
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Я каждый день пишу код на сишарпе, и натыкаюсь на одну проблему: я трачу кучу времени на то, чтобы решить, как быть, если что-то идёт не по плану.
У меня есть приличный опыт работы с другими языками программирования, и стандартный подход по работе с ошибками в C# мне не нравится. Но языки и платформы устроены так, что ты решаешь проблемы не как считаешь нужным, а так, как принято.
Эти размышления меня измучили, и я систематизировал свои знания и идеи по обработке исключительных случаев.
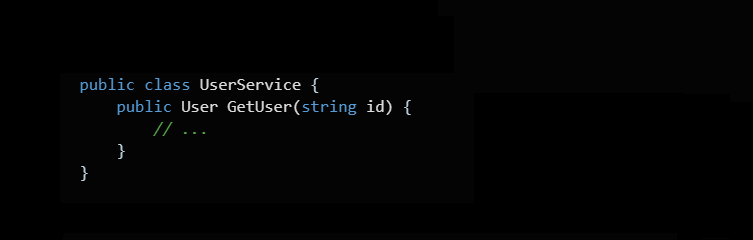
Возьму простой пример. Допустим у нас есть сервис, который отдаёт нам модель юзера по Id.
Вот такой:
Если мы передадим айдишник существующего юзера, метод отработает корректно, и мы получим свои данные. Но. Такого пользователя может не быть в системе, и вот тут нам нужно сесть, и хорошенько подумать, как должен вести себя этот метод.
Давайте посмотрим, какие у нас есть варианты.
Классический подход к таким вещам в C# — исключения
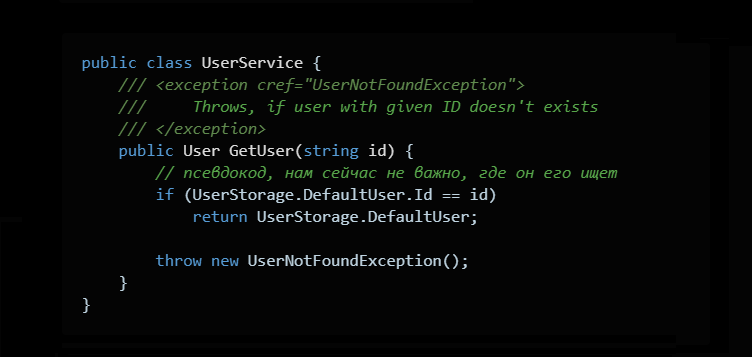
Тут все просто. Метод ищет пользователя, если, не находит — выплевывает исключение.
Примерно так:
Пользоваться таким методом можно вот так:

Плюсы подхода очевидны.
- Именно этого и ожидает пользователь твоего кода, когда человек использует метод, который в теории может сломаться, первое что он делает — смотрит в его доке, какие исключения выбрасывает этот метод. И затем обрабатывает их.
- Исключения «всплывают» вверх по стеку вызовов, позволяя легко передать ответственность по обработке ошибки на верхний уровень
- Поддержка исключений в C# нативная, есть специальные конструкции, чтобы их обрабатывать, удобный механизм обработки специальных типов исключений
Но минусов — тьма. И просто закрыть глаза на них — не получится.
- Никаких гарантий. Вообще никаких. Человек который использует твой сервис, может даже и не подумать о том, что тут что-то надо обрабатывать. Или обработает не все возможные. Если их не обработают на месте, а обработают выше, в том коде, который на такие исключения не рассчитан — могут возникнуть достаточно большие проблемы.
- Тебе придется скрупулёзно писать и обновлять документацию такого метода, и компилятор тебе не будет гарантировать, что ты описал всё, что выплевываешь.
- Очень плохо подходит для случаев, когда вызывающей стороне не нужно знать, почему произошла проблема.
- В доменном коде тебе постоянно нужно будет добавлять свои типы исключений, они раздувают кодовую базу, часто дублируются и требуют поддержки.
- Когда метод потенциально выплевывает пять шесть типов исключений, код превращается в нечитаемое говно — и код метода, и код использования.
- В сишарпе принято использовать интерфейсы. Если есть какой-то сервис, и есть код, который его использует, то мы в этом коде работаем с интерфейсом сервиса. Так вот выкидывается исключение или нет — интерфейс это не определяет НИКАК. Т.е. если кто-то написал класс, который имплементит такой-то интерфейс, и внутри этого класса он выкидывает исключение, и он даже внес это в доку класса — я при использовании этого кода об этом НЕ УЗНАЮ.
Лучше всего понять, чем плохи исключения, можно, когда используешь чужой, плохо задокументированный код. Есть условный метод GetById, а что он станет делать, если не найдет — ну ты понятия не имеешь. Вернет null? Выбросит какое-то исключение? Я писал код, в котором вызывал чужой метод, оборачивал в try-catch, и чекал результат на нулл. Создателя того метода я бы с радостью прибил. Ну, по крайней мере в тот момент.
Ещё один распространненый способ разруливать это — try pattern.
Идея завязана на out параметры в сишарпе. Выглядит вот так:
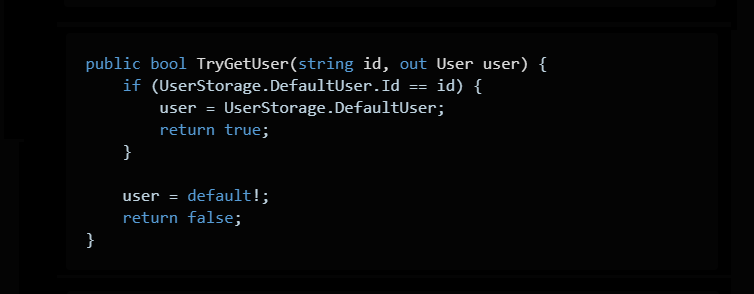
Если все норм, мы возвращаем true, и присваиваем out переменной user найденное значение. Если не норм, отдаём false, а out переменную заполняем дефолтным значением (в случае с классом это будет null).
Использовать такой метод следует так:
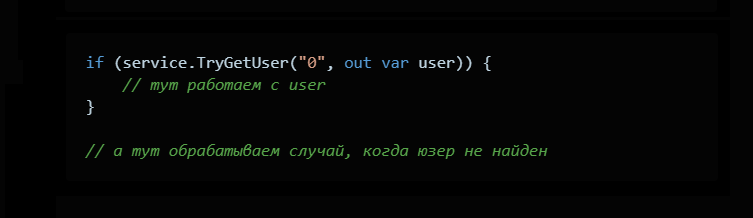
У подхода много плюсов:
- Он идиоматичен. Такая конвенция знакома всем шарпистам, она используется в родных коллекциях, все знаю, как с этим работать.
- Способ надежен. Просто проигнорировать возможную проблему не получится. Ведь метод возвращает bool, и пользователь кода вынужден будет обратить внимание на твою задумку.
- Код использования выглядит достаточно лаконично и понятно.
- Отлично подходит для ситуаций, когда причина возможной неудачи очевидна — Мы не тащим очевидную информацию в стиле «not found».
- Не нужно создавать дополнительные файлы исключений, сама реализация очень проста синтаксически — метод не перегружается лишним кодом и докой.
- Мы явным образом снимаем с себя ответственность за обработку неудачи, и передаем её вызывающему коду.
Минусы тоже есть:
- Это все ещё конвенция. Никто не мешает пользователю кода просто вызвать метод, не проверять возвращаемое значение, и начать использовать out-параметр.
- Не подходит для случаев, когда хотим передать вызывающему коду причину ошибки. На самом деле, мы можем добавить второй out-параметр, error: Exception, но тогда мы потеряем бОльшую часть плюсов. Особенно если типов ошибок может быть несколько.
- Вся лаконичность пойдет к черту, код испортиться. Кроме того, это уже не будет общепринятой конвенцией, и есть шанс, что коллеги начнут крутить пальцем у виска. Так же есть вариант определять Enum со статусом операции, и возвращать его вместо bool.
- Не работает с async-ами. C# это не поддерживает, и, похоже, не будет.
- Плохо сочетается с новой фичей из C#8 — nullable. Потому что тип out параметра у нас по факту nullable, но если мы скажем об этом компилятору, он заставит пользователя кода проверять его дважды. А если не укажем, то у нас будет nullable параметр, у которого тип — NotNullable. Может вводить в заблуждение, и в целом очень неприятный расклад.
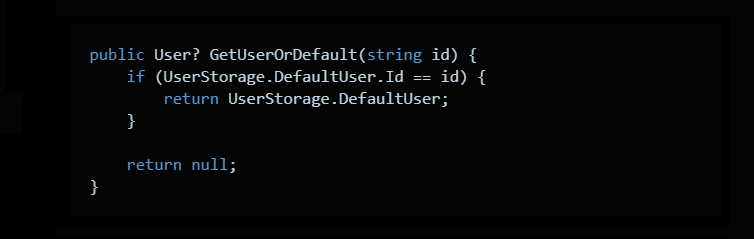
Очень похожий способ — SomeOrDefault.
Тоже распространенный для дотнета подход, когда мы отдаем найденное значение, а иначе null.
Делается так:
А использовать вот так:
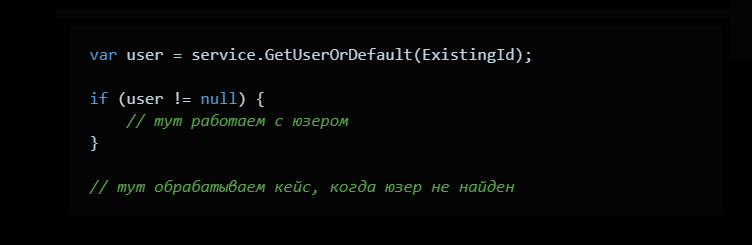
Плюсы:
- Он так же идиоматичен. Все знают, что значит постфикс OrDefault, подход используется в родных коллекциях.
- Начиная с C#8 этот способ так же может быть надежным. Если в вашем проекте включена фича компилятора nullable, и вы не кладете болт на варнинги, SomeOrDefault-а достаточно, чтобы гарантировать обработку провала.
- Код использования — самое идиоматичное, что вообще можно увидеть в сишарпе. Все всё поймут. И его очень мало.
- Так же подходит для ситуаций, когда причина возможной неудачи очевидна.
- Никаких дополнительных файлов и нагрузки на реализатора — это очень легко написать и поддерживать.
Минусы:
- Это конвенция. Люди могут ей не следовать, или даже не знать о ней.
- Не подходит для случаев, когда хотим передать вызывающему коду причину ошибки.
- Если у вызывающего кода не C#8+ с включенным нулабл, единственная гарантия — это нейминг. Очень склизская гарантия.
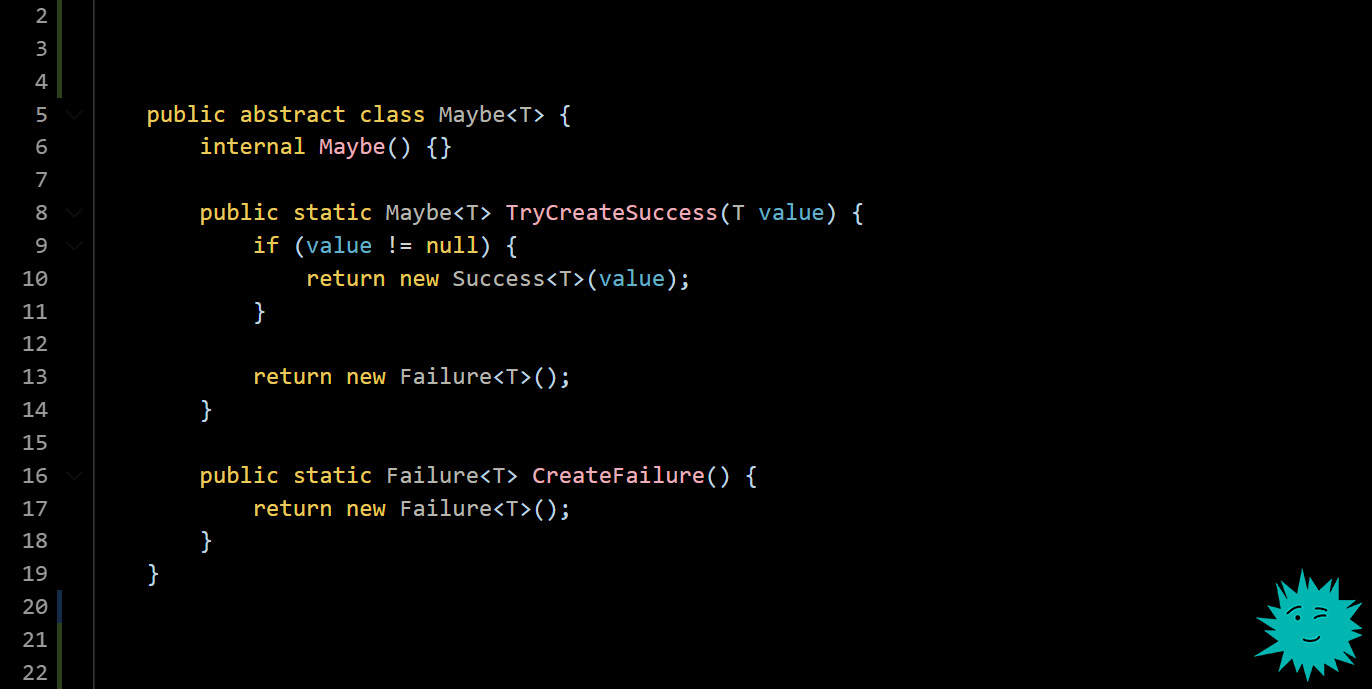
Наивысшая надежность — Maybe монада.
Идея простая. Есть отдельная сборка, в ней лежит абстрактный класс Maybe, у него два наследника, Success и Failure. Отдельная сборка и интёрнал конструктор нужны, чтобы гарантировать — наследников всегда будет только два.
Тогда метод будет выглядеть вот так:
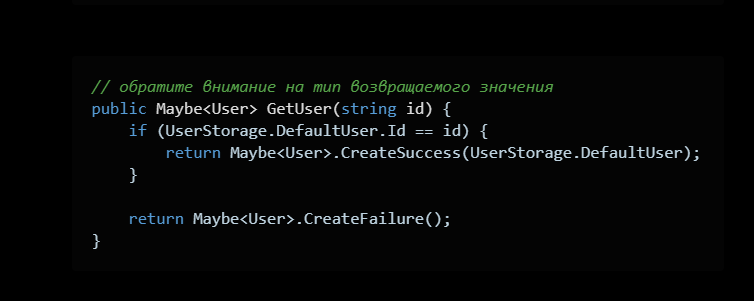
Фишка подхода в том, что мы закрепляем возможную неудачу типом возвращаемого значения. И теперь наши гарантии будет обеспечивать уже компилятор.
Использовать код можно например так:
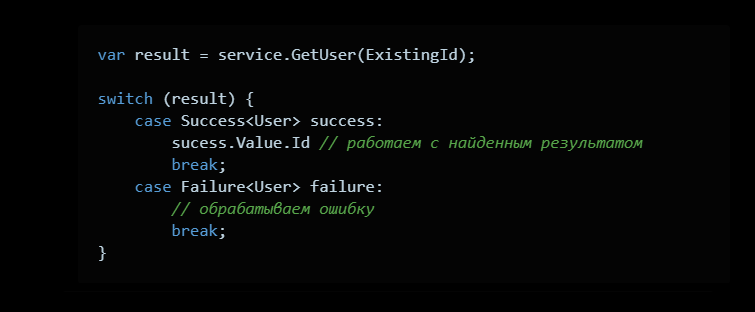
Здесь не так много плюсов, но они очень увесистые.
- Гарантии, надежность. Есть только один способ обойти нашу защиту — взять, и руками скастить результат к Success. Но это я не знаю, кем надо быть.
- Мы легко можем протаскивать необходимую информацию об ошибке через класс Failure. Здесь много чего можно наинженерить, но главное — возможности для этого есть. Правда это будет уже не Maybe, а Result монада, но какая разница.
- Вербозность. По коду, который отдаёт Maybe сразу понятно, что все может пойти не по плану.
- Сам тип Maybe может быть один, универсальный на весь проект.
- Подход отлично масштабируется на асинхронный код.
- Легко разделять ответственность — мы можем сделать методы, которые готовы работать с Maybe, и метода, которые не готовы. Так мы построим приложение, в котором четко, на уровне типов разделена ответственность по обработке ошибок.
А минусы — паршивые.
- Это совсем не идоматично. Твои коллеги не будут ожидать такие штуки, для C# такая практика — довольно спорная.
- Костыльная реализация. Мы эмулируем Discriminated Union из фп с помощью наследования, но это именно что эмуляция. Поэтому компилятор не будет нам верить, что есть всего два возможных наследника, а будет плевать в нас варнингами, что наш switch-expression не обработал все возможные случаи.
- Все ещё не полная надежность.
- Переусложнение кода, не всегда оправданное.
Короче, монады хороши с логической точки зрения, но их реализация в текущем сишарпе выглядит ну очень некрасиво и непривычно. Это само по себе — большая проблема. Но она скоро решится — разработчики языка обещают поставить в одной из будущих версий Discriminated Unions — именно с помощью таких конструкций монады реализованы во всяких F#-ах или Haskell-ях. Код с монадами перестанет быть уродливым и запутанным, но остается проблема с тем, что подход для шарпистов непривычен. Кроме того весь уже написанный код набит исключениями, и переезжать никто не будет, а куча разных способов решать одинаковые проблемы в одном проект — это совсем не хорошая идея.
Способов борбы с исключениями несколько, не очень понятно, когда и какой использовать.
Если мне не нужно знать, что там за ошибка, сам случай не сверх критичный, у меня C#8+ со включенным nullable, у всех пользователей кода тоже — я бы использовал SomeOrDefault. Если Nullable нету, тогда tryPattern. Если момент критичный, тогда Maybe.
Если у меня нет nullable, и кейс асинхронный — значит try pattern и someOrDefault мне не пойдет, и тогда я бы тоже взял Maybe.
Соответственно, если хотим передать данные об ошибке, тогда лучше использовать Result монаду.
Exception хорошо подходит для случаев:
- Когда у тебя есть модуль, в нем произошла ошибка, и это значит что с этим модулем больше работать нельзя (например сторонний сервис упал). Выплевываем исключение, ловим его где то сверху, уведомляем все заинтересованные части системы, что сервис сдох.
- Когда приложение не может продолжать свою работу. Например у нас десктопный софт, который является тонким клиентом, а сеть пропала. Бахаем ексепшн, ловим, говорим «извините», закрываемся.
- Когда понятия не имеешь, что делать в случае ошибки, да и на проект тебе насрать — тогда бы я тоже взял Ecxeption.
Самый увесистый минус Ecxeption лежит даже не в механике их работы, он в культуре использования. Процессы разработки часто устроены так, что человек понятия не имеет, что делать если операция провалилась. И он делает что, он создает исключение, выбрасывает его, и полностью снимает ответственность как с себя, так и с модуля, который он делает. Этот подход страусов, а не инженеров. Видишь проблему, запихиваешь башку в песок, и делаешь вид, что все идёт окей.
Возможно на существуещем механизме исключений в сишарпе можно было бы работать по-другому, но я думаю, с учетом всего того кода, который уже написан, они достаточно дискредетировали себя, чтобы посмотреть в сторону других практик.
Это поднимает куда более серьезную проблему. Ладно, подход с исключениями технически несовершенен, но даже если и был бы, есть штука, куда более несовершенная. Программисты. Человеческий фактор. Я вот пришел сюда, такой умный, начал учить как обрабатывать ошибки, а потом заглянул в код своих проектов, и везде вижу одно и то же- мой класс, как разработчика, недостаточно высок, я постоянно не понимаю, как разруливать исключительные ситуации. Я их игнорирую, логгирую, и прячу. Кроме тех мест, где они кому-то уже навредили, и меня заставили именно там все продумать. И никакие технические возможности языка не заставят меня продумывать все.
Но. Они заставят продумывать чуть больше, может быть, на 5%, может на 1, может на 10. И это вообще единственный способ хоть как то уменьшать влияние человеческого фактора. Поэтому, я не вижу причин, чтобы отказываться от тех же монад или гарантированно обрабатываемых исключений.
Я привел четыре концептуальных подхода к работе с ошибками, но на деле их намного больше. Например приходит в голову подход в Go — отдавать из функций кортеж (результат*ошибка). Как по мне- очень спорный способ, но я открыт к дискуссии. Делитесь мыслями в комментариях, какие ещё у нас есть варианты, и в чем их преимущество.
Код примеров лежит здесь.
На правах рекламы
Подыскиваете виртуальный сервер для отладки проектов, сервер для разработки и размещения? Вы точно наш клиент :) Посуточная тарификация серверов самых различных конфигураций, антиDDoS.

Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Какой способ ваш любимый
-
38,3%Exceptions18
-
12,8%TryPattern6
-
12,8%SomeOrDefault6
-
29,8%Maybe/Result14
-
6,4%Другое (в комментариях)3



