
Добрый день. Я занимаюсь переводом уроков к Vulkan API с английского языка на русский (ссылка на оригинальный тьюториал — vulkan-tutorial.com).
Сегодня я бы хотела поделиться с вами переводом заключительной главы в разделе Drawing — «Rendering and presentation».
В этой главе мы сможем собрать все части воедино. Напишем функцию
Функция
Каждое из этих действий выполняется с помощью одного вызова функции, однако все они выполняются асинхронно. Выполнение функции завершается еще до выполнения операций, и порядок выполнения не определен. Это является проблемой, поскольку каждая операция зависит от результата предыдущей операции.
Есть два способа синхронизировать операции в swap chain: с помощью барьеров (fences) и семафоров (semaphores). Эти объекты используются для координации операций: пока одна операция выполняется, следующая ожидает, когда синхронизатор перейдет из состояния unsignaled в signaled.
Разница между барьером и семафором в том, что состояния барьеров можно получить из вашей программы, например, с помощью
Мы будем использовать два семафора. Первый семафор сообщит нам о том, что image получен и готов к рендерингу, а второй сообщит об окончании рендеринга и о том, что image можно выводить на экран. Создадим два члена класса
Чтобы создать семафоры, добавим функцию
Для создания семафоров требуется заполнить структуру
Создадим семафоры уже знакомым нам способом — с помощью вызова функции
Семафоры нужно очистить в конце работы программы после выполнения всех команд, когда синхронизация больше не требуется:
Как уже говорилось, первое, что мы должны сделать в функции
Первые два параметра, передаваемые в
Следующие два параметра — это синхронизаторы, которые переходят в состояние signaled, когда presentation engine закончит работу с image, после чего мы можем начать отрисовку в него. Здесь можно указать семафор, барьер или и то, и другое. Мы используем
Последний параметр указывает переменную для получения индекса уже доступного image из swap chain. Индекс ссылается на
Отправка в очередь и синхронизация настраиваются в структуре
Первые три параметра указывают, какие семафоры необходимо дождаться перед началом выполнения и на каком этапе (или этапах) графического конвейера происходит ожидание. Прежде чем начать запись цвета в image, нам нужно дождаться, когда image станет доступен, поэтому укажем этап графического конвейера, который выполняет запись в цветовой буфер. Это значит, что теоретически выполнение нашего вершинного шейдера может начаться тогда, когда image еще не доступен. Каждый элемент в массиве
Следующие два параметра указывают, какие буферы команд отправляются для выполнения. Мы должны отправить буфер команд, прикрепленный к image, который мы получили из swap chain.
Параметры
Теперь можно отправить буфер команд в графическую очередь с помощью
Помните, что image layout автоматически передается между подпроходами в проходе рендера. Зависимости памяти и порядка выполнения между подпроходами контролируются зависимостями подпроходов. Хоть мы используем только один подпроход, операции непосредственно до него и сразу после него также считаются неявными «подпроходами».
Есть две встроенные зависимости, которые отвечают за передачу данных в начале и в конце прохода рендера, но первая передача не происходит в нужное время. Предполагается, что передача данных должна происходить в начале конвейера, но на этом этапе image еще не получен! Есть два пути решения этой проблемы. Можно изменить
Зависимости подпроходов указываются через
Первые два параметра определяют индексы зависимых подпроходов. Значение
В следующих двух полях указаны операции, которые нужно ожидать, и этапы, на которых эти операции выполняются. Нам нужно дождаться, когда swap chain закончит считывание image, прежде чем мы сможем получить к нему доступ. Этого можно добиться, дождавшись output stage у записи в цветовой буфер.
Эти настройки предотвратят передачу данных до тех пор, пока это не станет действительно необходимо (и будет разрешено): когда мы захотим записать цвет в буфер.
В структуре
Последнее действие, которое осталось выполнить для отрисовки кадра — отправить результат обратно в swap chain, чтобы вывести на экран. Отображение на экране настраивается в структуре
Первые два параметра указывают, какие семафоры нужно дождаться перед началом отображения.
Следующие два параметра указывают swap chains для представления images и индекс image для каждого swap chain. Почти всегда будет использоваться только один swap chain.
Последний опциональный параметр —
Функция
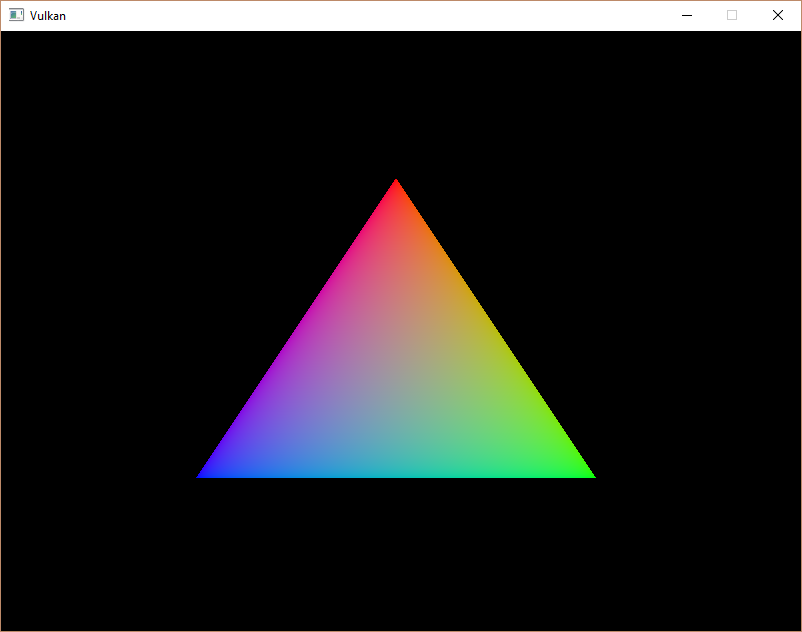
Если вы все сделали правильно, при запуске программы должно отобразиться что-то подобное:
Этот треугольник может слегка отличаться от тех, что вы привыкли видеть в учебниках по графике. Дело в том, что в нашем руководстве шейдер интерполирует в линейном цветовом пространстве, а впоследствии преобразует в цветовое пространство sRGB. Чтобы узнать, в чем между ними отличие, перейдите по ссылке.
Ура! Получилось! К сожалению, при включенных слоях валидации программа будет падать при каждом закрытии. Сообщения, выводимые в терминал из

Все операции в
Для решения этой проблемы перед выходом из
Используйте
Если запустить программу с включенными слоями валидации, можно либо получить ошибки, либо заметить, что использование памяти постепенно растет. Дело в том, что программа сразу отправляет работу в функцию
Самый простой способ решить эту проблему — дождаться завершения работы сразу после отправки, например, с помощью
Однако в этом случае графический конвейер используется неоптимально, т.к. за раз только один кадр может пройти через конвейер. Этапы, через которые прошел кадр, освобождаются и уже могут использоваться для следующего кадра. Расширим нашу программу, чтобы каждый освободившийся этап начинал обрабатывать следующий кадр.
Сначала добавим константу, указывающую, сколько кадров должно обрабатываться одновременно:
Для каждого кадра должен быть свой набор семафоров:
Изменим функцию
Также все семафоры должны быть очищены:
Чтобы каждый раз использовать соответствующую пару семафоров, нужно отслеживать текущий кадр. Для этого используем индекс кадра:
Теперь изменим функцию
Не забывайте каждый раз переходить к следующему кадру:
Использование деления по модулю (%) гарантирует, что индекс кадра закольцовывается после каждого
Несмотря на то, что мы настроили необходимые объекты для облегчения обработки нескольких кадров одновременно, мы все еще не препятствуем отправке более
Для выполнения синхронизации CPU-GPU Vulkan предлагает использовать барьеры (fences). Барьеры похожи на семафоры тем, что они используются для ожидания и уведомляют об окончании операций, но на этот раз мы пропишем их ожидание в нашем коде. Сначала создадим барьер для каждого кадра:
Я решил создать барьеры вместе с семафорами, поэтому переименовал
Создание барьеров (
Теперь изменим функцию
Теперь осталось изменить начало функции
Функция
Если запустить программу сейчас, можно заметить, что что-то не так. Кажется, будто ничего не рендерится. Если у вас были включены слои валидации, появится следующее сообщение:

Это значит, что ожидаемый барьер не был отправлен. Проблема в том, что по умолчанию барьеры создаются в состоянии unsignaled. Поэтому, если барьер не использовался ранее,
Утечка памяти устранена, но программа работает не совсем корректно. Если число
Для этого добавим новый список
Подготовим его в
Изначально ни один кадр не использует image, поэтому мы явно инициализируем его как «без барьеров». Изменим функцию
Поскольку вызовов
Мы настроили всю необходимую синхронизацию, чтобы в очередь не отправлялось более двух кадров и чтобы эти кадры случайно не использовали один и тот же image. Обратите внимание, что, например для окончательной очистки, может использоваться более грубая синхронизация, такая как
Чтобы узнать о синхронизации больше, предлагаем ознакомиться с подробным обзором Khronos.
Написав чуть более 900 строк кода, мы наконец-то видим результат нашей работы на экране! Безусловно, настройка программы с Vulkan занимает немало времени, но благодаря тому, что состояния в Vulkan должны описываться явно, вы можете контролировать многие процессы. Я рекомендую вам потратить чуть больше времени и еще раз перечитать код, чтобы понять назначение всех объектов Vulkan и то, как они соотносятся друг с другом.
В следующей главе мы рассмотрим еще одну деталь, необходимую для правильной работы программы с Vulkan.
Сегодня я бы хотела поделиться с вами переводом заключительной главы в разделе Drawing — «Rendering and presentation».
Содержание
1. Вступление
2. Краткий обзор
3. Настройка окружения
4. Рисуем треугольник
5. Буферы вершин
6. Uniform-буферы
7. Текстурирование
8. Буфер глубины
9. Загрузка моделей
10. Создание мип-карт
11. Multisampling
FAQ
Политика конфиденциальности
2. Краткий обзор
3. Настройка окружения
4. Рисуем треугольник
- Подготовка к работе
- Базовый код
- Экземпляр (instance)
- Слои валидации
- Физические устройства и семейства очередей
- Логическое устройство и очереди
- Отображение на экране
- Window surface
- Swap chain
- Image views
- Графический конвейер (pipeline)
- Вступление
- Шейдерные модули
- Непрограммируемые этапы
- Проходы рендера
- Заключение
- Отрисовка
- Фреймбуферы
- Буферы команд
- Рендеринг и отображение на экране
- Повторное создание цепочки показа
5. Буферы вершин
- Описание
- Создание буфера вершин
- Staging буфер
- Буфер индексов
6. Uniform-буферы
- Дескриптор layout и буфера
- Дескриптор пула и sets
7. Текстурирование
- Изображения
- Image view и image sampler
- Комбинированный image sampler
8. Буфер глубины
9. Загрузка моделей
10. Создание мип-карт
11. Multisampling
FAQ
Политика конфиденциальности
Рендеринг и отображение на экране
- Подготовка
- Синхронизация
- Семафоры
- Получение image из swap chain
- Отправка буфера команд
- Зависимости подпроходов
- Отображение на экране
- Кадры в конвейере (Frames in flight)
- Выводы
Подготовка
В этой главе мы сможем собрать все части воедино. Напишем функцию
drawFrame и вызовем ее из mainLoop, чтобы вывести наш треугольник на экран:void mainLoop() {
while (!glfwWindowShouldClose(window)) {
glfwPollEvents();
drawFrame();
}
}
...
void drawFrame() {
}Синхронизация
Функция
drawFrame выполняет следующие операции:- Получение image из swap chain
- Запуск соответствующего буфера команд для этого image
- Возвращение image в swap chain для вывода на экран
Каждое из этих действий выполняется с помощью одного вызова функции, однако все они выполняются асинхронно. Выполнение функции завершается еще до выполнения операций, и порядок выполнения не определен. Это является проблемой, поскольку каждая операция зависит от результата предыдущей операции.
Есть два способа синхронизировать операции в swap chain: с помощью барьеров (fences) и семафоров (semaphores). Эти объекты используются для координации операций: пока одна операция выполняется, следующая ожидает, когда синхронизатор перейдет из состояния unsignaled в signaled.
Разница между барьером и семафором в том, что состояния барьеров можно получить из вашей программы, например, с помощью
vkWaitForFences, а для семафоров — нельзя. Барьеры в основном предназначены для синхронизации самой программы с операциями рендеринга, а семафоры используются для синхронизации операций внутри видеокарты. Нам нужно синхронизировать операции с очередями графических команд и очередями отображения, для этой цели больше подойдут семафоры.Семафоры
Мы будем использовать два семафора. Первый семафор сообщит нам о том, что image получен и готов к рендерингу, а второй сообщит об окончании рендеринга и о том, что image можно выводить на экран. Создадим два члена класса
VkSemaphore:VkSemaphore imageAvailableSemaphore;
VkSemaphore renderFinishedSemaphore;Чтобы создать семафоры, добавим функцию
createSemaphores:void initVulkan() {
createInstance();
setupDebugMessenger();
createSurface();
pickPhysicalDevice();
createLogicalDevice();
createSwapChain();
createImageViews();
createRenderPass();
createGraphicsPipeline();
createFramebuffers();
createCommandPool();
createCommandBuffers();
createSemaphores();
}
...
void createSemaphores() {
}Для создания семафоров требуется заполнить структуру
VkSemaphoreCreateInfo. В текущей версии API она содержит всего одно обязательное поле — sType:void createSemaphores() {
VkSemaphoreCreateInfo semaphoreInfo{};
semaphoreInfo.sType = VK_STRUCTURE_TYPE_SEMAPHORE_CREATE_INFO;
}Создадим семафоры уже знакомым нам способом — с помощью вызова функции
vkCreateSemaphore:if (vkCreateSemaphore(device, &semaphoreInfo, nullptr, &imageAvailableSemaphore) != VK_SUCCESS ||
vkCreateSemaphore(device, &semaphoreInfo, nullptr, &renderFinishedSemaphore) != VK_SUCCESS) {
throw std::runtime_error("failed to create semaphores!");
}Семафоры нужно очистить в конце работы программы после выполнения всех команд, когда синхронизация больше не требуется:
void cleanup() {
vkDestroySemaphore(device, renderFinishedSemaphore, nullptr);
vkDestroySemaphore(device, imageAvailableSemaphore, nullptr);Получение image из swap chain
Как уже говорилось, первое, что мы должны сделать в функции
drawFrame — это получить image из swap chain. Напомним, что swap chain — это часть расширения Vulkan, поэтому в названии функции должно быть vk * KHR:void drawFrame() {
uint32_t imageIndex;
vkAcquireNextImageKHR(device, swapChain, UINT64_MAX, imageAvailableSemaphore, VK_NULL_HANDLE, &imageIndex);
}Первые два параметра, передаваемые в
vkAcquireNextImageKHR, — это логическое устройство и swap chain, из которой нужно получить image. Третий параметр указывает время ожидания в наносекундах, по истечении которого image станет доступным. Использование максимального значения в виде 64-битного целого числа без знака отключает время ожидания.Следующие два параметра — это синхронизаторы, которые переходят в состояние signaled, когда presentation engine закончит работу с image, после чего мы можем начать отрисовку в него. Здесь можно указать семафор, барьер или и то, и другое. Мы используем
imageAvailableSemaphore.Последний параметр указывает переменную для получения индекса уже доступного image из swap chain. Индекс ссылается на
VkImage в массиве swapChainImages. Мы будем использовать его для выбора соответствующего буфера команд.Отправка буфера команд
Отправка в очередь и синхронизация настраиваются в структуре
VkSubmitInfo.VkSubmitInfo submitInfo{};
submitInfo.sType = VK_STRUCTURE_TYPE_SUBMIT_INFO;
VkSemaphore waitSemaphores[] = {imageAvailableSemaphore};
VkPipelineStageFlags waitStages[] = {VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT};
submitInfo.waitSemaphoreCount = 1;
submitInfo.pWaitSemaphores = waitSemaphores;
submitInfo.pWaitDstStageMask = waitStages;Первые три параметра указывают, какие семафоры необходимо дождаться перед началом выполнения и на каком этапе (или этапах) графического конвейера происходит ожидание. Прежде чем начать запись цвета в image, нам нужно дождаться, когда image станет доступен, поэтому укажем этап графического конвейера, который выполняет запись в цветовой буфер. Это значит, что теоретически выполнение нашего вершинного шейдера может начаться тогда, когда image еще не доступен. Каждый элемент в массиве
waitStages соответствует семафору с тем же индексом в pWaitSemaphores.submitInfo.commandBufferCount = 1;
submitInfo.pCommandBuffers = &commandBuffers[imageIndex];Следующие два параметра указывают, какие буферы команд отправляются для выполнения. Мы должны отправить буфер команд, прикрепленный к image, который мы получили из swap chain.
VkSemaphore signalSemaphores[] = {renderFinishedSemaphore};
submitInfo.signalSemaphoreCount = 1;
submitInfo.pSignalSemaphores = signalSemaphores;Параметры
signalSemaphoreCount и pSignalSemaphores указывают, какие семафоры сообщат об окончании выполнения буферов команд. Мы используем renderFinishedSemaphore.if (vkQueueSubmit(graphicsQueue, 1, &submitInfo, VK_NULL_HANDLE) != VK_SUCCESS) {
throw std::runtime_error("failed to submit draw command buffer!");
}Теперь можно отправить буфер команд в графическую очередь с помощью
vkQueueSubmit. Функция принимает массив структур VkSubmitInfo в качестве аргумента для большей эффективности при слишком большой нагрузке. Последний параметр указывает на опциональный барьер, который переходит в состояние signaled при завершении выполнения буферов команд. Для синхронизации мы используем семафоры, поэтому просто передадим VK_NULL_HANDLE.Зависимости подпроходов
Помните, что image layout автоматически передается между подпроходами в проходе рендера. Зависимости памяти и порядка выполнения между подпроходами контролируются зависимостями подпроходов. Хоть мы используем только один подпроход, операции непосредственно до него и сразу после него также считаются неявными «подпроходами».
Есть две встроенные зависимости, которые отвечают за передачу данных в начале и в конце прохода рендера, но первая передача не происходит в нужное время. Предполагается, что передача данных должна происходить в начале конвейера, но на этом этапе image еще не получен! Есть два пути решения этой проблемы. Можно изменить
waitStages для imageAvailableSemaphore и использовать VK_PIPELINE_STAGE_TOP_OF_PIPE_BIT, чтобы не допустить начало прохода рендера до тех пор, пока image не станет доступен. Другой способ — заставить проход рендера ждать VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT. Я решил выбрать второй способ, поскольку он позволит лучше рассмотреть зависимости подпроходов и то, как они работают.Зависимости подпроходов указываются через
VkSubpassDependency. Добавьте в функцию createRenderPass следующий код:VkSubpassDependency dependency{};
dependency.srcSubpass = VK_SUBPASS_EXTERNAL;
dependency.dstSubpass = 0;Первые два параметра определяют индексы зависимых подпроходов. Значение
VK_SUBPASS_EXTERNAL указывает на неявный подпроход перед или после прохода рендера в зависимости от того, где указано значение: в srcSubpass или dstSubpass. Индекс 0 указывает на наш единственный подпроход. Значение dstSubpass всегда должно быть больше, чем srcSubpass, чтобы не допустить циклов в графе зависимостей (за исключением случаев, когда один из подпроходов равен VK_SUBPASS_EXTERNAL).dependency.srcStageMask = VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT;
dependency.srcAccessMask = 0;В следующих двух полях указаны операции, которые нужно ожидать, и этапы, на которых эти операции выполняются. Нам нужно дождаться, когда swap chain закончит считывание image, прежде чем мы сможем получить к нему доступ. Этого можно добиться, дождавшись output stage у записи в цветовой буфер.
dependency.dstStageMask = VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT;
dependency.dstAccessMask = VK_ACCESS_COLOR_ATTACHMENT_WRITE_BIT;Эти настройки предотвратят передачу данных до тех пор, пока это не станет действительно необходимо (и будет разрешено): когда мы захотим записать цвет в буфер.
renderPassInfo.dependencyCount = 1;
renderPassInfo.pDependencies = &dependency;В структуре
VkRenderPassCreateInfo есть два поля для указания массива зависимостей.Отображение на экране
Последнее действие, которое осталось выполнить для отрисовки кадра — отправить результат обратно в swap chain, чтобы вывести на экран. Отображение на экране настраивается в структуре
VkPresentInfoKHR в конце функции drawFrame.VkPresentInfoKHR presentInfo{};
presentInfo.sType = VK_STRUCTURE_TYPE_PRESENT_INFO_KHR;
presentInfo.waitSemaphoreCount = 1;
presentInfo.pWaitSemaphores = signalSemaphores;Первые два параметра указывают, какие семафоры нужно дождаться перед началом отображения.
VkSwapchainKHR swapChains[] = {swapChain};
presentInfo.swapchainCount = 1;
presentInfo.pSwapchains = swapChains;
presentInfo.pImageIndices = &imageIndex;Следующие два параметра указывают swap chains для представления images и индекс image для каждого swap chain. Почти всегда будет использоваться только один swap chain.
presentInfo.pResults = nullptr; // OptionalПоследний опциональный параметр —
pResults. Он позволяет указать массив значений VkResult для проверки каждого swap chain при успешном отображении. В нем нет необходимости, если используется лишь один swap chain, поскольку в этом случае можно просто использовать возвращаемое значение функции.vkQueuePresentKHR(presentQueue, &presentInfo);Функция
vkQueuePresentKHR отправляет запрос на представление image в swap chain. Позже мы добавим обработку ошибок для vkAcquireNextImageKHR и vkQueuePresentKHR, поскольку их ошибки необязательно приводят к закрытию программы, в отличие от функций, встречавшихся ранее.Если вы все сделали правильно, при запуске программы должно отобразиться что-то подобное:
Этот треугольник может слегка отличаться от тех, что вы привыкли видеть в учебниках по графике. Дело в том, что в нашем руководстве шейдер интерполирует в линейном цветовом пространстве, а впоследствии преобразует в цветовое пространство sRGB. Чтобы узнать, в чем между ними отличие, перейдите по ссылке.
Ура! Получилось! К сожалению, при включенных слоях валидации программа будет падать при каждом закрытии. Сообщения, выводимые в терминал из
debugCallback, укажут причину:Все операции в
drawFrame выполняются асинхронно. Это значит, что при выходе из mainLoop операции рисования и отображения могут продолжаться. Освобождать ресурсы в такой момент — не самая лучшая идея. Для решения этой проблемы перед выходом из
mainLoop и уничтожением окна, нужно дождаться, когда логическое устройство завершит операции. void mainLoop() {
while (!glfwWindowShouldClose(window)) {
glfwPollEvents();
drawFrame();
}
vkDeviceWaitIdle(device);
}Используйте
vkQueueWaitIdle, чтобы дождаться завершения операций в определенной очереди команд. Эта функция используется как примитивный способ выполнить синхронизацию. Теперь при закрытии программы не должно возникнуть никаких проблем.Кадры в конвейере (Frames in flight)
Если запустить программу с включенными слоями валидации, можно либо получить ошибки, либо заметить, что использование памяти постепенно растет. Дело в том, что программа сразу отправляет работу в функцию
drawFrame и не проверяет, завершилась ли какая-нибудь ее часть. Если CPU отправляет работу быстрее, чем GPU успевает ее выполнять, очередь будет медленно заполняться работой. Но хуже то, что мы повторно используем семафоры imageAvailableSemaphore и renderFinishedSemaphore вместе с буферами команд одновременно для нескольких кадров!Самый простой способ решить эту проблему — дождаться завершения работы сразу после отправки, например, с помощью
vkQueueWaitIdle:void drawFrame() {
...
vkQueuePresentKHR(presentQueue, &presentInfo);
vkQueueWaitIdle(presentQueue);
}Однако в этом случае графический конвейер используется неоптимально, т.к. за раз только один кадр может пройти через конвейер. Этапы, через которые прошел кадр, освобождаются и уже могут использоваться для следующего кадра. Расширим нашу программу, чтобы каждый освободившийся этап начинал обрабатывать следующий кадр.
Сначала добавим константу, указывающую, сколько кадров должно обрабатываться одновременно:
const int MAX_FRAMES_IN_FLIGHT = 2;Для каждого кадра должен быть свой набор семафоров:
std::vector<VkSemaphore> imageAvailableSemaphores;
std::vector<VkSemaphore> renderFinishedSemaphores;Изменим функцию
createSemaphores, чтобы их создать:void createSemaphores() {
imageAvailableSemaphores.resize(MAX_FRAMES_IN_FLIGHT);
renderFinishedSemaphores.resize(MAX_FRAMES_IN_FLIGHT);
VkSemaphoreCreateInfo semaphoreInfo{};
semaphoreInfo.sType = VK_STRUCTURE_TYPE_SEMAPHORE_CREATE_INFO;
for (size_t i = 0; i < MAX_FRAMES_IN_FLIGHT; i++) {
if (vkCreateSemaphore(device, &semaphoreInfo, nullptr, &imageAvailableSemaphores[i]) != VK_SUCCESS ||
vkCreateSemaphore(device, &semaphoreInfo, nullptr, &renderFinishedSemaphores[i]) != VK_SUCCESS) {
throw std::runtime_error("failed to create semaphores for a frame!");
}
}Также все семафоры должны быть очищены:
void cleanup() {
for (size_t i = 0; i < MAX_FRAMES_IN_FLIGHT; i++) {
vkDestroySemaphore(device, renderFinishedSemaphores[i], nullptr);
vkDestroySemaphore(device, imageAvailableSemaphores[i], nullptr);
}
...
}Чтобы каждый раз использовать соответствующую пару семафоров, нужно отслеживать текущий кадр. Для этого используем индекс кадра:
size_t currentFrame = 0;Теперь изменим функцию
drawFrame, чтобы использовать соответствующие семафоры:void drawFrame() {
vkAcquireNextImageKHR(device, swapChain, UINT64_MAX, imageAvailableSemaphores[currentFrame], VK_NULL_HANDLE, &imageIndex);
...
VkSemaphore waitSemaphores[] = {imageAvailableSemaphores[currentFrame]};
...
VkSemaphore signalSemaphores[] = {renderFinishedSemaphores[currentFrame]};
...
}Не забывайте каждый раз переходить к следующему кадру:
void drawFrame() {
...
currentFrame = (currentFrame + 1) % MAX_FRAMES_IN_FLIGHT;
}Использование деления по модулю (%) гарантирует, что индекс кадра закольцовывается после каждого
MAX_FRAMES_IN_FLIGHT кадра в очереди.Несмотря на то, что мы настроили необходимые объекты для облегчения обработки нескольких кадров одновременно, мы все еще не препятствуем отправке более
MAX_FRAMES_IN_FLIGHT кадров. Сейчас используется только синхронизация GPU-GPU без синхронизации CPU-GPU. Мы можем использовать объекты кадра #0, в то время как сам кадр #0 все еще находится в конвейере (in flight)!Для выполнения синхронизации CPU-GPU Vulkan предлагает использовать барьеры (fences). Барьеры похожи на семафоры тем, что они используются для ожидания и уведомляют об окончании операций, но на этот раз мы пропишем их ожидание в нашем коде. Сначала создадим барьер для каждого кадра:
std::vector<VkSemaphore> imageAvailableSemaphores;
std::vector<VkSemaphore> renderFinishedSemaphores;
std::vector<VkFence> inFlightFences;
size_t currentFrame = 0;Я решил создать барьеры вместе с семафорами, поэтому переименовал
createSemaphores в createSyncObjects:void createSyncObjects() {
imageAvailableSemaphores.resize(MAX_FRAMES_IN_FLIGHT);
renderFinishedSemaphores.resize(MAX_FRAMES_IN_FLIGHT);
inFlightFences.resize(MAX_FRAMES_IN_FLIGHT);
VkSemaphoreCreateInfo semaphoreInfo{};
semaphoreInfo.sType = VK_STRUCTURE_TYPE_SEMAPHORE_CREATE_INFO;
VkFenceCreateInfo fenceInfo{};
fenceInfo.sType = VK_STRUCTURE_TYPE_FENCE_CREATE_INFO;
for (size_t i = 0; i < MAX_FRAMES_IN_FLIGHT; i++) {
if (vkCreateSemaphore(device, &semaphoreInfo, nullptr, &imageAvailableSemaphores[i]) != VK_SUCCESS ||
vkCreateSemaphore(device, &semaphoreInfo, nullptr, &renderFinishedSemaphores[i]) != VK_SUCCESS ||
vkCreateFence(device, &fenceInfo, nullptr, &inFlightFences[i]) != VK_SUCCESS) {
throw std::runtime_error("failed to create synchronization objects for a frame!");
}
}
}Создание барьеров (
VkFence) очень похоже на создание семафоров. Также не забудьте выполнить очистку:void cleanup() {
for (size_t i = 0; i < MAX_FRAMES_IN_FLIGHT; i++) {
vkDestroySemaphore(device, renderFinishedSemaphores[i], nullptr);
vkDestroySemaphore(device, imageAvailableSemaphores[i], nullptr);
vkDestroyFence(device, inFlightFences[i], nullptr);
}
...
}Теперь изменим функцию
drawFrame, чтобы использовать барьеры. Вызов vkQueueSubmit содержит опциональный параметр для передачи барьера, который переходит в состояние signaled по окончании выполнения буфера команд. Мы можем использовать барьер для уведомления о создании кадра.void drawFrame() {
...
if (vkQueueSubmit(graphicsQueue, 1, &submitInfo, inFlightFences[currentFrame]) != VK_SUCCESS) {
throw std::runtime_error("failed to submit draw command buffer!");
}
...
}Теперь осталось изменить начало функции
drawFrame, чтобы дождаться создания кадра:void drawFrame() {
vkWaitForFences(device, 1, &inFlightFences[currentFrame], VK_TRUE, UINT64_MAX);
vkResetFences(device, 1, &inFlightFences[currentFrame]);
...
}Функция
vkWaitForFences принимает массив барьеров и ждет, когда один из них или все барьеры перейдут в состояние signaled перед возвратом функции. VK_TRUE обозначает, что выполняется ожидание всех барьеров, но в случае с одним барьером, очевидно, это не имеет значения. Как и vkAcquireNextImageKHR, эта функция также принимает в качестве параметра время ожидания. В отличие от семафоров, нам нужно вручную установить барьер в состояние unsignaled, сбросив его с помощью вызова vkResetFences.Если запустить программу сейчас, можно заметить, что что-то не так. Кажется, будто ничего не рендерится. Если у вас были включены слои валидации, появится следующее сообщение:
Это значит, что ожидаемый барьер не был отправлен. Проблема в том, что по умолчанию барьеры создаются в состоянии unsignaled. Поэтому, если барьер не использовался ранее,
vkWaitForFences будет ждать бесконечно. Для решения этой проблемы мы можем изменить создание барьера, чтобы инициализировать его в состоянии signaled:void createSyncObjects() {
...
VkFenceCreateInfo fenceInfo{};
fenceInfo.sType = VK_STRUCTURE_TYPE_FENCE_CREATE_INFO;
fenceInfo.flags = VK_FENCE_CREATE_SIGNALED_BIT;
...
}Утечка памяти устранена, но программа работает не совсем корректно. Если число
MAX_FRAMES_IN_FLIGHT больше, чем количество images в swap chain или vkAcquireNextImageKHR возвращает images не по порядку, есть вероятность, что мы можем начать рендеринг в image, который уже находится в конвейере (in flight). Чтобы этого избежать, нужно отслеживать каждый image из swap chain и проверять, не использует ли его в текущий момент кадр в конвейере.Для этого добавим новый список
imagesInFlight:std::vector<VkFence> inFlightFences;
std::vector<VkFence> imagesInFlight;
size_t currentFrame = 0;Подготовим его в
createSyncObjects:void createSyncObjects() {
imageAvailableSemaphores.resize(MAX_FRAMES_IN_FLIGHT);
renderFinishedSemaphores.resize(MAX_FRAMES_IN_FLIGHT);
inFlightFences.resize(MAX_FRAMES_IN_FLIGHT);
imagesInFlight.resize(swapChainImages.size(), VK_NULL_HANDLE);
...
}Изначально ни один кадр не использует image, поэтому мы явно инициализируем его как «без барьеров». Изменим функцию
drawFrame, чтобы дождаться любого из предыдущих кадров, использующих image, который мы только что ассигновали новому кадру:void drawFrame() {
...
vkAcquireNextImageKHR(device, swapChain, UINT64_MAX, imageAvailableSemaphores[currentFrame], VK_NULL_HANDLE, &imageIndex);
// Check if a previous frame is using this image (i.e. there is its fence to wait on)
if (imagesInFlight[imageIndex] != VK_NULL_HANDLE) {
vkWaitForFences(device, 1, &imagesInFlight[imageIndex], VK_TRUE, UINT64_MAX);
}
// Mark the image as now being in use by this frame
imagesInFlight[imageIndex] = inFlightFences[currentFrame];
...
}Поскольку вызовов
vkWaitForFences стало больше, вызов vkResetFences следует переместить. Лучше всего вызвать его прямо перед использованием барьера:void drawFrame() {
...
vkResetFences(device, 1, &inFlightFences[currentFrame]);
if (vkQueueSubmit(graphicsQueue, 1, &submitInfo, inFlightFences[currentFrame]) != VK_SUCCESS) {
throw std::runtime_error("failed to submit draw command buffer!");
}
...
}Мы настроили всю необходимую синхронизацию, чтобы в очередь не отправлялось более двух кадров и чтобы эти кадры случайно не использовали один и тот же image. Обратите внимание, что, например для окончательной очистки, может использоваться более грубая синхронизация, такая как
vkDeviceWaitIdle. Вам нужно решить, какую синхронизацию использовать, исходя из функциональных требований.Чтобы узнать о синхронизации больше, предлагаем ознакомиться с подробным обзором Khronos.
Выводы
Написав чуть более 900 строк кода, мы наконец-то видим результат нашей работы на экране! Безусловно, настройка программы с Vulkan занимает немало времени, но благодаря тому, что состояния в Vulkan должны описываться явно, вы можете контролировать многие процессы. Я рекомендую вам потратить чуть больше времени и еще раз перечитать код, чтобы понять назначение всех объектов Vulkan и то, как они соотносятся друг с другом.
В следующей главе мы рассмотрим еще одну деталь, необходимую для правильной работы программы с Vulkan.
C++ code / Vertex shader / Fragment shader
 — руководство новичка")
