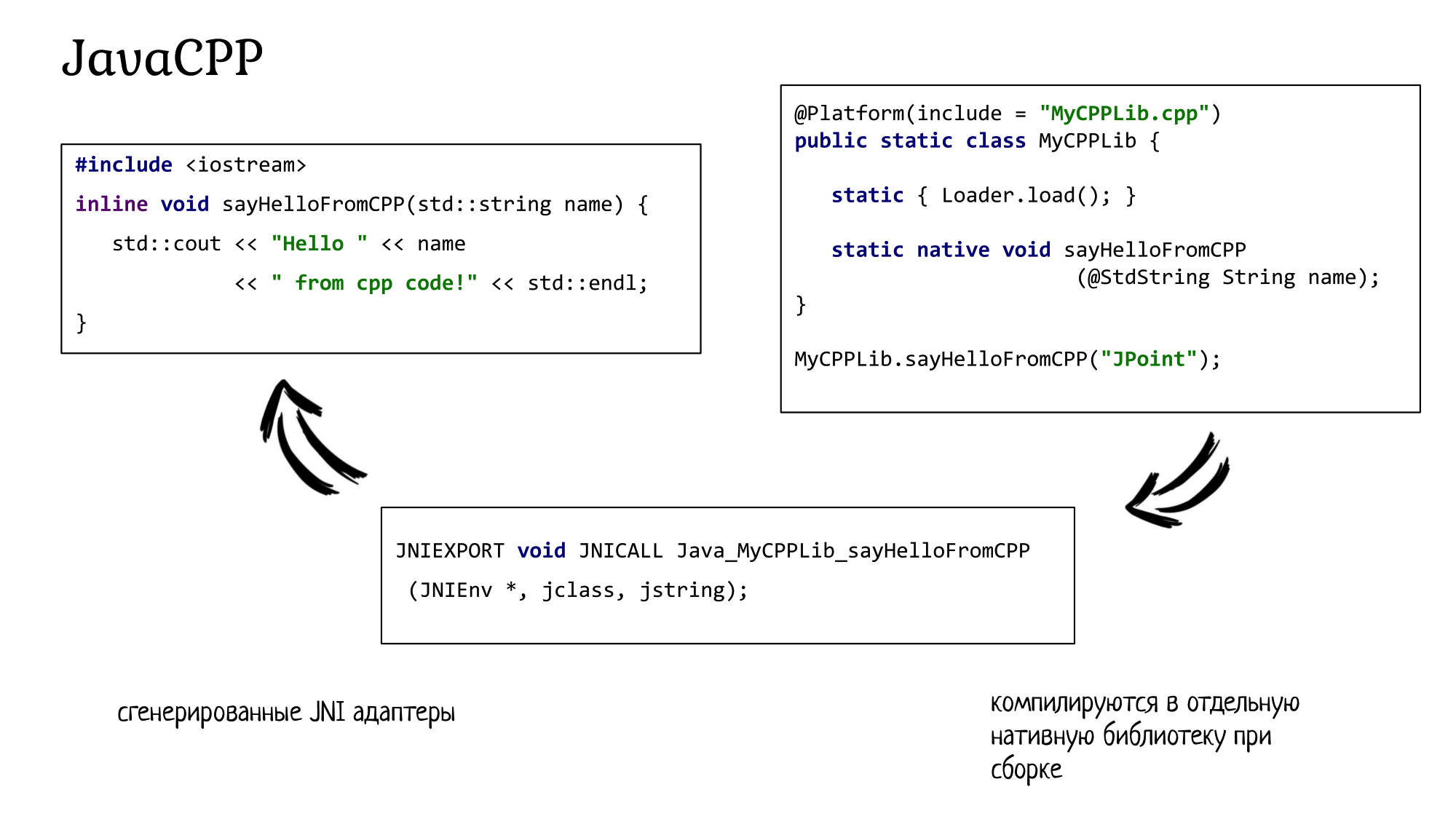
<dependency>И смело погружайтесь в чистый плюсовый код. Для примера возьмем cpp-файл, в котором написан абсолютно обычный код на C++: inline функции, std::string, стандартные потоки вывода. Опять-таки, никаких специальных макросов или команд для взаимодействия с Java, никакого вмешательства в нативный код не происходит.
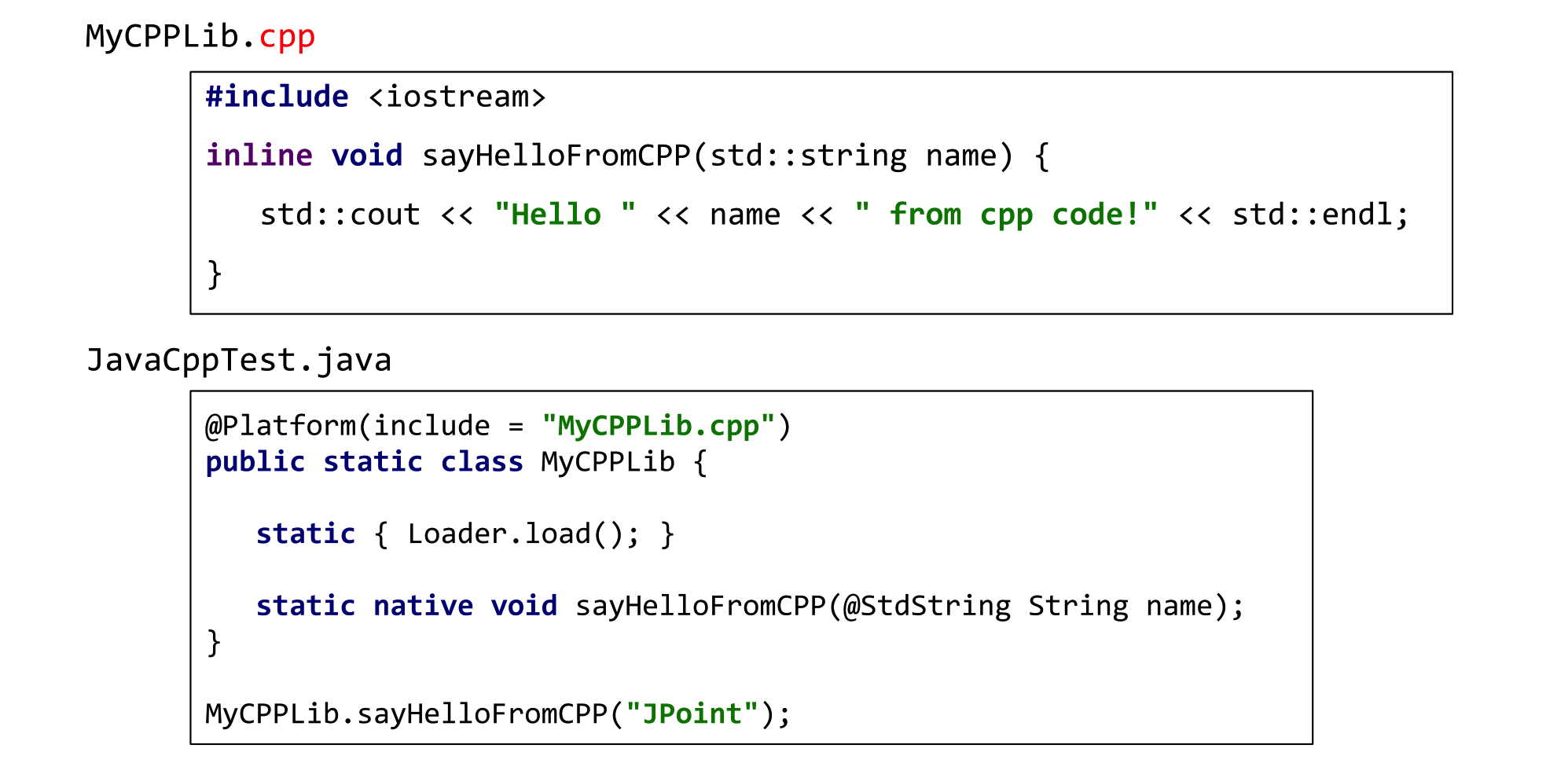
Со стороны Java заводите очередной класс и указываете, что он маппится на файл MyCPPLib.cpp. В этот раз все-таки пишете нативный метод sayHelloFromCPP, но в качестве аргумента с помощью аннотации указываете, что речь идет о плюсовой std::string. Вызываете этот метод — и вы абсолютно беспрепятственно попадаете уже в плюсовый код из Java!
Как обычно, нам не очень интересно вызывать тривиальные методы: для реальной работы мы хотим вызывать сложный плюсовый код, наполненный различными фичами, характерными для этого языка. И JavaCPP спешит на помощь: эта библиотека позволяет работать с плюсовыми классами, перегрузкой операторов, деструкторами и конструкторами, шаблонами и даже умными указателями на стороне Java. Конечно, все огромное множество фич из C++ в Java затащить невозможно, но JavaCPP очень старается сделать это по максимуму.
Далее, JavaCPP предлагает действительно впечатляющее количество заготовленных оберток для различных C++ библиотек. Если же чего-то не хватает, то новую обертку легко сгенерировать самостоятельно, вот здесь есть подробная инструкция, как это сделать.
Наконец, собирать проекты с JavaCPP — одно удовольствие. Вы просто добавляете в свой maven или gradle-конфиг соответствующие таргеты, после чего все, включая нативную часть, автоматически собирается под необходимую вам платформу. Не нужно больше гуглить, как собрать нативную библиотеку, чтобы она была совместима с JNI — все работает из коробки.
Где же подвох?
Конечно, вас мучает вопрос, что там с производительностью, особенно на фоне остальных фреймворков?
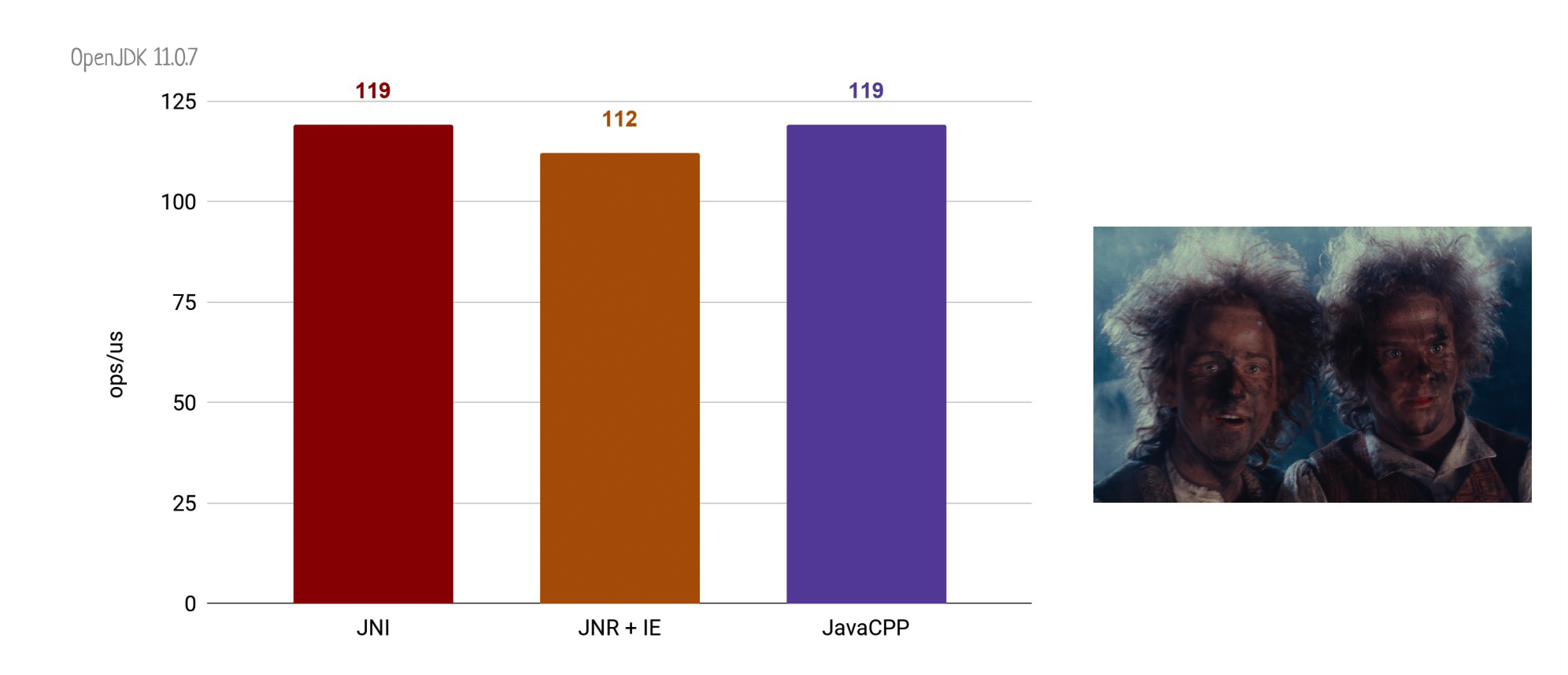
Итак, JavaCPP вновь базируется на JNI, так что быстрее нашей верхней границы точно прыгнуть не получится. Но если посмотреть на то, как здесь реализована связь с нативным кодом, то окажется, что все не так страшно.
Действительно, мы ведь все-таки объявили на стороне Java нативный метод, поэтому все, что остается сделать JavaCPP — так это сгенерировать маленькую сишную заверточку, с JNIEXPORT, JNICALL и всем таким прочим, которая уже будет напрямую вызывать ваш плюсовый код.
В результате мы получаем всего один дополнительный уровень косвенности, а
накладные расходы на вызов пустого С++ метода через JavaCPP вообще сравнимы с вызовом обычного натива через JNI.
Но не стоит терять голову! Как только мы хоть немного усложняем вызываемый метод, да хотя бы даже вызываем все еще пустой, но уже instance метод C++ класса, то сразу получаем серьезную просадку производительности.
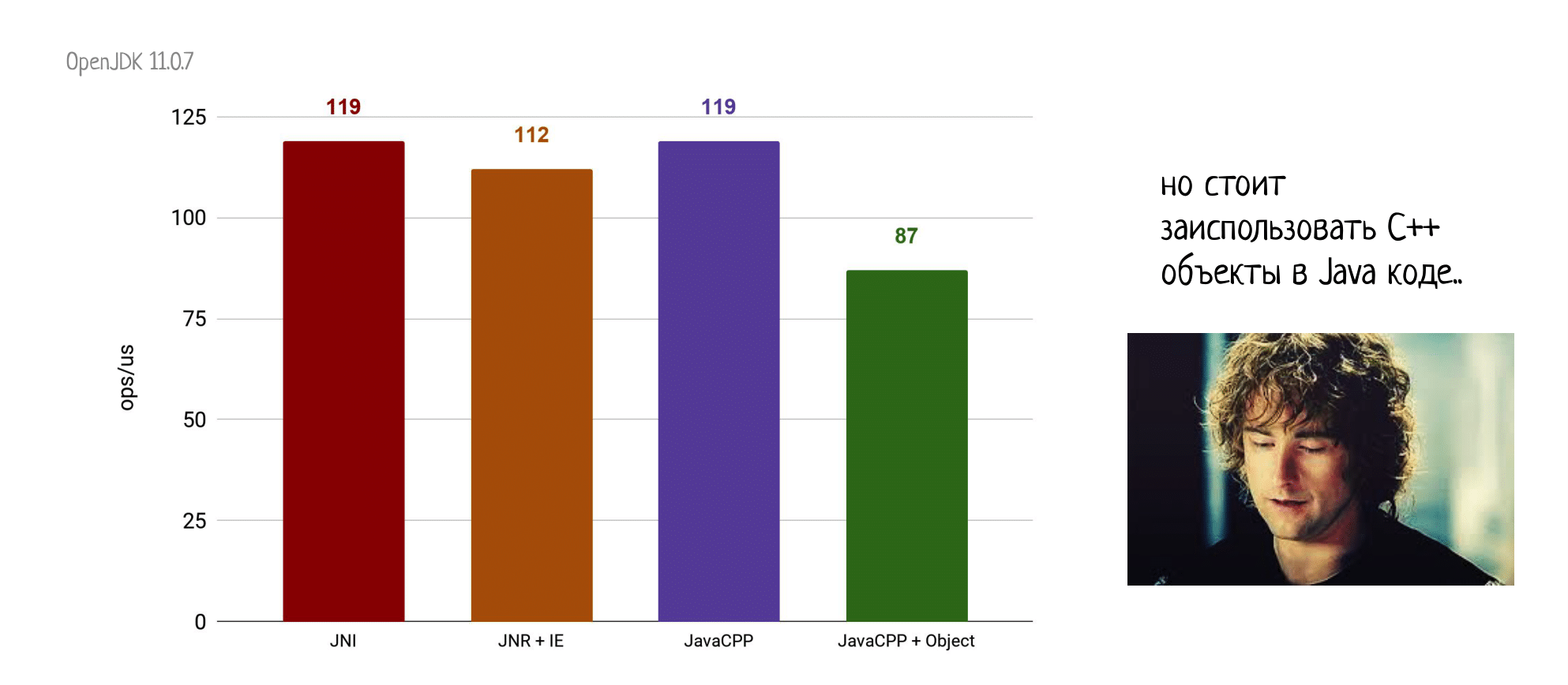
И, к сожалению, это тенденция — чем больше C++ сущностей и фич мы затаскиваем на сторону в Java, тем медленнее всё это будет работать.
Кроме этого, не все плюсовые фичи вообще можно однозначно представить в Java. Вот что, например, делать с деструкторами и умными указателями? В Java нет аналогичной функциональности, поэтому придется ее как-то симулировать. К счастью, создатели JavaCPP делают это не с помощью финализаторов, но используют более надежные фантомные ссылки и ReferenceQueue. Тем не менее, это тоже вводит недетерминированность в исполнение вашего кода, и на самом-то деле сильно меняет его семантику по сравнению с C++. Чем больше подобных фич вы будете использовать на стороне Java, тем сложнее будет предсказать поведение вашей программы и больше будет шанс, что что-то пойдет не так (привет JNA с его спорадичными развалами).
Итоги по JavaCPP
Резюмируя все про JavaCPP, обновляем нашу табличку: за удобство использования JavaCPP получает твердую пятерку; производительность и надежность ок, но и то, и то ухудшается при использовании большего количества плюсовых фич; заготовки для библиотек выше всяческих похвал.
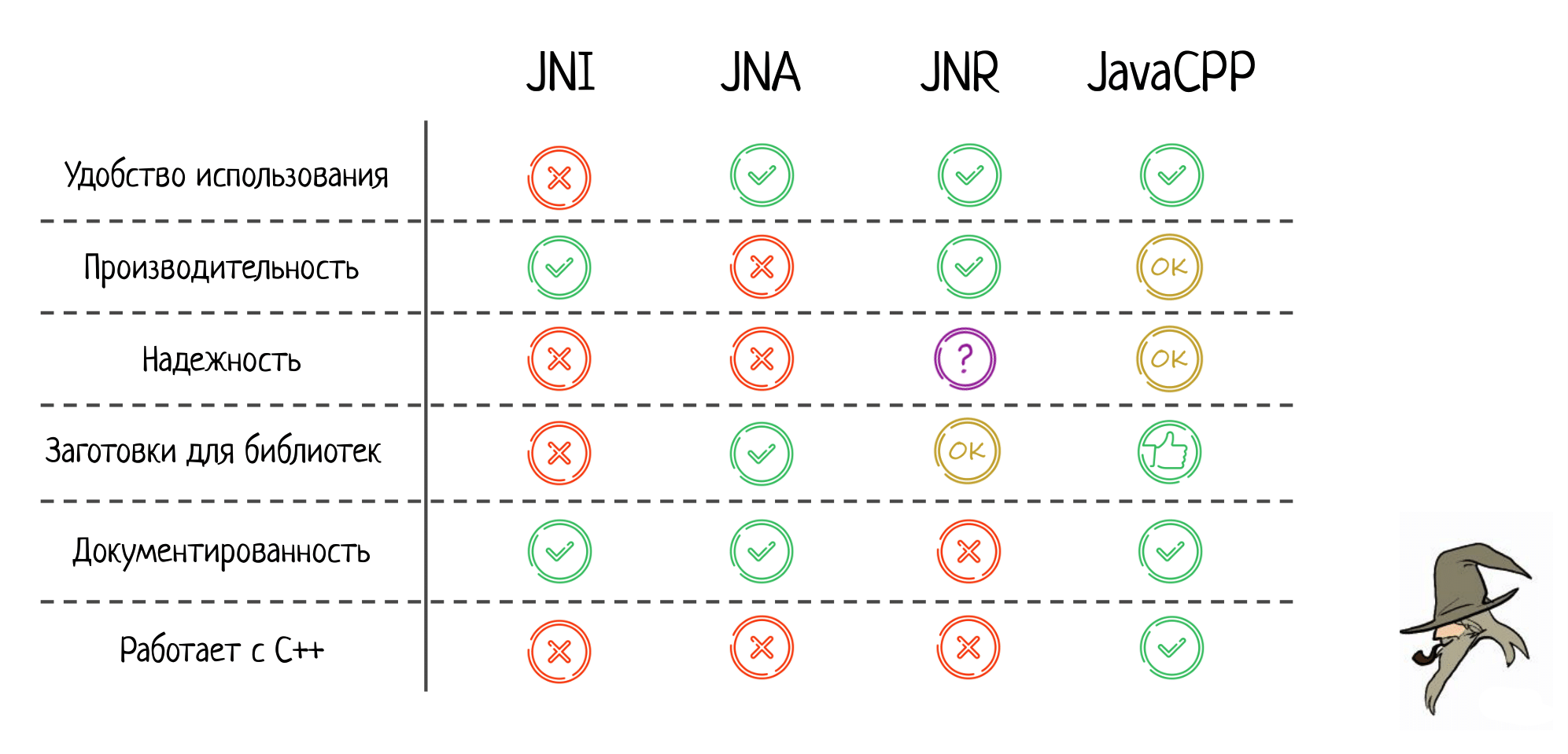
Документация хорошая: есть вики, гайды, приятно этим пользоваться. И конечно — JavaCPP замечательно работает с C++. Именно после анализа этой библиотеки становится понятно, почему всем остальным претендентам я за это поставил минусы.
Что будет дальше
Завершая свой рассказ, я предлагаю вам заглянуть в ближайшее будущее и разобраться, как там предлагается решать проблемы связи Java с нативным кодом.
Project Panama
В первую очередь, речь пойдем о знаменитом Project Panama. Это мегапроект в OpenJDK, который разрабатывает вот уже 6 лет. Главная его цель — добиться легкого использования C/C++ кода и библиотек из Java, чтобы это было настолько же удобно для Java-программиста, как и писать обычный Java-код.
В основе Panama лежит уже хорошо известная нам идея: давайте не будем заставлять людей писать на C/C++, а вместо этого обогатим язык Java настолько, чтобы все связанную с нативным кодом работу можно было бы выразить на Java (и из сложного взаимодействия с нативным кодом останется только сам вызов натива).
При этом проект Panama состоит из нескольких больших частей:
Первая — Memory Access API. Он уже сейчас в качестве incubator-модуля входит в Java 15, поэтому вы прямо сейчас можете его попробовать и оставить свой фидбэк. Это новый API для работы с нативной памятью и потенциальная замена ByteBuffer.
Но нам больше интересна вторая часть — новый FFI (Foreign Function Interface), который предлагает абсолютно альтернативную технологию вызова нативных методов. Для этого предлагается использовать новую технологию Native Method Handles. Если же вам при этом нужно поработать с чем-то низкоуровневым типа указателя — для этого используются MemorySegment из того самого Memory Access API, который уже есть в Java.
И, наконец, если у вас есть какая-то готовая библиотека или просто C-код, то можно с помощью специального инструмента jextract сгенерировать Java-обвязку, через которую и вызывать потом нативные методы. Выглядит это как-то так.

В этом простеньком примере есть два нативных метода и .h-файл с их заголовками. Запускаем jextract и получаю целую директорию .class-файлов, которые добавляем к нашему проекту. Наиболее интересен для нас сейчас panamatest_h.class файл.
Вот какой .java код мог бы этому файлу соответствовать:
panamatest_h.java
package org.sample;
public final class panamatest_h {
public static MethodHandle test$MH() {
return panamatest_h$constants.test$MH();
}
public static void test () {
try {
panamatest_h$constants.test$MH().invokeExact();
} catch (Throwable ex) {
throw new AssertionError(ex);
}
}
…
}
Есть метод, который вам вернет MethodHandle, соответствующий нативу test, и даже называющийся точно так же Java метод test, который, собственно, и вызывает натив через этот MethodHandle.
Давайте же пробовать! Нас в первую очередь интересует производительность, ведь Panama наконец-то не ограничен JNI, т.к. это абсолютно новая технология, созданная с нуля. А значит, цифры могут нас приятно удивить.
Проводим наш классический эксперимент: вызываем из Java пустой натив через JNI и получаем 119 попугаев. Повторяем эксперимент, но уже на сборке c JDK с Panama, где мы можем воспользоваться Native Method Handle и… уже получаем 124 попугая!
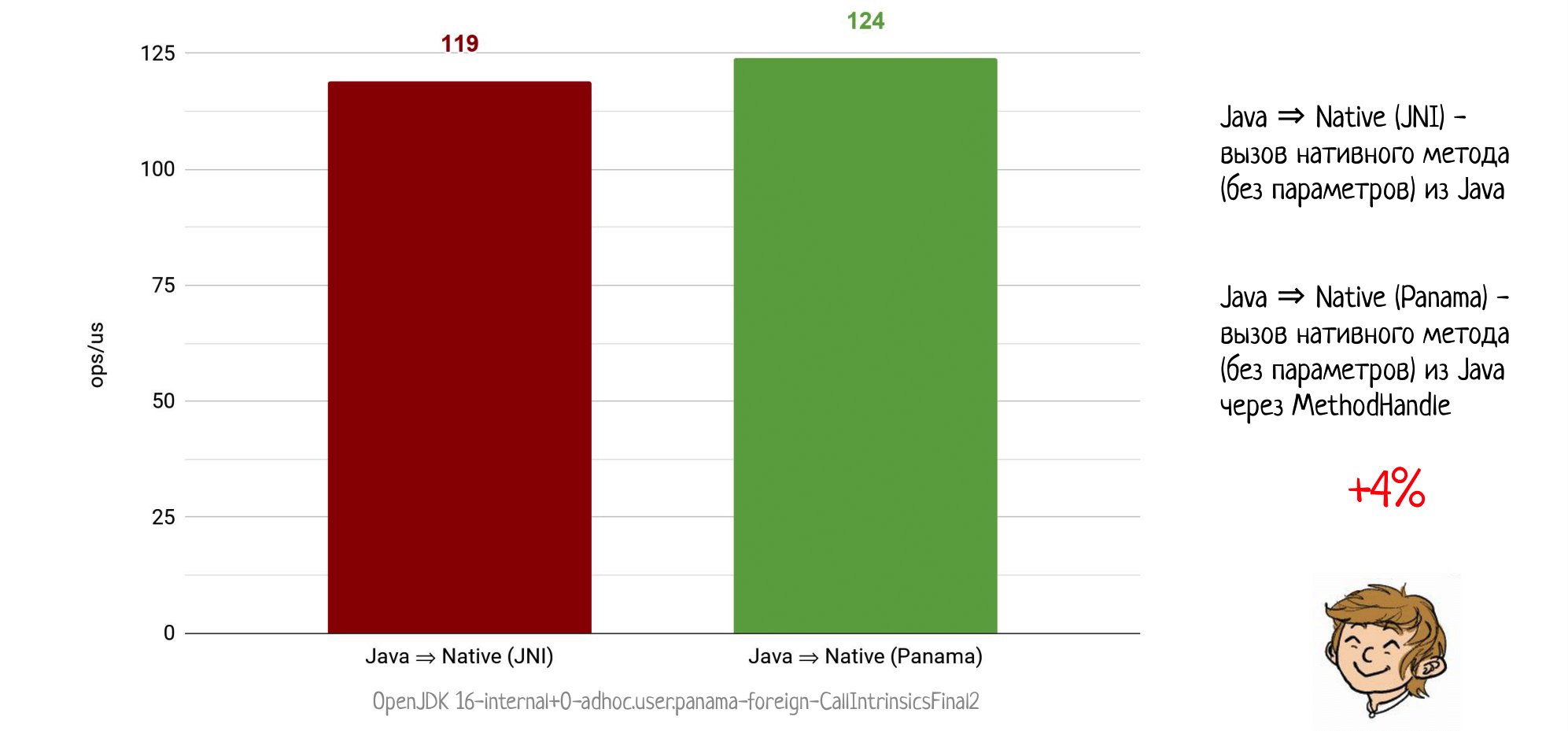
Может показаться, что это не так много, но вдумайтесь: мы никогда раньше не могли обогнать JNI, ни в какой конфигурации. И вот принципиально новая технология уже даёт прирост в 4%. Более того, буквально в этот момент продолжаются работы по разгону нативных вызовов в Panama, так что 4% сегодня легко могут превратиться в 20% завтра. Следите за обновлениями!
И как будто этого мало, в Panama обсуждают принципиально новую фичу: так называемые небезопасные нативные вызовы. В отличие от обычных, вызовы таких нативных методов не работают параллельно со сборкой мусора, а наоборот — блокируют её.
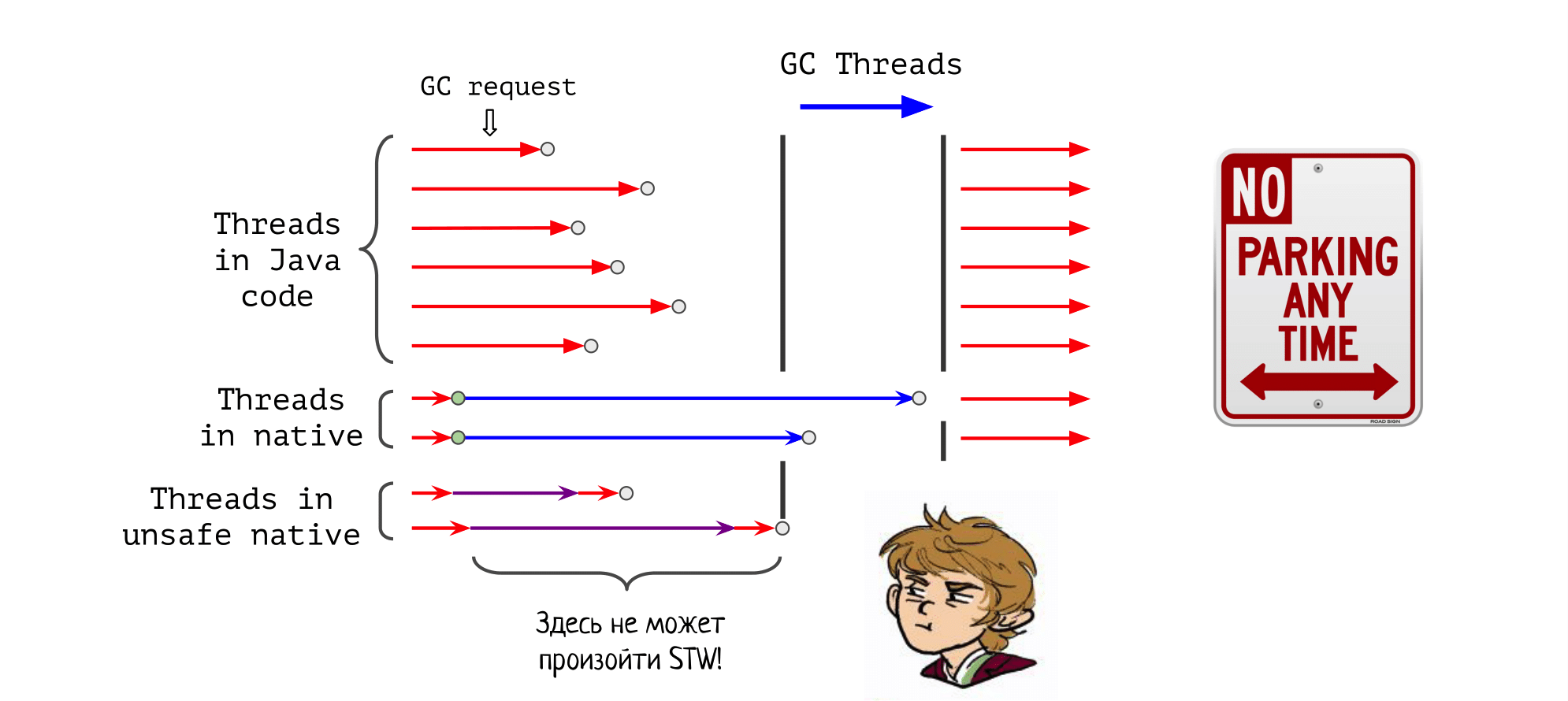
На нашей картинке из прошлого поста с потоками исполнения во время GC появляются новые действующие лица: потоки, которые исполняют нативный код, но никак не пытаются синхронизироваться со сборщиком мусора. Они не говорят ему, что ушли в нативный код, на выходе не ставят safepoint, ничего такого.
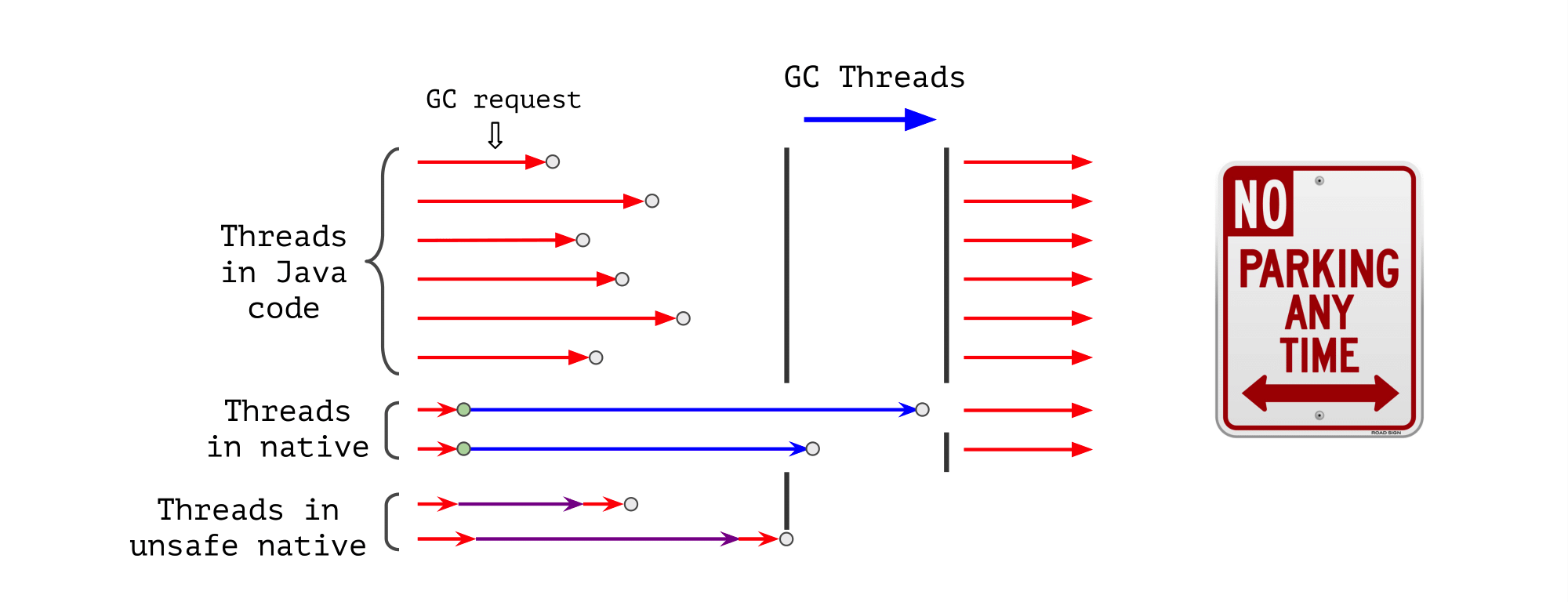
Мы просто уходим в нативный код, а чтобы пособирать мусор, GC вынужден ждать, пока мы оттуда вернемся.
Понятно, что эта технология очень опасная: если мы остаемся в таком нативе слишком надолго (например, зависнув там на семафоре), то приход GC будет отложен на неопределенный срок, что может привести к OOM или просто дедлоку внутри JVM.
Зато для легковесных нативных методов, из которых вы почти сразу возвращаетесь, вы можете получить вот такие цифры:
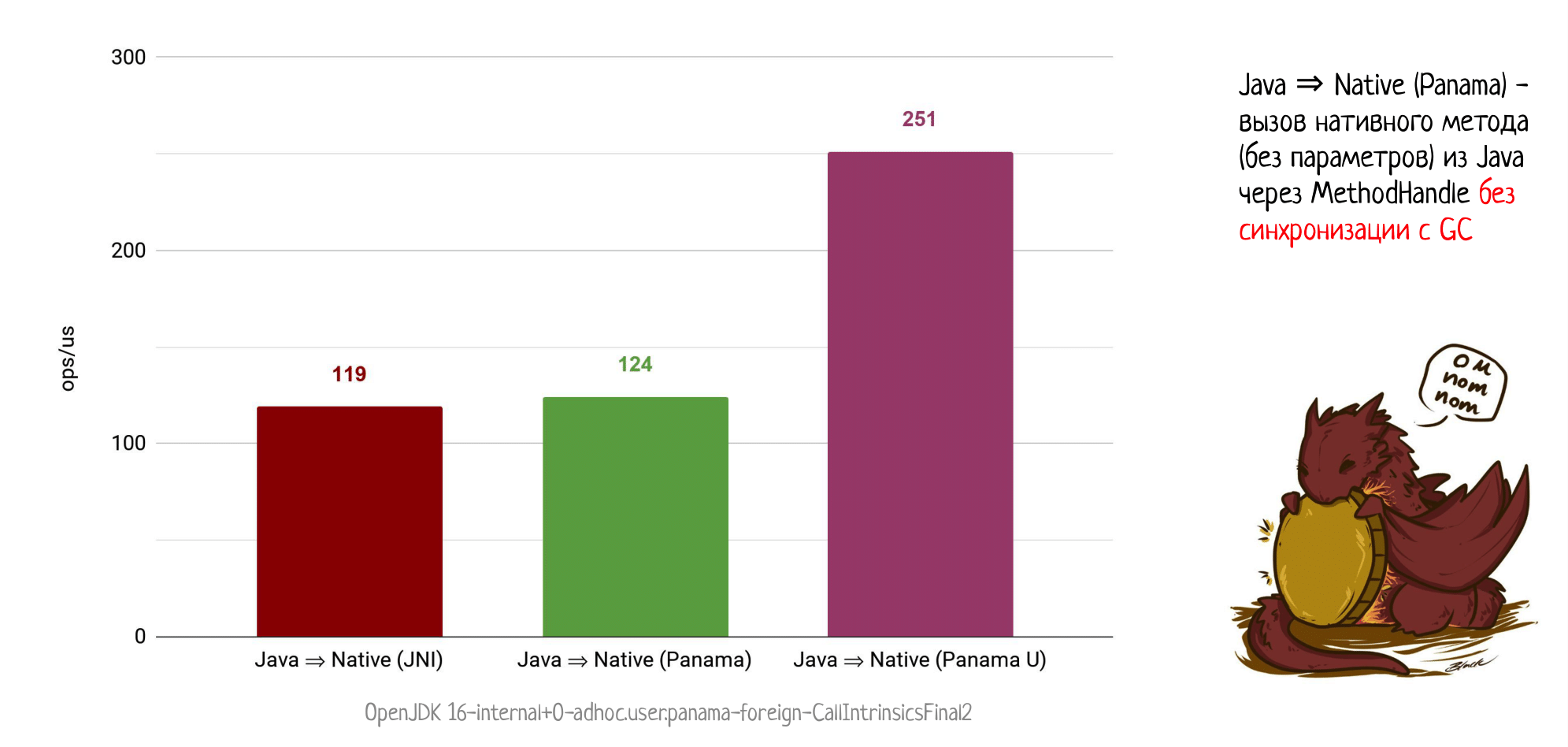
В два раза лучше, чем просто вызов через Panama или через JNI. И это, конечно, та самая производительность, которой и хочется достигнуть — фактически стоимость самого вызова, без всякой подготовительной работы.
Еще раз обращаю ваше внимание, что это максимально экспериментальная фича (чтобы ее опробовать, мне понадобилось собирать кастомный билд OpenJDK из актуальных на июнь 2020 года рабочих веток). Поэтому, как конкретно мы сможем это использовать — пока непонятно. Вероятнее всего, все сгенерированные jextract-ом методы будут вызывать только безопасные нативы, но при этом будет возможность явно указать, вот этот натив можно вызывать без синхронизации с GC.
На этом мы заканчиваем наш экспресс-обзор проекта Panama, если хотите узнать больше, то есть два отличных доклада Владимира Иванова (раз, два) на эту тему, а также расшифровка одного из докладов в качестве поста.
Осталось добавить Panama в нашу табличку:
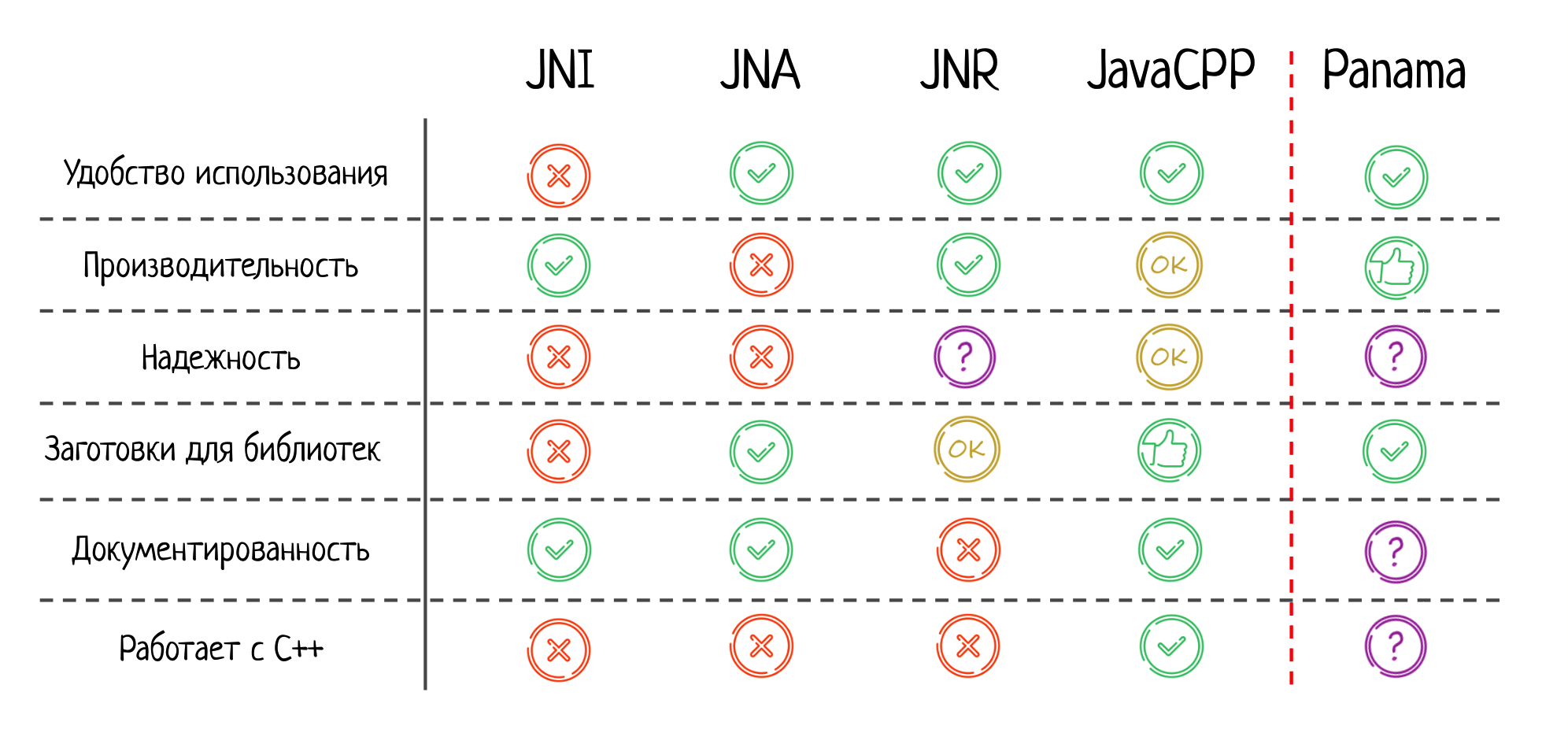
Удобство — на пятёрку, спасибо jextract; производительность — лучше, чем всё остальное, включая JNI. Про надёжность пока ничего сказать не можем, но будем надеятся, что все будет предельно безопасно.
Заготовки для библиотек уже есть, их создают с помощью jextract и проверяют, всё ли хорошо работает. Документация присутствует, но я замечу, что она очень быстро устаревает. Это нормально, ведь Panama сейчас бурно развивается, так что подождем-увидим, какая документация появится в конце.
С C++ Panama пока не работает, хотя такие планы у Oracle имеются. Опять-таки, будем ждать обновлений.
А если полететь в Мордор на орлах?
Теперь давайте обсудим абсолютно альтернативный подход к взаимодействию с нативным кодом из Java. Мы все время искали безопасную тропинку из Шира в Мордор, но, может, стоило сразу сесть на орлов и лететь к Роковой горе, чтобы скинуть туда кольцо?
Я, конечно же, говорю про еще один известный проект — GraalVM. Более конкретно — про его подпроект Truffle Framework, который позволяет создавать интерпретаторы для различных языков, запускать их на JVM и максимально агрессивно специализировать, получать достойную производительность, сравнимую с нативными реализациями.

Так делают для JS, Python, Ruby и многих других языков. Но что сейчас интересует именно нас, так это применение такого же подхода к нативным языкам, чем занимается подпроект GraalVM LLVM Runtime или Sulong.
Идея здесь следующая: давайте скомпилируем C/C++/Rust-код в LLVM bitcode. Для этого запустим сlang и получим файл с биткодом.

После этого давайте начнем его исполнять с помощью интерпретатора, как раз реализованного в проекте Sulong. Благодаря специализации кода этого интерпретатора в рантайме мы должны получить приличную производительность.
Со стороны Java всё выглядит довольно прозрачно: подключаем импорты из graalvm.polyglot, считываем файл с биткодом, указываем, что собираемся интерпретировать llvm-биткод, и находим функцию goNative из нашего нативного кода. Затем вызываете её с помощью executeVoid. Компилируем и запускаем этот пример на GraalVM (в моем случае Community Edition).
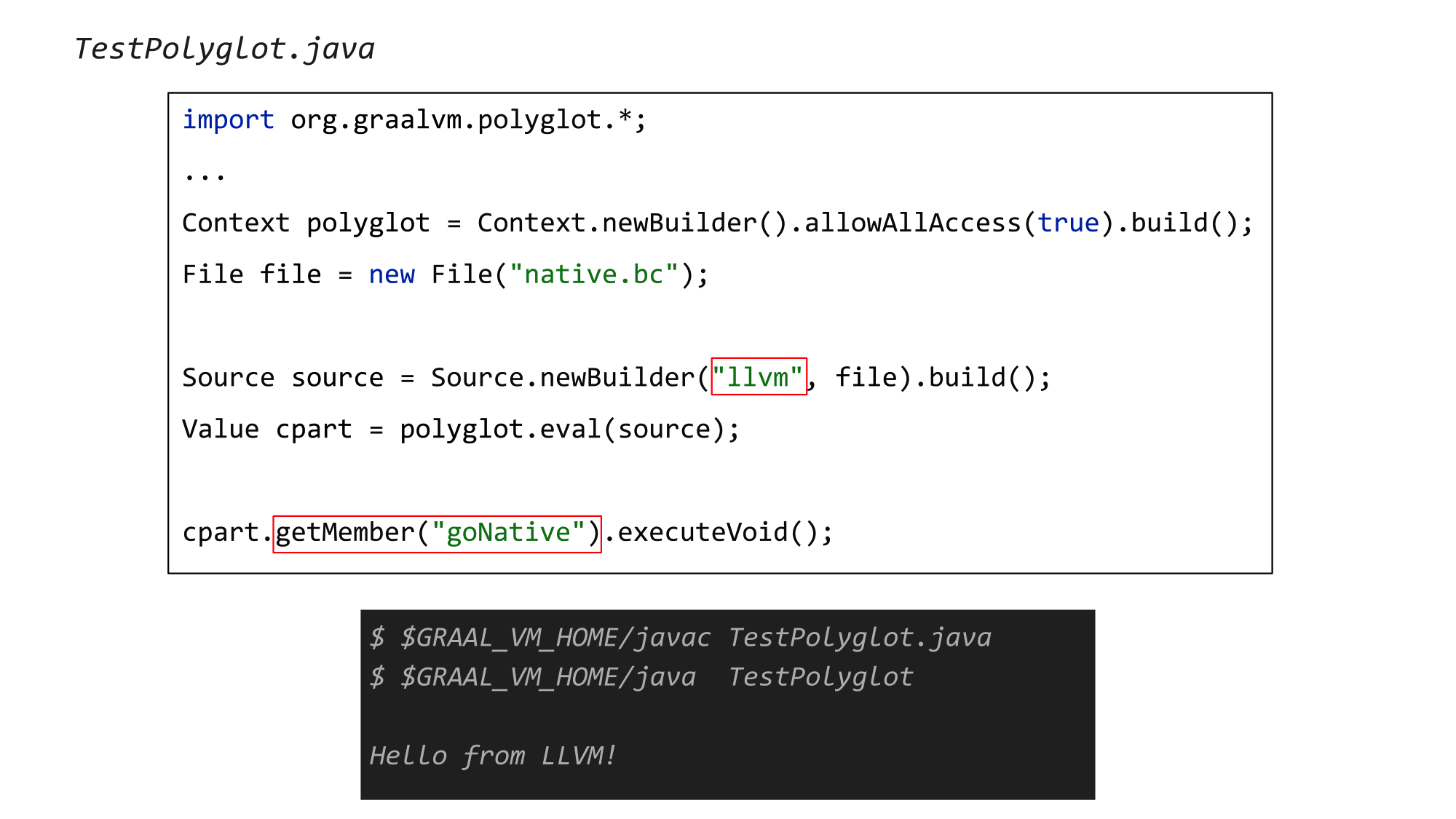
Всё опять заработало! Казалось бы, чего уж тут такого: в очередной раз перешли в нативный код из Java… но на самом деле данный подход принципиально отличается от всего, что мы делали раньше.
Дело в том, что у нас нет больше проблемы разделения, нет двух разных миров — managed и native-кода. Мы контролируем как Java-код, так и то, что вы интерпретируете, то есть интерпретируемый нативный код. И это революционный подход, т.к. мы наконец получили полный контроль над кодом на C/C++. Захотим — заинлайним нативные методы, захотим — вставим safepoint, что угодно. У вас наконец-то появилось единое представление и единый мир, в котором у вас полная власть над происходящим.
Возвращаемся к примеру, где мы вызываем простой нативный метод из Java через JNI: напоминаю, что там мы получали 119 попугаев. А теперь запускаем его на GraalVM и… внезапно — 177 попугаев!
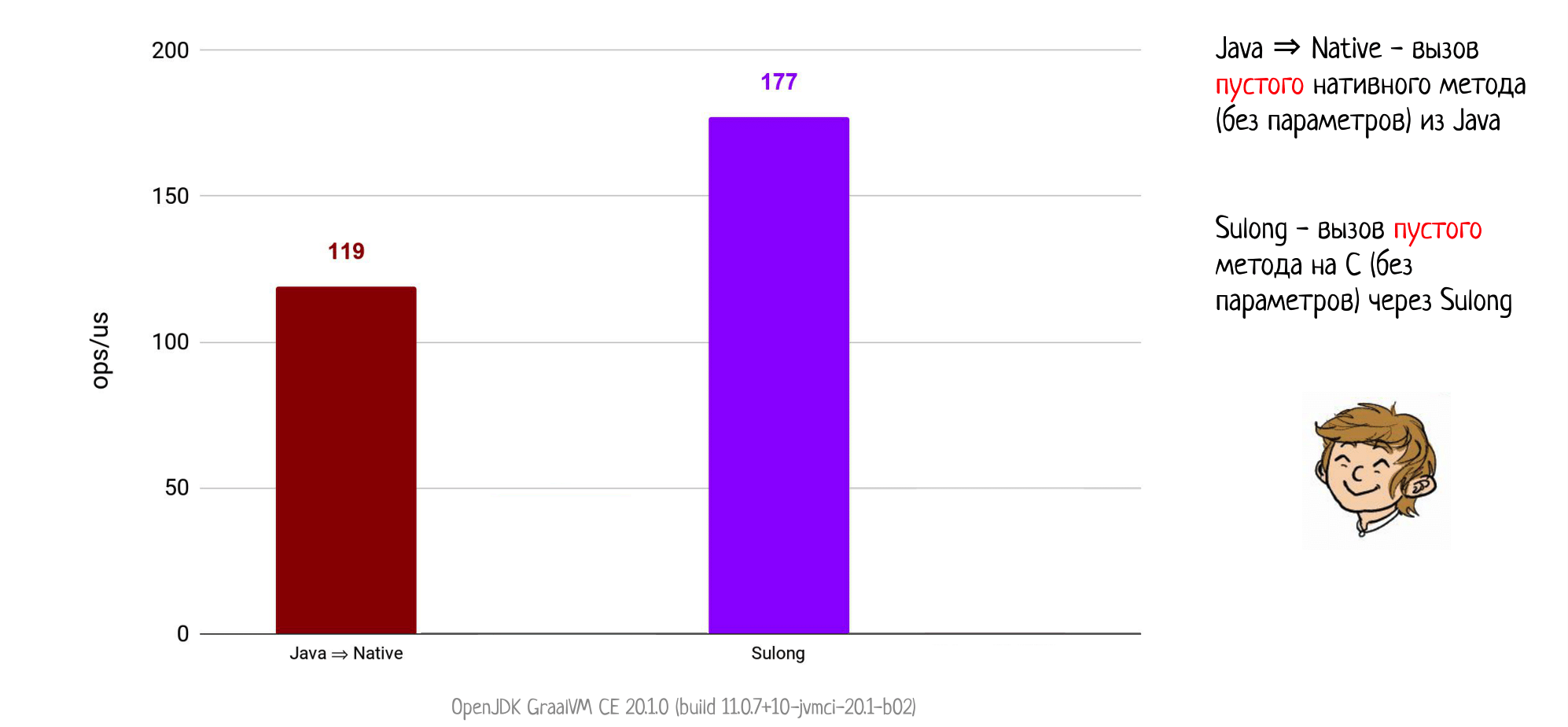
Мы только что обошли JNI посерьезнее, чем это делала Panama. Хотя, конечно, результат мог быть и еще лучше: я ожидал увидеть здесь просто бесконечную производительность, если бы мы смогли заинлайнить пустой метод при запуске на GraalVM. Но сейчас по некоторым техническим ограничениям Sulong этого не делает, в будущем, может быть, и начнет.
В любом случае, это шокирующий успех. Однако, снова возьмем себя в руки и проведем еще один уточняющий эксперимент. Раньше мы мерили только издержки на сам вызов, но в случае Sulong нам нужно померить кое-что еще.
Давайте усложним наш нативный метод и что-нибудь начнем в нём делать. Например, мы будем считать число Фибоначчи, обычная история для компиляторных тестов.

Сначала померим вызов такого нативного метода через JNI. Понятно, что мы получаем просадку производительности (мы же начали что-то делать внутри). Конкретно для этого примера производительность падает в 2.5 раза.
Теперь компилируем этот метод в биткод, запускаем на Sulong и… получаем просадку уже в 5 раз, при этом начинаем существенно проигрывать вызову через JNI.
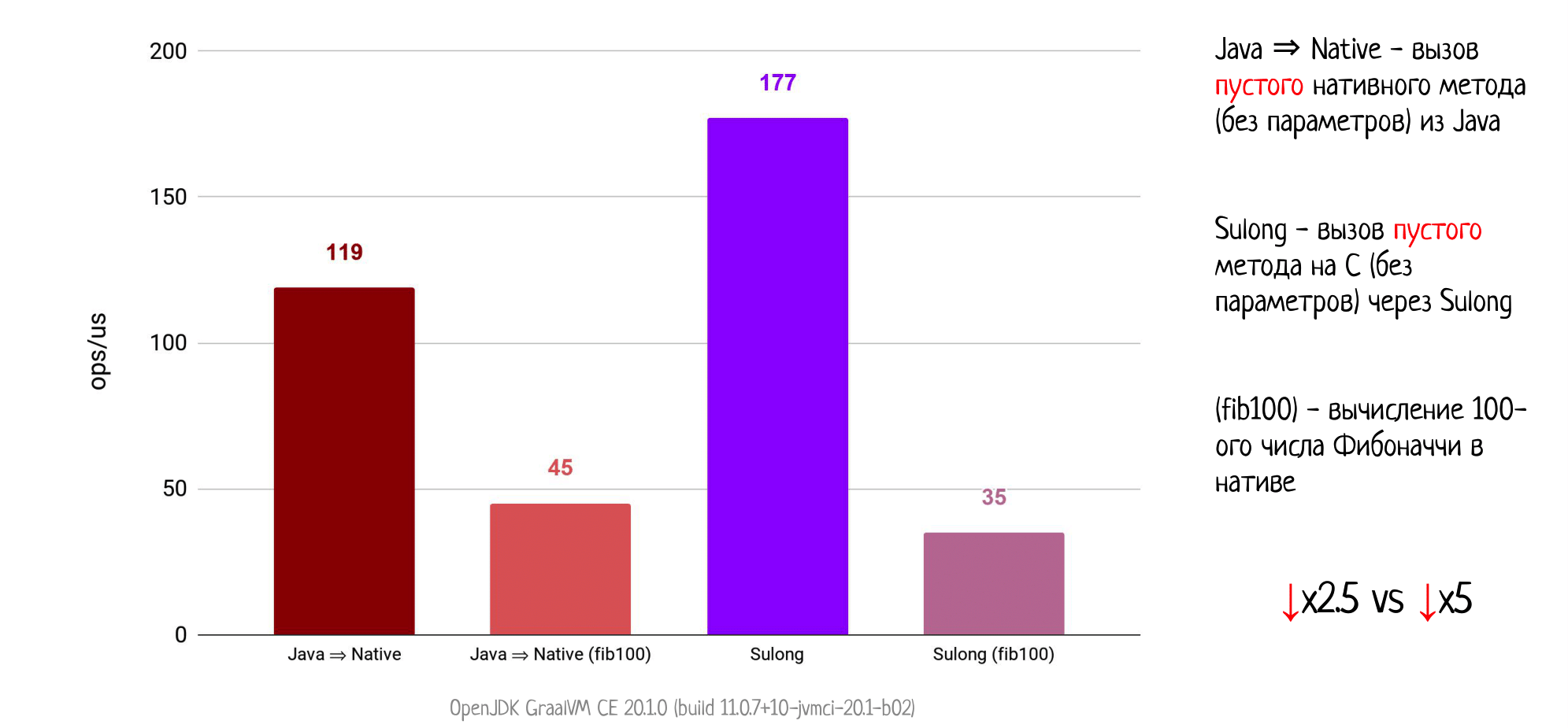
На самом деле такой результат вполне ожидаем: ведь здесь мы получаем соревнование производительности — интерпретатор (пусть даже максимально агрессивно специализированный) против скомпилированного кода. Такую конкуренцию очень сложно выдержать, что и демонстрирует наш пример. Это вполне нормально.
Более того, это показывает нам, когда есть смысл использовать Sulong для связи с нативным кодом, а когда — нет.
Если у вас есть маленькие, но частые переходы в натив, где вы чуть-чуть что-то делаете, а потом сразу возвращаетесь, то Sulong — ровно то, что вам нужно. Даже сейчас он даст прирост производительности, а уж в будущем разница может быть просто гигантской, например, если заработает инлайн C-кода в Java.
С другой стороны, если появляется тяжеловесный метод, сложный код на C, то будьте готовы, что производительность значительно упадет. К тому же, Sulong долго «прогревать», нужны тысячи и десятки тысяч итераций, чтобы сработали мощные оптимизации и специализация кода.
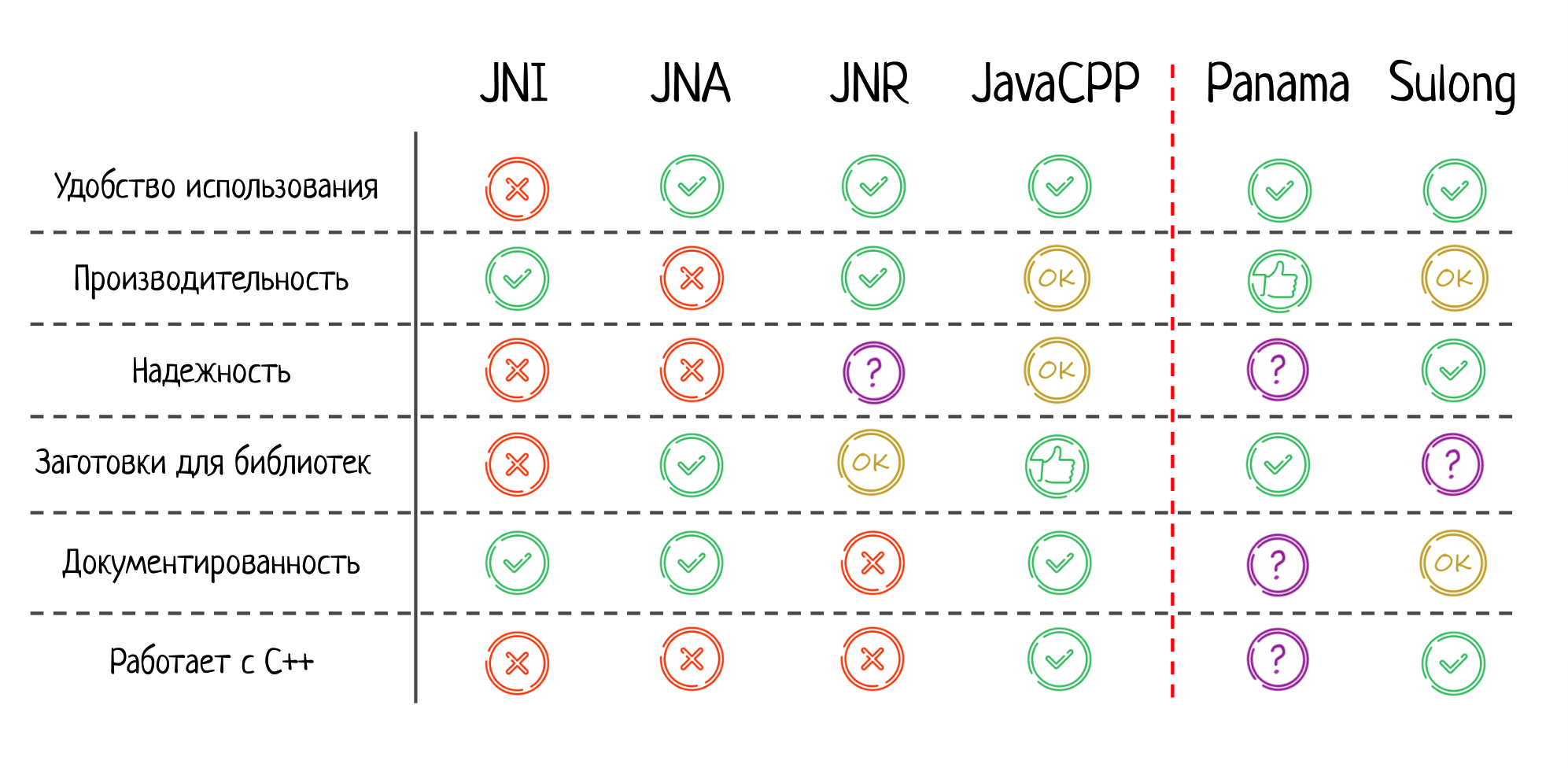
Заполняем нашу табличку для Sulong, здесь будет несколько важных вещей.
Удобство использования — ок. Почему не высший балл? Дело в том, что Sulong не пытается позволить вам вызывать любой нативный код. Например, нельзя передавать структуры по значению или возвращать их из функций. Т.е. на самом деле есть некое подмножество С/C++, с которым можно легко взаимодействовать.
Как по мне — это правильный подход, потому что все остальные фреймворки гнались за полнотой интеропа, но теряли в качестве. Именно поэтому только Sulong получает плюс за надёжность. Да, пусть именно в таком урезанном интеропе, но получить ошибку здесь будет сложнее, чем где-то еще.
Как уже обсуждалось выше, производительность зависит от сценария, поэтому тоже ставим «ок».
Второй важный момент — это заготовки для библиотек. Если у вас есть библиотека полностью в биткоде — магия сработает, граница между native и managed-кодом будет стерта. Но! Если это внешняя библиотека, скомпилированная в обычный нативный код, то любой вызов из нее будет выглядеть как классический вызов натива через JNI. В результате вы даже можете получить просадку в производительности — т.к. количество нативных вызов может возрасти. При этом не совсем понятно, как Sulong будет с этим бороться, так что ставим здесь вопросительный знак.
Документация ок, но могло быть и лучше, и, да — это работает с С++, пусть и в некотором урезанном виде.
Пара финальных мыслей
Во-первых, я бы не советовал пытаться реализовывать сложное взаимодействие с Java через JNI. В этой технологии слишком уж многое зависит от человеческого фактора: шаг влево, шаг вправо, и вас сжирает горный тролль.
Во-вторых, если вы собрались в Мордор, то помните, что туда есть множество разных дорог. В зависимости от ваших требований, вам подойдет тот или иной фреймворк или технология. Надеюсь, что в выборе вам поможет моя табличка и этот пост.
В-третьих, с исследовательской точки зрения взаимодействие native и managed-кода — это все еще чертовски интересный и открытый вопрос. Непонятно, какой из подходов победит: может быть, Panama станет всеобъемлющей технологией, которая закроет все нужды, а может, Sulong станет настолько быстрым, что трудно будет устоять — узнаем в ближайшем будущем. Пока что предлагаю просто следить за развитием этих технологий, ведь это мало того, что полезно, но еще и просто интересно.
И наконец, весь доклад (и эти два поста) мы мерялись различными бенчмарками, давайте же выведем общий рейтинг! Каждое измерение — это вызов пустого нативного метода без параметров. Побеждает вызов «небезопасного» нативного метода через Panama (но помните, что это очень рискованный механизм, который пока находится в стадии обсуждения и дизайна).

Второе место неожиданно занимает обычный вызов через JNI на jdk8. Действительно, между jdk9 и jdk10 вызов нативного метода замедлился где-то в 2 раза. Это было непростое, но стратегическое решение: посчитали, что производительность других сценариев, например, многопоточного вызова нативов, важнее, а производительностью обычного вызова можно пожертвовать. Плюс, это мешало реализации некоторых фич — все подробности можно найти вот здесь.
А третье место занимает Sulong, но помните, что он быстро работает именно с легковесными нативами.
Репозиторий со всеми бенчмарками можете найти вот здесь. Если у вас будут какие-нибудь замечания или вопросы по измерениям, обязательно пишите.
На этом все, спасибо за внимание и хороших вам прогулок к Роковой Горе!
Это была расшифровка доклада с нашей июньской Java-конференции, а уже в ноябре состоится Joker. Так что если этот материал вас заинтересовал, советуем изучить программу Joker: вероятно, там для вас тоже будет немало интересного.
")
")

