
Всем привет! Меня зовут Игорь Наразин, я тим-лид команды в направлении логистики Delivery Club. Хочу рассказать, как мы строим и трансформируем нашу архитектуру и как это влияет на наши процессы в разработке.
Сейчас Delivery Club (как и весь рынок фудтеха) растёт очень быстро, что порождает огромное количество вызовов для технической команды, которые можно обобщить двумя самыми важными критериями:
- Нужно обеспечивать высокую стабильность и доступность всех частей платформы.
- Одновременно с этим держать высокий темп разработки новых фич.
Кажется, что эти две проблемы взаимоисключающие: мы либо трансформируем платформу, стараясь вносить новые изменения по минимуму, пока не закончим, либо быстро разрабатываем новые фичи без кардинальных изменений в системе.
Но нам удаётся (пока) и то, и другое. О том, как мы это делаем, и пойдет речь далее.
Во-первых, я расскажу про нашу платформу: как мы её трансформируем с учетом постоянно растущих объемов данных, какие критерии предъявляем к нашим сервисами и с какими проблемами сталкиваемся на этом пути.
Во-вторых, поделюсь тем, как мы решаем проблему поставки фич, не конфликтуя с изменениями в платформе и без лишней деградации системы.
Начнём с платформы.
Вначале был монолит
Первые строчки кода Delivery Club были написаны 11 лет назад, и в лучших традициях жанра архитектура представляла собой монолит на PHP. Он в течение 7 лет всё больше и больше наполнялся функциональностью, пока не столкнулся с классическими проблемами монолитной архитектуры.
Поначалу он нас полностью устраивал: его было просто поддерживать, тестировать и деплоить. И с начальными нагрузками он справлялся без проблем. Но, как это обычно бывает, в какой-то момент мы достигли таких темпов роста, что наш монолит стал очень опасным узким местом:
- любой отказ или проблема в монолите отразится на абсолютно всех наших процессах;
- монолит жёстко завязан на определенный стек, который нельзя менять;
- с учетом роста команды разработки вносить изменения становится сложно: высокая связанность компонентов не даёт быстро доставлять фичи;
- монолит невозможно гибко масштабировать.
Это привело нас к (сюрприз) микросервисной архитектуре — про её достоинства и недостатки уже много сказано и написано. Главное, что она решает одну из наших основных проблем и позволяет добиться максимальной доступности и отказоустойчивости всей системы. Я не буду на этом останавливаться в текущей статье, вместо этого расскажу на примерах, как мы это сделали и почему.
Наша основная проблема заключалась в размере кодовой базы монолита и слабой экспертизе команды в ней (платформу мы так и называем — old). Конечно, сначала мы хотели просто взять и распилить монолит, чтобы полностью решить вопрос. Но очень быстро поняли, что на это уйдёт не один год, причем количество изменений, которые туда вносятся, не позволят этому закончиться никогда.
Поэтому мы пошли другим путём: оставили его как есть, а остальные сервисы решили строить вокруг монолита. Он продолжает быть основной точкой логики обработки заказов и мастером данных, но начинает стримить данные для других сервисов.
Экосистема
Как рассказывал Андрей Евсюков в статье про наши команды, у нас выделены главные направления по доменным областям: R&D, Logistics, Consumer, Vendor, Internal, Platform. В рамках этих направлений уже сосредоточены основные доменные области, с которыми работают сервисы: например, для Logistics — это курьеры и заказы, а для Vendor — рестораны и позиции.
Дальше нам нужно подняться на уровень выше и выстроить экосистему наших сервисов вокруг платформы: процессинг заказов находится в центре и является мастером данных, остальные сервисы строятся вокруг него. При этом нам важно сделать наши направления автономными: при отказе одной части, остальные продолжают функционировать.
При низких нагрузках выстроить нужную экосистему достаточно просто: наш процессинг обрабатывает и хранит данные, а сервисы направлений обращаются за ними по мере необходимости.
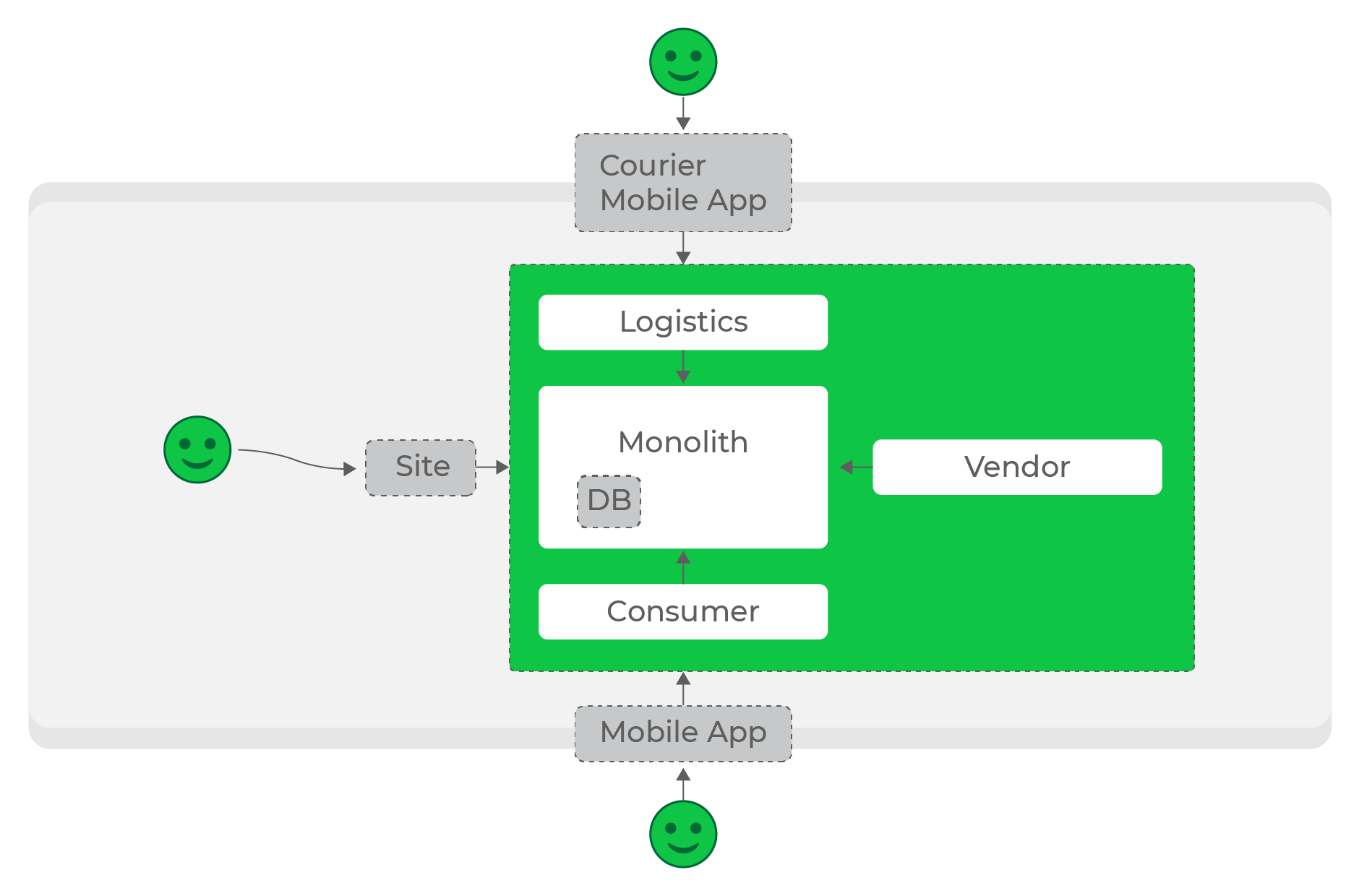 Низкие нагрузки, синхронные запросы, всё работает круто.
Низкие нагрузки, синхронные запросы, всё работает круто.На первых этапах мы так и делали: большинство сервисов общались между собой синхронными HTTP-запросами. При определенной нагрузке это было позволительно, но чем больше рос проект и число сервисов, тем большей проблемой это становилось.
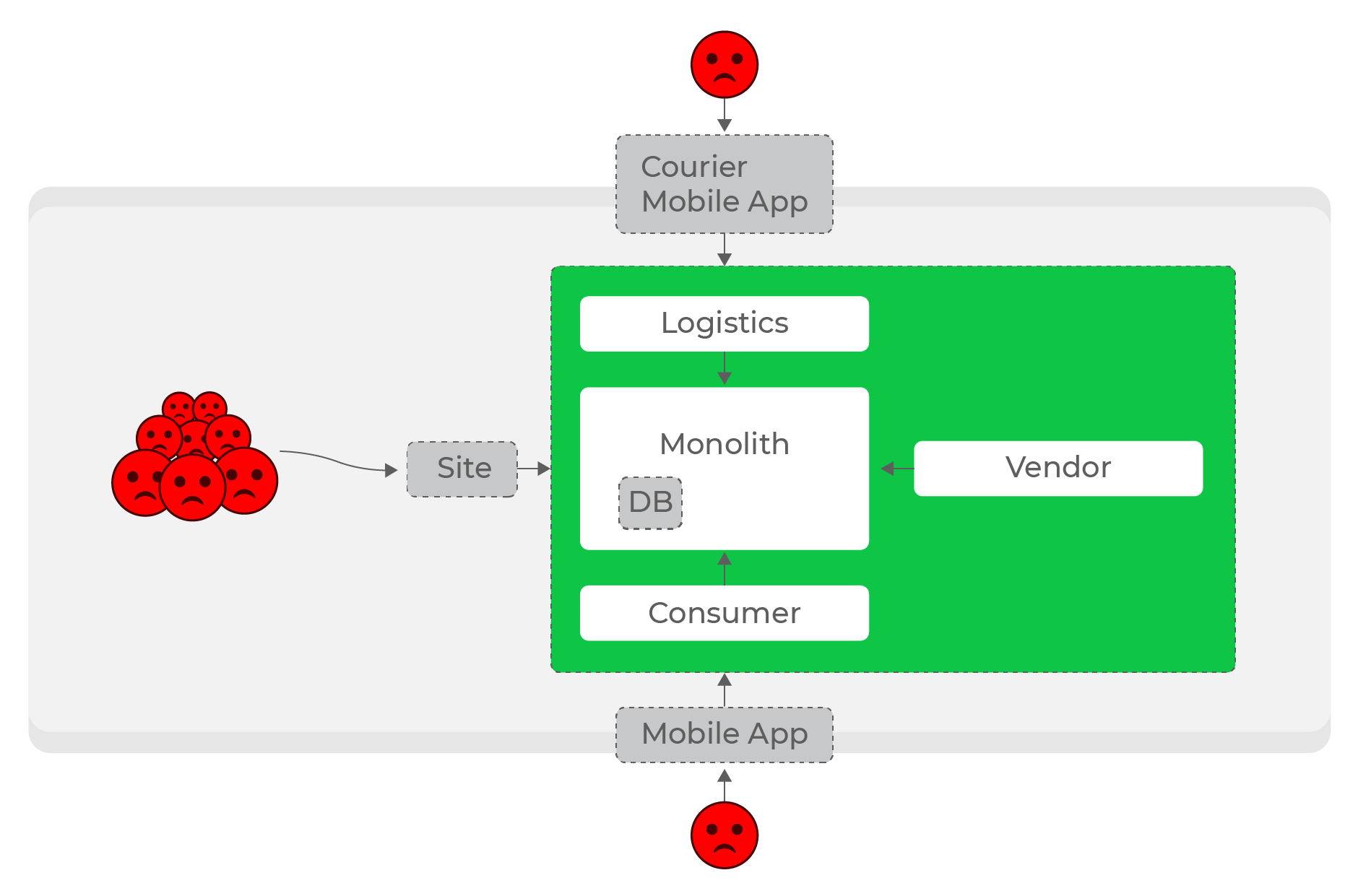
Высокие нагрузки, синхронные запросы: страдают все, даже пользователи абсолютно других доменов — курьеры.
Сделать сервисы внутри направлений автономными ещё сложнее: например, возрастание нагрузки на логистику не должно влиять на остальные части системы. С любым количеством синхронных запросов это нерешаемая задача. Очевидно, что нужно было отказываться от синхронных запросов и переходить к асинхронному взаимодействию.
Шина данных
Таким образом, у нас получилась масса узких мест, где за данными мы обращались в синхронном режиме. Эти места были очень опасными с точки зрения роста нагрузки.
Вот пример. Кто хоть раз делал заказ через Delivery Club, знает, что после того, как курьер забрал заказ, становится видна карта. На ней можно отслеживать передвижение курьера в реальном времени. Для этой фичи задействовано несколько микросервисов, основные из них:
mobile-gateway, который является backend for frontend для мобильного приложения;courier-tracker, который хранит логику получения и отдачи координат;logistics-couriers, который хранит эти координаты. Они присылаются из мобильных приложений курьеров.
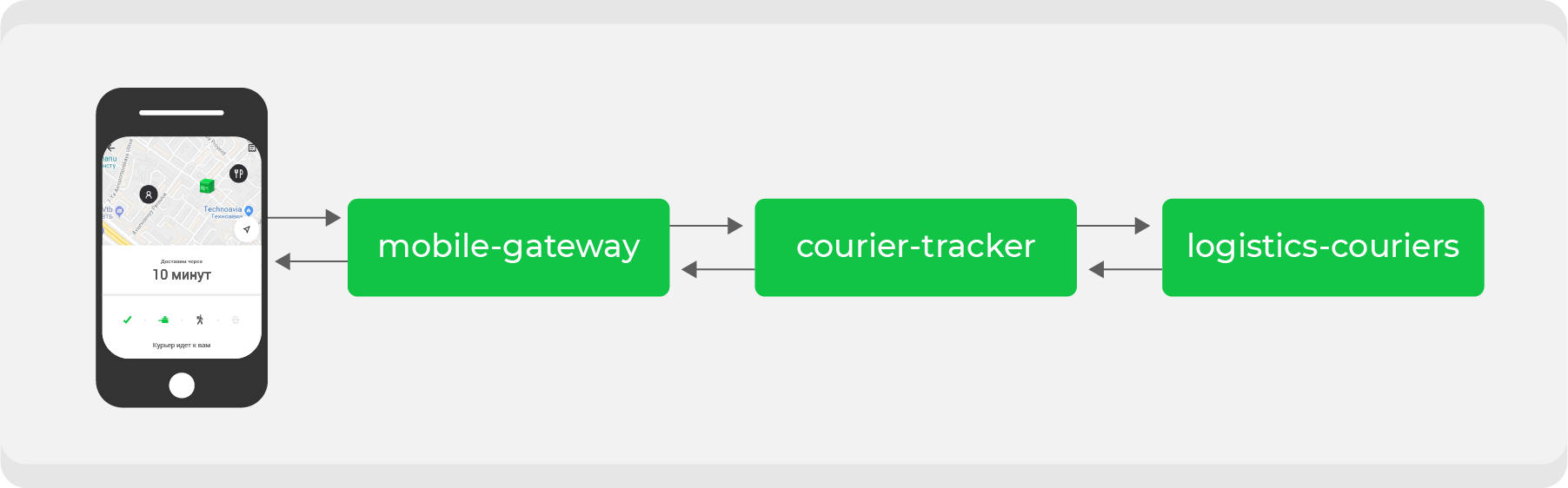
В первоначальной схеме это всё работало синхронно: запросы из мобильного приложения раз в минуту шли через
mobile-gateway к сервису courier-tracker, который обращался к logistics-couriers и получал координаты. Конечно, в этой схеме было не всё так просто, но в итоге всё сводилось к простому выводу: чем больше у нас активных заказов, тем больше запросов на получение координат приходило в logistics-couriers.Рост у нас порой непредсказуемый и, что главное, быстрый — вопрос времени, когда такая схема откажет. Значит, нужно переделать процесс на асинхронное взаимодействие: сделать так, чтобы запрос координат был максимально дешевым. Для этого необходимо преобразовать наши потоки данных.
Транспорт
Мы уже использовали RabbitMQ, в том числе для общения между сервисами. Но в качестве основного вида транспорта мы остановились на уже хорошо зарекомендовавшем себя инструменте — Apache Kafka. Про него мы напишем отдельную подробную статью, а сейчас я бы хотел кратко рассказать о том, как мы его используем.
Когда мы только начали внедрять Kafka в качестве транспорта, то использовали его в сыром виде, подключаясь напрямую к брокерам и отправляя в них сообщения. Этот подход позволил нам быстро проверить Kafka в боевых условиях и решить, использовать ли далее как основной вид транспорта.
Но такой подход имеет существенный недостаток: у сообщений нет никакой типизации и валидации — мы не знаем наверняка, какой формат сообщений читаем из топика.
Из-за этого увеличивается риск ошибок и несогласованностей между сервисами, которые являются поставщиками данных, и теми, кто их потребляет.
Для решения этой проблемы мы написали обёртку — микросервис на Go, который скрыл Kafka за своим API. Это добавило два преимущества:
- валидация данных в момент отправки и приёма. По сути, это одни и те же DTO, поэтому мы всегда уверены в формате ожидаемых данных.
- быстрая интеграция наших сервисов с этим транспортом.
Таким образом, работа с Kafka стала максимально абстрагированной для наших сервисов: они лишь работают с верхнеуровневым API этой обёртки.
Вернёмся к примеру
Переводя синхронное взаимодействие на шину событий, нам необходимо инвертировать поток данных: то, за чем мы обращались, должно теперь само попадать к нам через Kafka. В примере речь идёт о координатах курьера, для которых теперь мы заведём специальный топик и будем продюсить их по мере получения от курьеров сервисом
logistics-couriers.Сервису
courier-tracker остаётся аккумулировать координаты в нужном объёме и на нужный срок. В итоге наш эндпоинт становится максимально простым: взять данные из базы сервиса и отдать их мобильному приложению. Рост нагрузки на неё теперь для нас безопасен.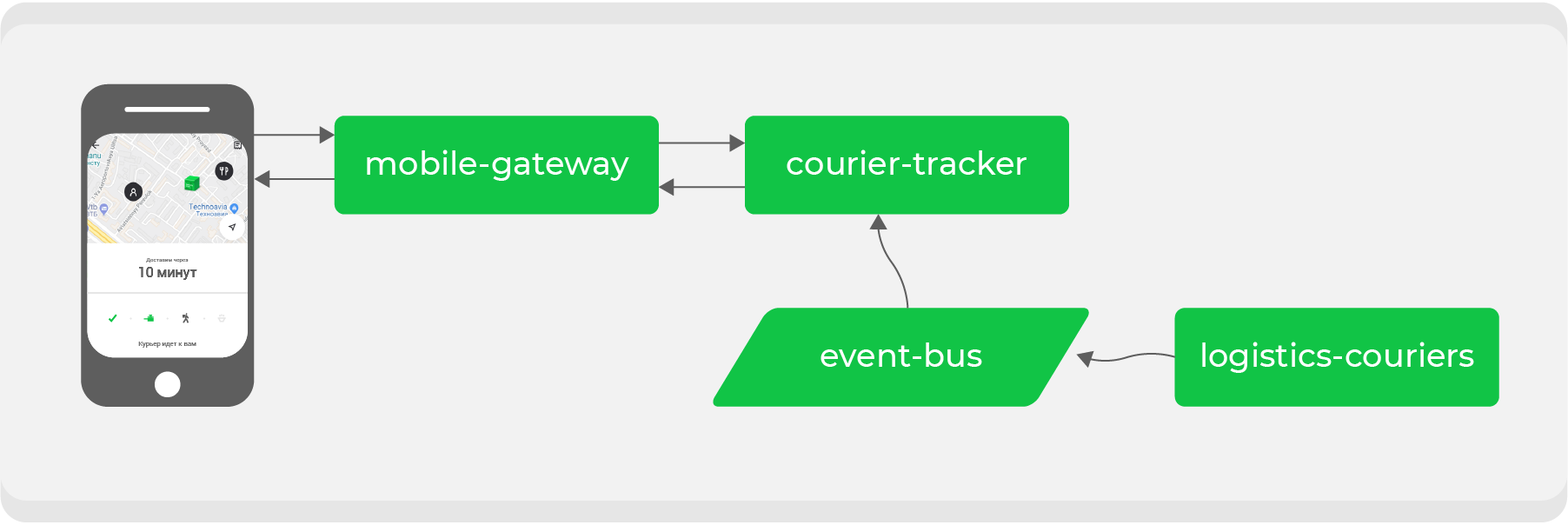
Кроме решения конкретной задачи, в итоге мы получаем топик данных с актуальными координатами курьеров, который любой наш сервис может использовать в своих целях.
Eventually consistency
В этом примере всё работает круто, за исключением того, что координаты курьеров будут не всегда актуальными по сравнению с синхронным вариантом: в архитектуре, построенной на асинхронном взаимодействии, встаёт вопрос об актуальности данных в каждый момент времени. Но у нас не так много критичных данных, которые нужны держать всегда свежими, поэтому нам эта схема идеально подходит: мы жертвуем актуальностью какой-то информации ради увеличения уровня доступности системы. Но мы гарантируем, что в конечном счёте во всех частях системы все данные будут актуальны и консистентны (eventually consistency).
Такая денормализация данных необходима, когда речь идёт о высоконагруженной системе и микросервисной архитектуре: каждый сервис сам обеспечивает сохранение тех данных, которые нужны ему для работы. Например, одна из главных сущностей нашего домена — это курьер. Ею оперирует множество сервисов, но всем им нужен разный набор данных: кому-то нужны личные данные, а кому-то только информация о типе передвижения. Мастер данных этого домена продюсит всю сущность в стрим, а сервисы аккумулируют нужные части:
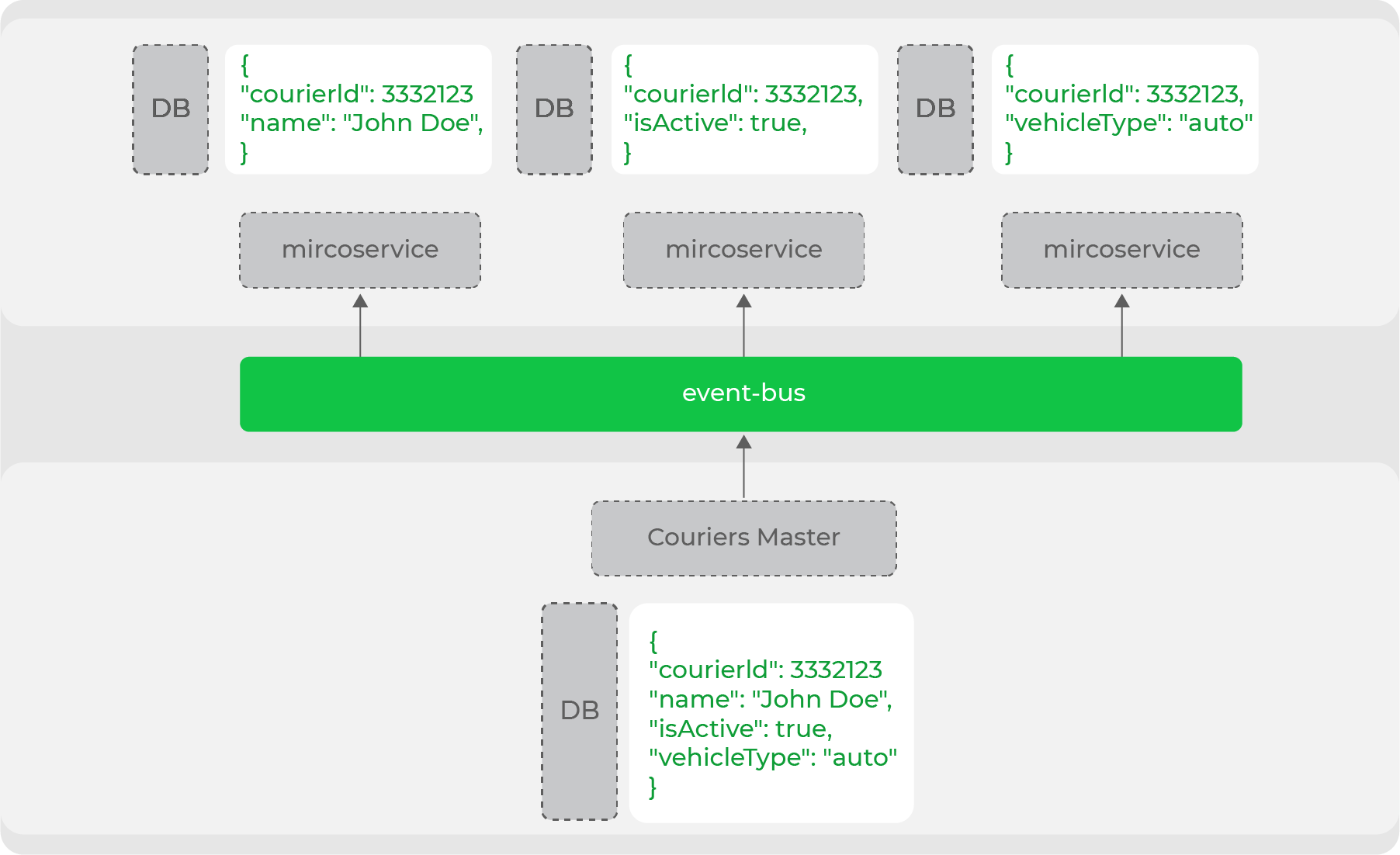
Таким образом, мы четко разделяем наши сервисы на те, что являются мастерами данных и те, кто использует эти данные. По сути, это headless commerce из evolutionary archicture — у нас четко отделены все «витрины» (сайт, мобильные приложения) от производителей этих данных.
Денормализация
Ещё пример: у нас есть механизм таргетированных уведомлений курьерам — это сообщения, которые придут им в приложение. На стороне бэкенда есть мощное API для отправки таких уведомлений. В нём можно настраивать фильтры рассылки: от конкретного курьера до групп курьеров по определённым признакам.
За эти уведомления отвечает сервис
logistics-courier-notifications. После того, как он получил запрос на отправку, его задача — сгенерировать сообщения для тех курьеров, которые попали в таргетинг. Для этого ему необходимо знать нужную информацию по всем курьерам Delivery Club. И у нас есть два варианта для решения этой задачи:- сделать эндпоинт на стороне сервиса — мастера данных по курьерам (
logistics-couriers), который по переданным полям сможет отфильтровать и вернуть нужных курьеров; - хранить всю нужную информацию прямо в сервисе, потребляя её из соответствующего топика и сохраняя те данные, по которым нам в дальнейшем нужно будет фильтровать.
Часть логики генерации сообщений и фильтрования курьеров не является нагруженной, она выполняется в фоне, поэтому вопроса о нагрузках на сервис
logistics-couriers не стоит. Но если выбрать первый вариант, мы столкнёмся с набором проблем:- придётся поддерживать узкоспециализированный эндпоинт в стороннем сервисе, который, скорее всего, понадобится только нам;
- если выбрать слишком широкий фильтр, то в выборку попадут вообще все курьеры, которые просто не поместятся в HTTP-ответ, и придётся реализовывать пагинацию (и итерировать по ней при опросе сервиса).
Очевидно, что мы остановились на хранении данных в самом сервисе. Он автономно и изолированно выполняет всю работу, никуда не обращаясь, а только аккумулируя все нужные данные у себя из топика Kafka. Есть риск, что мы получим сообщение о создании нового курьера позднее, и он не попадёт в какую-то выборку. Но этот недостаток асинхронной архитектуры неизбежен.
В итоге у нас сформулированы несколько важных принципов к проектированию сервисов:
- У сервиса должна быть конкретная ответственность. Если для его полноценного функционирования нужен ещё сервис, то это ошибка проектирования, их нужно либо объединять, либо пересматривать архитектуру.
- Критично смотрим на любые синхронные обращения. Для сервисов в одном направлении это допустимо, но для общения между сервисами разных направлений — нет
- Share nothing. Мы не ходим в БД сервисов в обход них самих. Все запросы только через API.
- Specification First. Сначала описываем и утверждаем протоколы.
Таким образом, итеративно трансформируя нашу систему согласно принятым принципам и подходам, мы пришли к такой архитектуре:
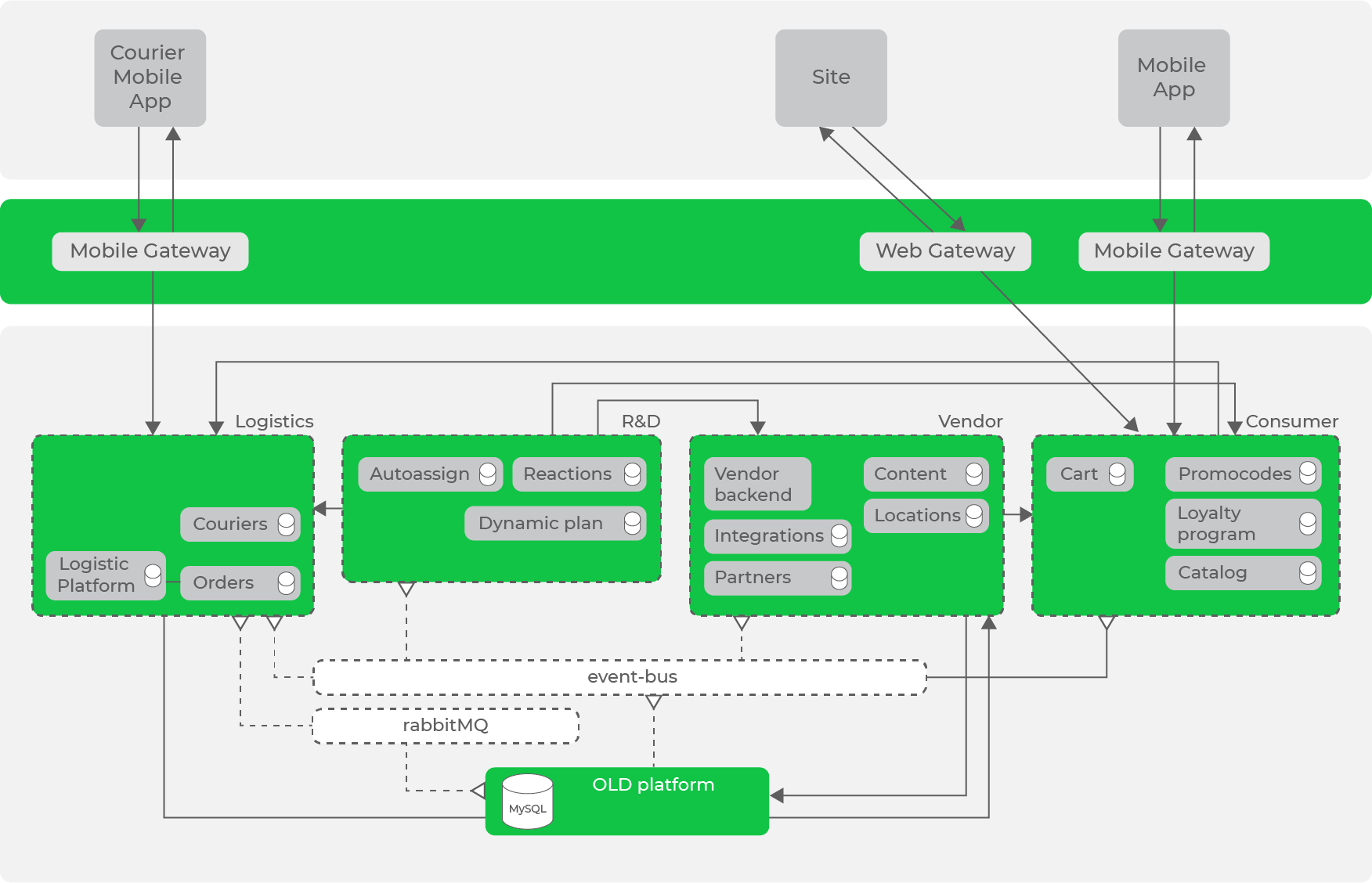
У нас уже есть шина данных в виде Kafka, которая уже имеет существенное количество потоков данных, но всё ещё остаются синхронные запросы между направлениями.
Как мы планируем развивать нашу архитектуру
Delivery club, как я говорил вначале, быстро растёт, мы релизим в прод огромное количество новых фич. А ещё больше экспериментируем (подробно об этом рассказал Николай Архипов) и тестируем гипотезы. Это всё порождает огромное количество источников данных и ещё больше вариантов их использования. А правильное управление потоками данных, которые очень важно грамотно выстроить — это и есть наша задача.
Дальше мы будем продолжать внедрять выработанные подходы во все сервисы Delivery Club: строить экосистемы сервисов вокруг платформы с транспортом в виде шины данных.
Первоочередная задача — добиться того, чтобы информация по всем доменам системы поставлялась в шину данных. Для новых сервисов с новыми данными это не проблема: на этапе подготовки сервиса он будет обязан стримить данные своего домена в Kafka.
Но кроме новых у нас есть большие legacy-сервисы с данными по основным нашим доменам: заказам и курьерам. Реализовать стриминг этих данных «как есть» проблематично, так как они хранятся размазанными по десяткам таблиц, и каждый раз строить конечную сущность для продюсинга всех изменений будет очень накладно.
Поэтому для старых сервисов мы решили использовать Debezium, который позволяет стримить информацию напрямую из таблиц на основе bin-log: в итоге получается готовый топик с сырыми данными из таблицы. Но они непригодны для использования в исходном виде, поэтому через трансформеры на уровне Kafka они будут преобразованы в понятный для потребителей формат и запушены в новый топик. Таким образом, у нас будет набор приватных топиков с сырыми данными из таблиц, который будет трансформироваться в удобный формат и транслироваться в публичный топик для использования потребителями.
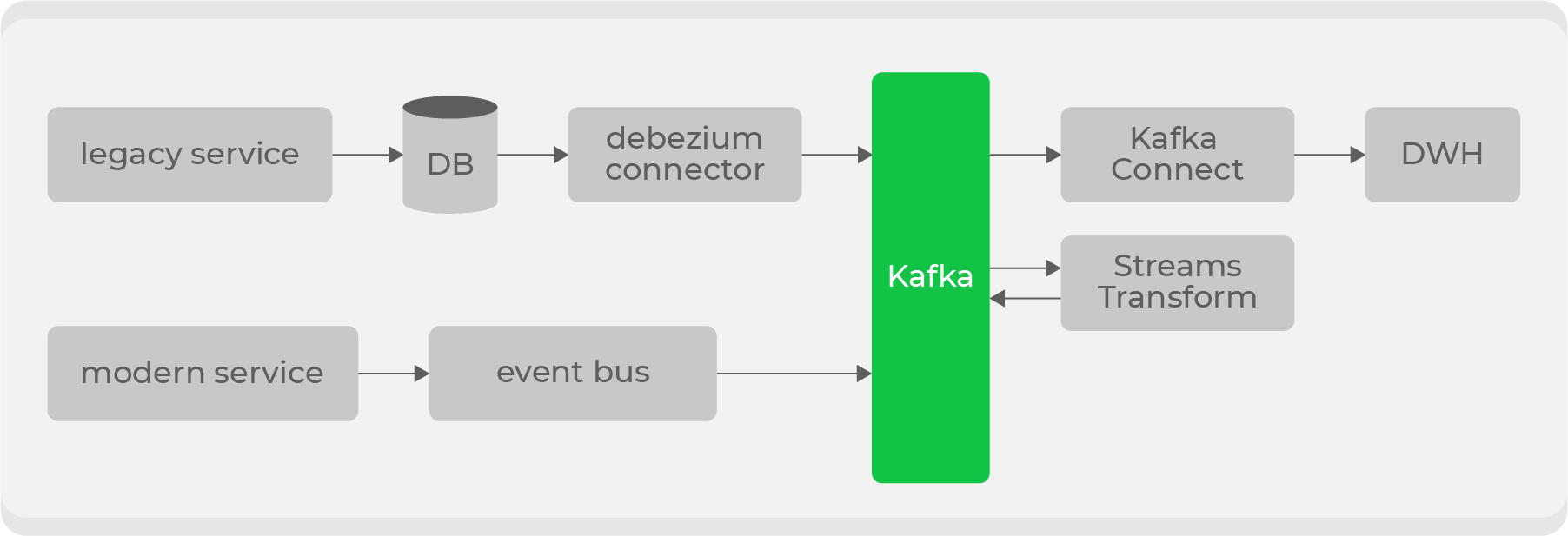
Получится несколько точек входа на запись в Kafka и разные типы топиков, поэтому дальше мы реализуем на стороне хранилища права доступа по ролям и добавим валидацию схем на стороне шины данных через Confluent.
Дальше из шины данных сервисы будут потреблять данные из нужных топиков. И мы сами будем использовать эти данные для своих систем: например, стримить через Kafka Connect в ElasticSearch или в DWH. С последним процесс будет сложнее: чтобы информация в нём была доступна для всех, её необходимо очистить от любых персональных данных.
Также нужно окончательно решить вопрос с монолитом: там ещё остаются критичные процессы, которые мы в ближайшее время будем выносить. Совсем недавно мы уже выкатили отдельный сервис, который занимается первой стадией создания заказа: формированием корзины, чека и оплаты. Дальше он отправляет эти данные в монолит для дальнейшей обработки. Ну а все остальные операции уже не требуют синхронности.
Как заниматься таким рефакторингом прозрачно для клиентов
Расскажу на ещё одном примере: каталоге ресторанов. Очевидно, что это очень нагруженное место, и мы решили выносить его в отдельный сервис на Go. Для ускорения разработки мы поделили вынос на два этапа:
- Сначала внутри сервиса ходим напрямую в реплику базы нашего монолита и получаем оттуда данные.
- Затем начинаем стримить нужные нам данные через Debezium и аккумулировать в базе самого сервиса.
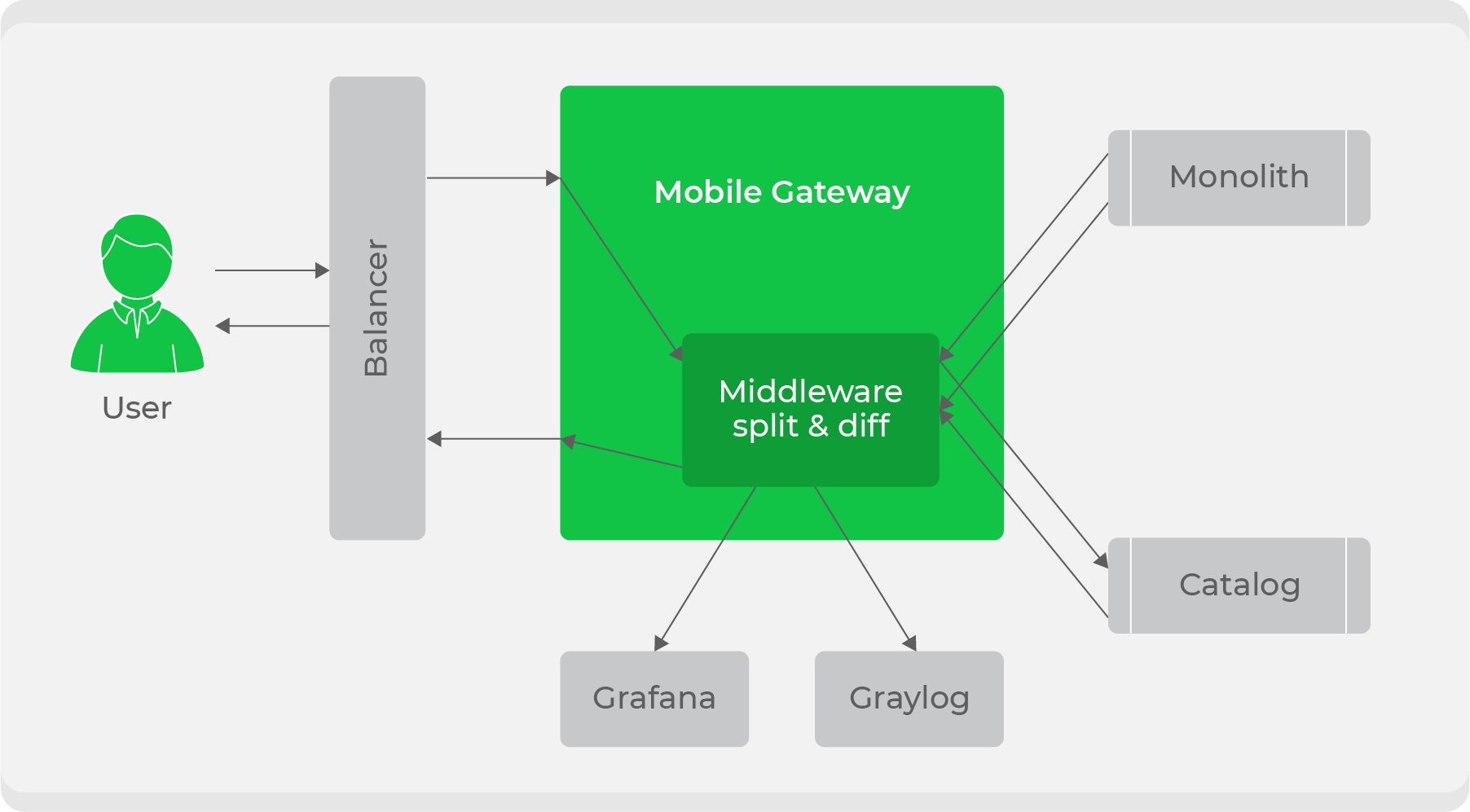
Когда сервис готов, встаёт вопрос о том, как его прозрачно встроить в текущий рабочий процесс. Мы использовали схему со сплитом трафика: с клиентов весь трафик шёл в сервис
mobile-gateway, а дальше делились между монолитом и новым сервисом. Изначально мы продолжали весь трафик обрабатывать через монолит, но часть дублировали в новый сервис, сравнивали их ответы и записывали логи о расхождениях в наши метрики. Этим мы обеспечили прозрачность тестирования сервиса в боевых условиях. После этого оставалось только постепенно переключать и наращивать на нём трафик, пока новый сервис полностью не вытеснит монолит.В общем, масштабных планов и идей у нас много. Мы находимся только в начале выработки нашей дальнейшей стратегии, пока непонятен её конечный вид и неизвестно, будет ли это всё работать так, как мы ожидаем. Как только внедрим и сделаем выводы, обязательно поделимся результатами.
Вместе со всеми этими концептуальными изменениями у нас продолжается активная разработка и поставка фич в прод, на которую уходит основное время. Тут мы подходим ко второй проблеме, про которую я говорил вначале: с учетом численности разработчиков (180 человек) остро встает вопрос валидации архитектуры и качества новых сервисов. Новое не должно деградировать систему, оно должно изначально встраиваться правильно. Но как при промышленных масштабах это контролировать?
Архитектурный комитет
Необходимость в нём возникла не сразу. Когда команда разработки была небольшая, любые изменения в системе было легко контролировать. Но чем больше людей, тем сложнее это делать.
Это порождает как реальные проблемы (сервис не выдерживал нагрузки из-за неправильного проектирования), так и концептуальные («а давайте здесь ходить синхронно, нагрузка же маленькая»).
Понятно, что большинство вопросов решается на уровне команды. Но если речь идёт о какой-то сложной интеграции в текущую систему, то тогда у команды может просто не хватить экспертизы. Поэтому хотелось создать какое-то объединение людей со всех направлений, к которому можно было бы прийти с любым вопросом про архитектуру и получить исчерпывающий ответ.
Так мы пришли к созданию архитектурного комитета, куда входят тимлиды, руководители направлений и CTO. Мы собираемся раз в две недели и обсуждаем планирующиеся крупные изменения в системе или просто решаем конкретные вопросы.
В итоге, проблему с контролем крупных изменений мы закрыли, остаётся вопрос общего подхода к качеству кода в Delivery Club: конкретные проблемы кода или фреймворка в разных командах могут решаться по-разному. Мы пришли к гильдиям по модели Spotify: это объединения неравнодушных к какой-то технологии людей. Например, есть гильдии Go, PHP и Frontend.
Они вырабатывают единые стили программирования, подходы к проектированию и архитектуре, помогают формировать и поддерживать инженерную культуру на высшем уровне. Также у них есть свой собственный бэклог, в рамках которого они улучшают внутренние инструменты, например, наш Go-шаблон для микросервисов.
Код на прод
Кроме того, что крупные изменения проходят через архитектурный комитет, а за культурой кода в целом следят гильдии, у нас ещё есть важный этап подготовки сервиса к продакшену: составление чек-листа в Confluence. Во-первых, составляя чек-лист, разработчик ещё раз оценивает свое решение; во-вторых, это требование эксплуатации, так как им нужно понимать, что за новый сервис появляется в продакшене.
В чек-листе обычно указывается:
- ответственный за сервис (это обычно тех-лид сервиса);
- ссылки на дашборд с настроенными алертами;
- описание сервиса и ссылка на Swagger;
- описание сервисов, с которым будет взаимодействовать;
- предполагаемая нагрузка на сервис;
- ссылка на health-check. Это URL, по которому служба эксплуатации настраивает свои мониторинги. Health-check раз в какой-то период дёргается: если вдруг он не ответил с кодом 200, значит, с сервисом что-то не так и к нам прилетает алерт. В свою очередь, health check может дёргать такие же URL’ы критичных для него сервисов, а также обязательно включать проверку всех компонентов сервиса, например, PostgreSQL или Redis.
Алерты сервиса проектируются ещё на этапе архитектурного согласования. Важно, чтобы разработчик понимал, что сервис живой, и учитывал не только технические метрики, но и продуктовые. Здесь имеются в виду не какие-то бизнесовые конверсии, а метрики, которые показывают, что сервис работает как надо.
Для примера можно взять уже рассмотренный выше сервис
courier-tracker, отслеживающий курьеров на карте. Одна из основных метрик в нём — это количество курьеров, у которых обновляются координаты. Если вдруг какие-то маршруты долго не обновляются, приходит алерт «что-то пошло не так». Может быть, где-то за данными не сходили, или неправильно зашли в базу, или отвалился какой-нибудь другой сервис. Это не техническая метрика и не продуктовая, но она показывает жизнеспособность сервиса. Для метрик мы используем Graylog и Prometheus, строим дашборды и настраиваем алерты в Grafana.
Несмотря на объём подготовки, доставка сервисов в прод достаточно быстрая: все сервисы изначально упакованы в Docker, в stage выкатываются автоматически после формирования типизированного чарта для Kubernetes, а дальше всё решается кнопкой в Jenkins.
Выкатка нового сервиса в прод заключается в назначении задачи на админов в Jira, в которой предоставляется вся информация, которую мы подготовили ранее.
Под капотом
Сейчас у нас 162 микросервиса, написанные на PHP и Go. Они распределились между сервисами примерно 50% на 50%. Изначально мы переписали на Go некоторые высоконагруженные сервисы. Дальше стало ясно, что Go проще в поддержке и мониторинге в продакшене, у него низкий порог входа, поэтому в последнее время мы пишем сервисы только на нём. Цели переписать на Go оставшиеся PHP-сервисы нет: он вполне успешно справляется со своими функциями.
В PHP-сервисах у нас Symfony, поверх которого мы используем свой небольшой фреймворк. Он навязывает сервисам общую архитектуру, благодаря которой мы снижаем порог входа в исходный код сервисов: какой бы сервис вы ни открыли, всегда будет понятно, что и где в нём лежит. А также фреймворк инкапсулирует слой транспорта общения между сервисами, для разработчика запрос в сторонний сервис выглядит на высоком уровне абстракции:
Здесь мы формируем DTO запроса ($courierResponse = $this->courierProtocol->get($courierRequest);
$courierRequest), вызываем метод объекта протокола конкретного сервиса, который является обёрткой над конкретным эндпоинтом. Под капотом наш объект $courierRequest преобразуется в объект запроса, который заполняется полями из DTO. Это всё гибко настраивается: поля могут подставляться как в заголовки, так и в сам URL запроса. Далее запрос посылается через cURL, получаем объект Response и обратно его трансформируем в ожидаемый нами объект $courierResponse.Благодаря этому разработчики сосредоточены на бизнес-логике, без подробностей взаимодействия на низком уровне. Объекты протоколов, запросов и ответов сервисов лежат в отдельном репозитории — SDK этого сервиса. Благодаря этому, любой сервис, который захочет использовать его протоколы, получит весь типизированный пакет протоколов после импорта SDK.
Но у этого процесса большой недостаток: репозитории с SDK сложно поддерживать, потому что все DTO пишутся вручную, а удобную кодогенерацию сделать непросто: попытки были, но в конце-концов, с учётом перехода на Go, в это не стали вкладывать время.
В итоге, изменения в протоколе сервиса могут превратиться в несколько пулл-реквестов: в сам сервис, в его SDK, и в сервис, которому нужен этот протокол. В последнем нам нужно поднять версию импортированного SDK, чтобы туда попали изменения. Это часто вызывает вопросы у новых разработчиков: «Я ведь только изменил параметр, почему мне нужно делать три реквеста в три разных репозитория?!»
В Go всё сильно проще: у нас есть отличный генератор кода (Сергей Попов написал об этом подробную статью), благодаря которому весь протокол типизирован, и сейчас даже обсуждается вариант с хранением всех спецификаций в отдельном репозитории. Таким образом, если кто-то меняет спеку, все зависящие от неё сервисы сразу начнут использовать обновлённый вариант.
Технический радар
Кроме уже упомянутых Go и PHP мы используем огромное количество других технологий. Они варьируются от направления к направлению и зависят от конкретных задач. В основном, на бэкенде у нас используются:
Python, на котором пишет команда Data Science.KotlinиSwift— для разработки мобильных приложений.PostgreSQLв качестве базы данных, но на некоторых старых сервисах всё ещё крутится MySQL. В микросервисах используем несколько подходов: для каждого сервиса своя БД и share nothing — мы не ходим в базы данных в обход сервисов, только через их API.ClickHouse— для узкоспециализированных сервисов, связанных с аналитикой.RedisиMemcachedв качестве in-memory хранилищ.
При выборе технологии мы руководствуемся специальными принципами. Одним из основных требований является Ease of use: используем максимально простую и понятную технологию для разработчика, по возможности придерживаясь принятого стека. Для тех, кто хочет узнать весь стек конкретных технологий, у нас составлен очень подробный техрадар.
Long story short
В итоге от монолитной архитектуры мы перешли к микросервисной, и сейчас уже имеем группы сервисов, объединенных по направлениям (доменным областям) вокруг платформы, которая является ядром и мастером данных.
У нас есть видение, как реорганизовать наши потоки данных и как это делать без влияния на скорость разработки новых фич. В будущем мы обязательно расскажем о том, куда нас это привело.
А благодаря активной передаче знаний и формализованному процессу внесения изменений у нас получается поставлять большое количество фич, которые не тормозят процесс трансформации нашей архитектуры.
На этом у меня всё, спасибо, что дочитали!



