
Я общался с десятками QA-инженеров из разных компаний и каждый из них рассказывал о том, что у них используют разные системы и инструменты для баг-трекинга. Мы тоже пробовали несколько из них и я решил поделиться решением, к которому мы пришли.

Буду банален. Ошибки появляются и обнаруживаются на различных этапах процесса разработки. Поэтому можно разделить баги на категории, в зависимости от времени их обнаружения:
Два года назад у нас была выделенная команда тестировщиков, которые вручную тестировали продукт после интеграции кода всех команд. До этого момента код проверялся разработчиками на девелоперских стендах. Ошибки которые находили тестировщики заносились в бэклог в Jira. Баги хранились в общем бэклоге и переезжали из спринта в спринт с другими задачами. Каждый спринт два-три бага доставались и чинились, но большинство оставалось на дне бэклога:
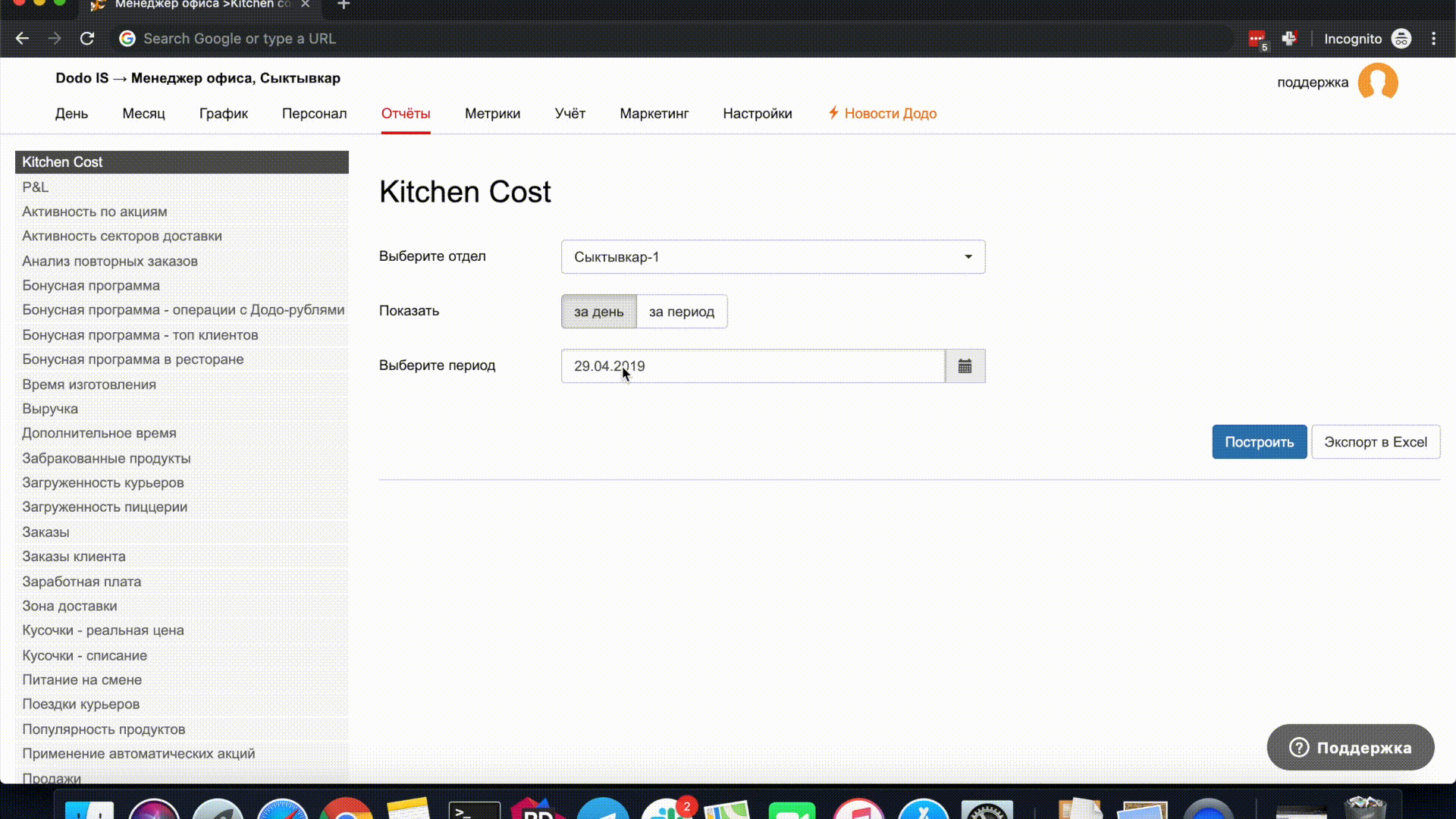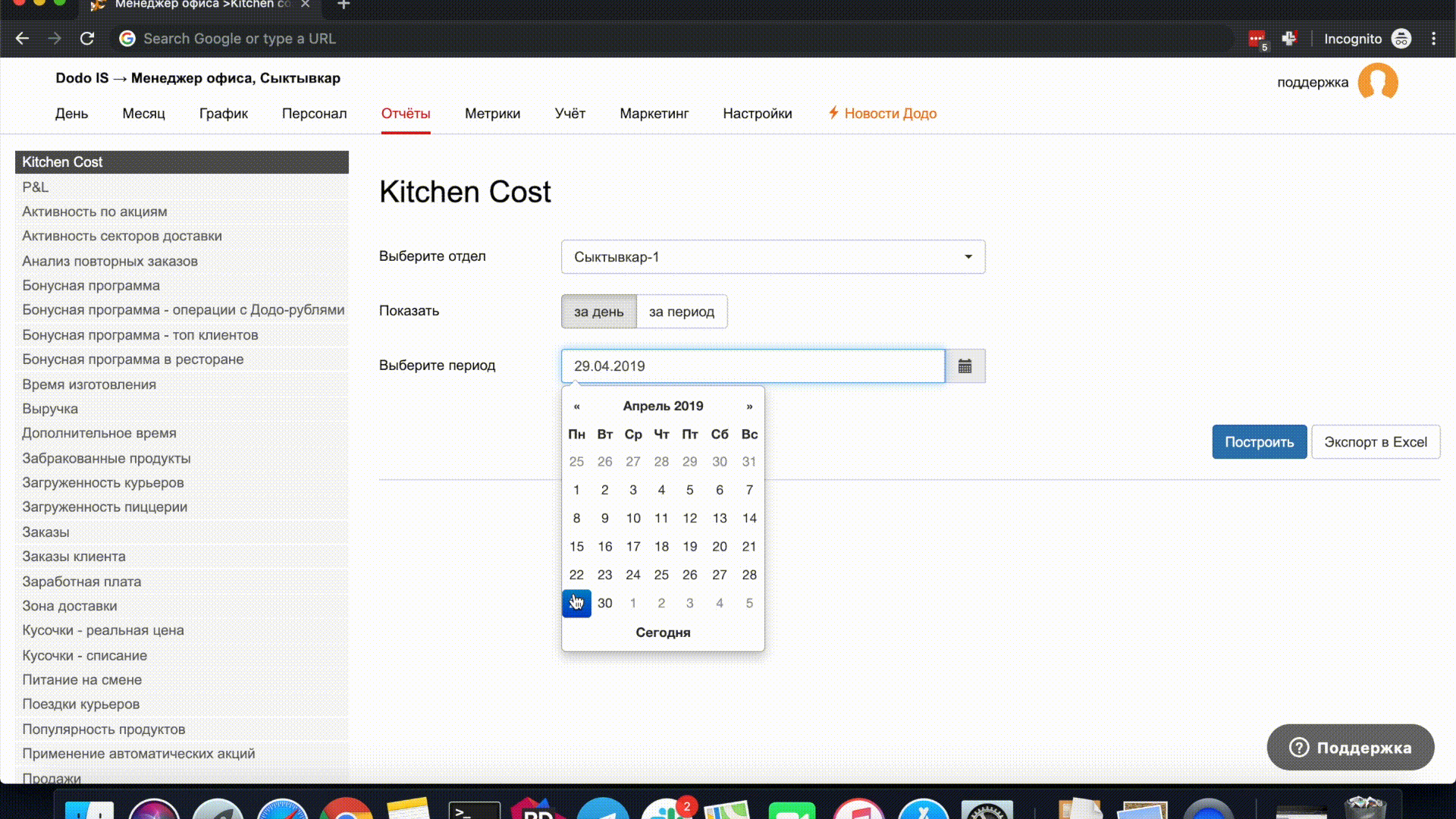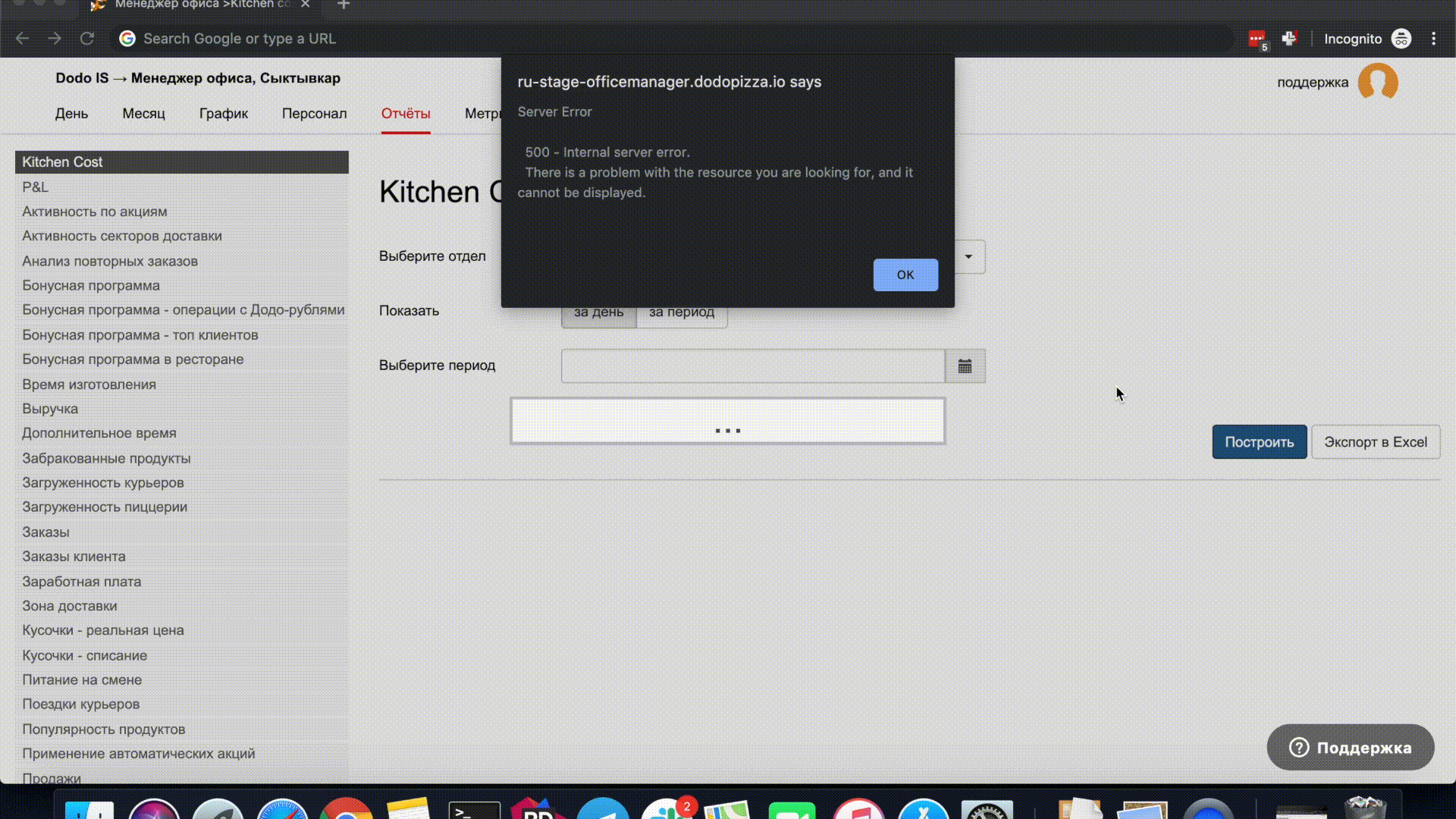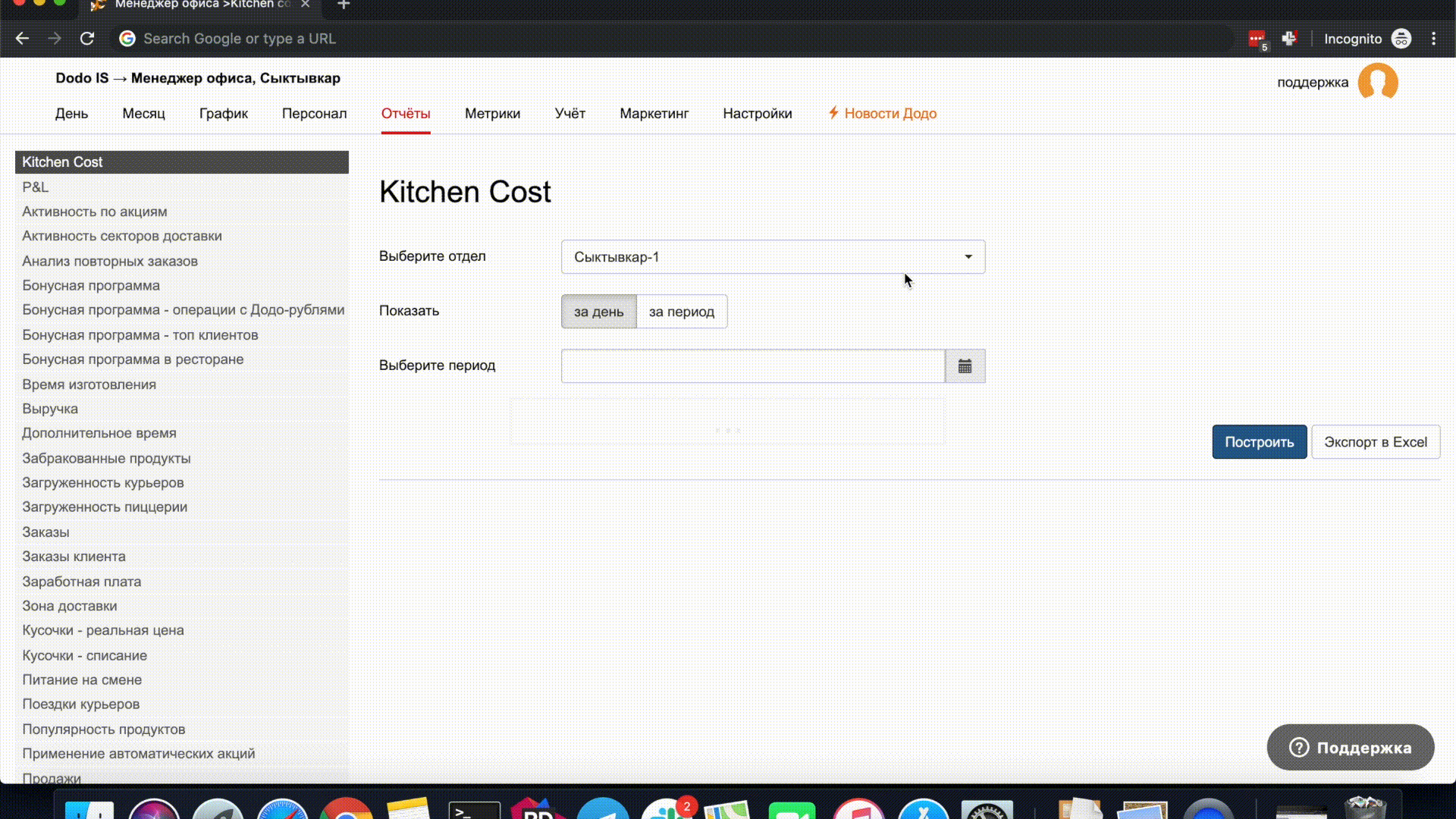
Приведу простой пример. При построении отчётов в полях ввода даты по умолчанию подставляется сегодняшний день. При изменении даты в попапе можно снова выбрать сегодняшний день и поле ввода даты очистится.
У меня есть подозрения, что за все время работы нашей сети, никто, кроме тестировщиков не воспроизводил эту ошибку. Такого рода ошибки и составляют большинство багов, которые не исправляются.
При таком подходе, когда заносятся все найденные баги, некоторые из них дублируются и большинство из этих багов не чинится возникают проблемы:
Весной 2018 года мы отказались от Jira и перешли в Kaiten. Смена инструментов была вызвана причинами, о которых Андрей Арефьев написал в статье «Почему Додо Пицца стала использовать Kaiten вместо связки Trello и Jira». После перехода в Kaiten наш подход к работе с багами не изменился:

Мы решили поэкспериментировать с форматами и создали отдельную доску в Kaiten, на которой хранили баги и меняли статусы. Мы упростили заведение баг-репорта, чтобы тратить меньше времени. При добавлении карточки в Kaiten тестировщики помечали разработчиков. Об этом им на почту отправлялось уведомление. Мы вывели эту доску на монитор, который висел в проходе рядом с нашим рабочим местом, чтобы разработчики видели прогресс и процесс тестирования стал прозрачным. Эта практика тоже не прижилась, потому что основной канал общения – Slack. Наши разработчики не проверяют почту часто. Поэтому это решение быстро перестало работать и мы снова вернулись к Slack.
После неудачного эксперимента с доской в Kaiten, некоторые разработчики всё ещё были против формата с сообщением в Slack. И мы стали думать как трекать баги в слаке и решить проблемы, которые мешали разработчикам. В результате поисков наткнулись на приложение для Slack, Workast, которое помогает организовать работу с тудушками прямо в мессенджере. Мы подумали, что это приложение позволит управлять процессом работы с багами более гибко. У этого приложения были свои плюсы: смена статусов и назначение на разработчиков по одному нажатию кнопки, завершенные задачи скрывались и сообщение не разрасталось до огромных размеров.
Так выглядели решенные задачи в приложении Todo и просьбы вернуть «муравьишек». После окончания пробного периода приложения Workast мы решили от него отказаться. Потому что пользуясь этим приложением, мы пришли к тому же, что было во время, когда мы пользовались Jira. Оставались некоторые баги, которые кочевали в этом списке из регресса в регресс. И с каждой итерацией их становилось больше. Возможно, стоило доработать процесс работы с этим расширением, купить его и пользоваться, но мы этого не сделали.
В конце 2018 - начале 2019 года у нас в компании произошли ряд изменений, которые повлияли на процесс работы с багами.
Во-первых, у нас не стало выделенной команды тестировщиков. Все тестировщики разошлись в команды разработчиков, для усиление компетенции тестирования команд. Благодаря этому мы стали находить ошибки раньше, до того как произойдет интеграция кода команд.
Во-вторых, мы отказались от ручного регрессионного тестирования в пользу автоматического.
В-третьих, мы приняли «zero bug policy». В статье "#zerobugpolicy или как мы баги чиним" Антон Бевзюк подробно рассказывает как мы выбираем баги, которые чиним.
Сегодня процесс работы с багами выглядит следующим образом:
Коротко говоря, мы отказались в принципе от баг-трекинговой системы. С помощью такого подхода работы с багами мы решили несколько болей:
Я не хочу сказать, что трэкинг багов бесполезен. Баги которые мы берём в работу трэкаются как и любые другие задач. Но баг-трэкинговая система это не обязательный атрибут тестирования. Её не нужно использовать только потому, что используют большинство компаний и так принято в индустрии. Нужно «думать головой» и примерять инструменты к своим процессам и потребностям. Для нас идеально работать без баг-трекинговой системы сейчас. За пол года такой работы, мы ни разу не подумали о том, чтобы вернуться к ней и снова заводить все баги туда.
А как в вашей компании устроен процесс работы с багами?
Интро
Буду банален. Ошибки появляются и обнаруживаются на различных этапах процесса разработки. Поэтому можно разделить баги на категории, в зависимости от времени их обнаружения:
- Недоделки. Это ошибки, которые допустили разработчики, пока пилили новый функционал. Такие ошибки находят при исследовательском или приемочном тестировании новых фич на девелоперских стендах команд.
- Баги в регрессе. Это дефекты, которые находят ручные регрессионные тесты или автоматические UI и API тесты на стенде для интеграции кода.
- Баги с прода. Это проблемы, которые нашли сотрудники или клиенты и обратились в службу технической поддержки.
С чего мы начинали, или Jira
Два года назад у нас была выделенная команда тестировщиков, которые вручную тестировали продукт после интеграции кода всех команд. До этого момента код проверялся разработчиками на девелоперских стендах. Ошибки которые находили тестировщики заносились в бэклог в Jira. Баги хранились в общем бэклоге и переезжали из спринта в спринт с другими задачами. Каждый спринт два-три бага доставались и чинились, но большинство оставалось на дне бэклога:
- Одна из причин, по которой баги копятся в бэклоге – они не мешают пользователям. У таких багов низкий приоритет и их не будут чинить.
- Также, если в компании нет чётких и понятных правил заведения багов, тестировщики могут добавлять одну и ту же проблему несколько раз, потому что не смогли найти в этом списке уже добавленный баг-репорт.
- Ещё одной причиной может послужить то, что на проекте задействованы неопытные тестировщики. Ошибка начинающих тестировщиков, заносить в баг-трекинг все баги найденные во время работы. Неопытные тестировщики считают целью тестирования – поиск багов, а не предоставление информации о качестве продукта и предотвращение появления дефектов.
Приведу простой пример. При построении отчётов в полях ввода даты по умолчанию подставляется сегодняшний день. При изменении даты в попапе можно снова выбрать сегодняшний день и поле ввода даты очистится.
У меня есть подозрения, что за все время работы нашей сети, никто, кроме тестировщиков не воспроизводил эту ошибку. Такого рода ошибки и составляют большинство багов, которые не исправляются.
При таком подходе, когда заносятся все найденные баги, некоторые из них дублируются и большинство из этих багов не чинится возникают проблемы:
- Тестировщики демотивируются, так как ошибки которые они находят не исправляются разработчиками. Складывается ощущение, что работа не имеет смысла.
- Владельцу продукта сложно управлять бэклогом с большим количеством багов.
Прощай Jira, да здравствует Kaiten
Весной 2018 года мы отказались от Jira и перешли в Kaiten. Смена инструментов была вызвана причинами, о которых Андрей Арефьев написал в статье «Почему Додо Пицца стала использовать Kaiten вместо связки Trello и Jira». После перехода в Kaiten наш подход к работе с багами не изменился:
- Недоделки заносились на командные доски и разработчики самостоятельно решали чинить их или нет.
- Баги, которые нашли в регрессе (его проводила выделенная команда тестировщиков), чинили в релизной ветке и не релизили код, пока все проблемы не были исправлены. Мы решили, что логичнее вести и собирать информацию об этих проблемах в канале тестировщиков в Slack. Тестировщики писали сообщение, которое содержало легенду, список багов с логами и имена разработчиков, которые взяли задачу в работу. С помощью эмоджи меняли статус, а в трэдах обсуждали, прикладывали скрины, синхронизировались. Тестировщиков этот формат устраивал. Некоторым разработчикам не нравился такой способ, потому что в чате параллельно шла другая переписка и это сообщение уходило наверх и его не было видно. Мы его закрепляли, но это не сильно упрощало жизнь.
- Баги которые нашли на проде заносились в бэклог, Product Owner, расставлял приоритеты и выбирал те, которые будем чинить.
Время экспериментов, или нет
Мы решили поэкспериментировать с форматами и создали отдельную доску в Kaiten, на которой хранили баги и меняли статусы. Мы упростили заведение баг-репорта, чтобы тратить меньше времени. При добавлении карточки в Kaiten тестировщики помечали разработчиков. Об этом им на почту отправлялось уведомление. Мы вывели эту доску на монитор, который висел в проходе рядом с нашим рабочим местом, чтобы разработчики видели прогресс и процесс тестирования стал прозрачным. Эта практика тоже не прижилась, потому что основной канал общения – Slack. Наши разработчики не проверяют почту часто. Поэтому это решение быстро перестало работать и мы снова вернулись к Slack.
Верните муравьишек
После неудачного эксперимента с доской в Kaiten, некоторые разработчики всё ещё были против формата с сообщением в Slack. И мы стали думать как трекать баги в слаке и решить проблемы, которые мешали разработчикам. В результате поисков наткнулись на приложение для Slack, Workast, которое помогает организовать работу с тудушками прямо в мессенджере. Мы подумали, что это приложение позволит управлять процессом работы с багами более гибко. У этого приложения были свои плюсы: смена статусов и назначение на разработчиков по одному нажатию кнопки, завершенные задачи скрывались и сообщение не разрасталось до огромных размеров.
Так выглядели решенные задачи в приложении Todo и просьбы вернуть «муравьишек». После окончания пробного периода приложения Workast мы решили от него отказаться. Потому что пользуясь этим приложением, мы пришли к тому же, что было во время, когда мы пользовались Jira. Оставались некоторые баги, которые кочевали в этом списке из регресса в регресс. И с каждой итерацией их становилось больше. Возможно, стоило доработать процесс работы с этим расширением, купить его и пользоваться, но мы этого не сделали.
Наш идеальный способ по работе с багами сейчас
В конце 2018 - начале 2019 года у нас в компании произошли ряд изменений, которые повлияли на процесс работы с багами.
Во-первых, у нас не стало выделенной команды тестировщиков. Все тестировщики разошлись в команды разработчиков, для усиление компетенции тестирования команд. Благодаря этому мы стали находить ошибки раньше, до того как произойдет интеграция кода команд.
Во-вторых, мы отказались от ручного регрессионного тестирования в пользу автоматического.
В-третьих, мы приняли «zero bug policy». В статье "#zerobugpolicy или как мы баги чиним" Антон Бевзюк подробно рассказывает как мы выбираем баги, которые чиним.
Сегодня процесс работы с багами выглядит следующим образом:
- Недоделки. Тестировщики сообщают о проблеме аналитикам или продакт менеджерам. Идут ногами, показывают, воспроизводят, объясняют как это повлияет на клиентов и решают нужно ли это починить до релиза или можно починить позже, а может даже и не стоит чинить совсем.
- Баги в регрессе, которые нашли автотесты, чинит команда, которая трогала этот участок системы и мы не релизим этот код, пока не решим проблему. Тестировщики фиксируют эти баги в произвольном формате в канале релиза в Slack.
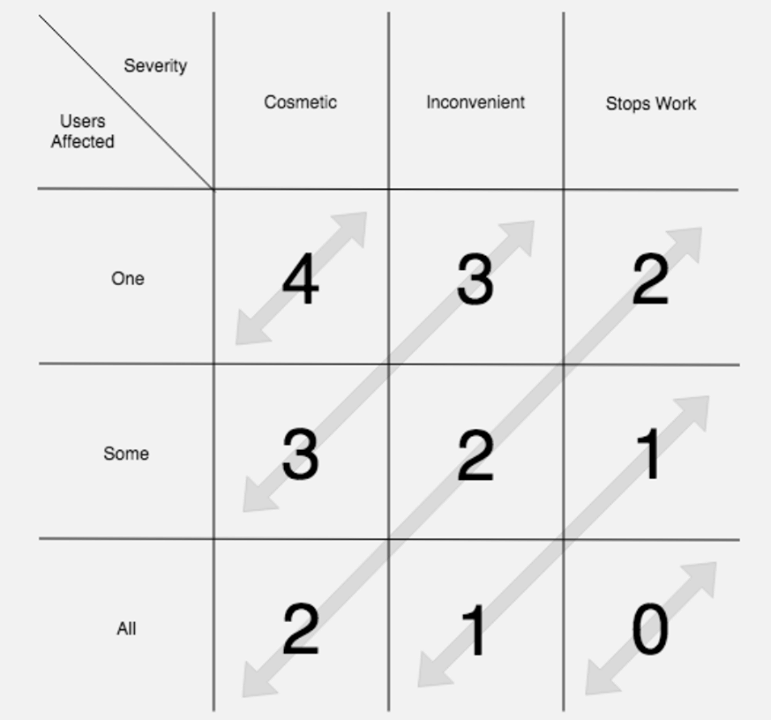
- Баги с прода. Такие баги попадают напрямую к владельцам задач. Аналитики прогоняют ошибки по Матрице приоритетов бага и добавляют в бэклог либо фиксируют у себя, накапливая статистику обращений по этой проблеме.
Итоги
Коротко говоря, мы отказались в принципе от баг-трекинговой системы. С помощью такого подхода работы с багами мы решили несколько болей:
- Тестировщики не расстраиваются из-за того, что ошибки, которые они находят и заводят в баг-трэкинг не исправляются.
- Тестировщики не тратят время на заведение и полное описание багов, которые даже никто не прочтёт.
- PO проще управлять бэклогом, в котором нет мёртвого груза.
Я не хочу сказать, что трэкинг багов бесполезен. Баги которые мы берём в работу трэкаются как и любые другие задач. Но баг-трэкинговая система это не обязательный атрибут тестирования. Её не нужно использовать только потому, что используют большинство компаний и так принято в индустрии. Нужно «думать головой» и примерять инструменты к своим процессам и потребностям. Для нас идеально работать без баг-трекинговой системы сейчас. За пол года такой работы, мы ни разу не подумали о том, чтобы вернуться к ней и снова заводить все баги туда.
А как в вашей компании устроен процесс работы с багами?




