
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Annual Meeting of the Association for Computational Linguistics (ACL) — это главная конференция в области обработки естественного языка. Она организуется с 1962 года. После Канады и Австралии она вернулась в Европу и проходила во Флоренции. Таким образом, в этом году у европейских исследователей она была более популярна, чем похожая на нее EMNLP.
В этом году было опубликовано 660 статей из 2900 присланных. Огромное количество. Вряд ли можно сделать какой-то объективный обзор того, что было на конференции. Поэтому я расскажу своих субъективных ощущениях от этого мероприятия.
Я приехал на конференцию, чтобы показать на постер-сессии наше решение с соревнования на Kaggle про Gendered Pronoun Resolution от Гугла. Решение наше во многом опиралось на использование предобученных моделей BERT. И, как оказалось, в этом мы были не одиноки.
BERTology

Работ, основанных на BERT, описывающих его свойства и или использующих его в качестве бейзлана было столько, что появился даже термин — Бертология. Действительно, BERT модели получились такими удачными, что даже крупные исследовательские группы сравнивают свои модели с BERT-ом.
Так в начале июня появилась работа про XLNet. А непосредственно перед конференцией — ERNIE 2.0 и RoBERTa
RoBERTa от Facebook
Когда только только появилась модель XLNet, некоторые исследователи высказывали мнение, что она достигла лучших результатов не только из-за своей архитектуры и принципов обучения. Она так же обучалась на большем корпусе (почти в 10 раз), чем BERT и дольше (в 4 раза больше итераций).
Исследователи из Facebook показали, что и BERT еще не достиг своего максимума. Они представили оптимизированный подход к обучению BERT модели — RoBERTa (Robustly optimized BERT approach).
Ничего не поменяв в архитектуре модели, они изменили процедуру обучения:
- Увеличили корпус для обучения, размер батча, длину последовательности и время тренировки.
- Убрали из обучения задачу предсказания следующего предложения.
- Стали генерировать динамически MASK-токены (токены, которые и пытается предсказать модель в процессе предобучения).
ERNIE 2.0 от Baidu
Как и все популярные модели последнего времени (BERT, GPT, XLM, RoBERTa, XLNet), ERNIE базируется на концепции трансформера с self-attention механизмом. То, что его отличает от других моделей — это концепции многозадачного обучения (Multi-task learning) и непрерывного обучения (Continual learning).
ERNIE обучается на разных задачах, постоянно обновляя внутреннее представление своей языковой модели. Эти задачи имеют, как и у других моделей, самообучаемые (self-supervised и weak-supervised) цели. Примеры таких задач:
- Восстановление правильного порядка слов в предложении.
- Определение слов, начинающихся с заглавной буквы.
- Определение маскированных слов.
На этих задачах модель обучается последовательно, возвращаясь и к задачам на которых обучалась ранее.
RoBERTa против ERNIE
В публикациях RoBERTa и ERNIE не сравниваются друг с другом, поскольку появились почти одновременно. Они сравниваются с BERT и XLNet. Но и здесь не так просто провести сравнение. Например, в популярном бенчмарке GLUE XLNet представлен ансамблем моделей. А исследователей из Baidu большее интересует сравнение одиночных моделей. Кроме того, поскольку Baidu китайская компания, они так же заинтересованы в сравнении результатов работы с китайским языком. Совсем же недавно появился новый бенчмарк: SuperGLUE. Здесь пока не так много решений, но RoBERTa и здесь на первом месте.
Но в целом и RoBERTa и ERNIE показывают результаты лучше XLNet и значительно лучше BERT. В свою очередь RoBERTa работает чуть лучше ERNIE.
Графы знаний
Много было работ посвящено объединению двух подходов: предобученных сетей и использования правил в виде графов знаний (Knowledge Graphs, KG).
Вот, например: ERNIE: Enhanced Language Representation with Informative Entities. В этой работе освещают использование графов знаний поверх языковой модели BERT. Это позволяет получить лучшие результаты на таких задачах, как определение типа сущности (Entity Typing) и классификация взаимосвязей (Relation Classification).
Вообще, мода на выбор названий для моделей по именам персонажей из «Улицы Сезам» приводит к забавным последствиям. Вот, например, эта ERNIE не имеет никакого отношения к ERNIE 2.0 от Baidu, про которую я писал выше.

Еще одна интересная работа про генерацию новых знаний: COMET: Commonsense Transformers for Automatic Knowledge Graph Construction. В работе рассматривается возможность использования новых архитектур, основанных на трансформерах для обучения сетей на базах знаний. Базы знаний в упрощенном виде представляют собой множество троек: субъект, отношение, объект. Они взяли два датасета баз знаний: ATOMIC и ConceptNet. И обучали сеть, основанную на модели GPT (Generative Pre-trained Transformer). На вход подавали субъект и отношение и пытались предсказать объект. Таким образом, они получили модель, которая генерирует объекты по входным субъектам и отношениям.
Метрики
Еще одной интересной темой на конференции был вопрос выбора метрик. Часто в задачах обработки естественного языка бывает сложно оценить качество модели, что замедляет прогресс в этой области машинного обучения.
В статье Studying Summarization Evaluation Metrics in the Appropriate Scoring Range Максим Пейар рассматривает использование различных метрик в задаче суммаризации текста. Эти метрики не всегда хорошо коррелируют друг с другом, что мешает объективному сравнению различных алгоритмов.
Или вот интересная работа: Automatic Evaluation for Multi-Sentence Texts. В ней авторы представляют метрику, которая может заменить BLEU и ROUGE на задачах, где нужно оценивать тексты из нескольких предложений.
Метрику BLEU можно представить как Точность (Preсision) — сколько слов (или n-грамм) из ответа модели содержаться в таргете. ROUGE же это Полнота (Recall) — сколько слов (или n-грамм) из таргета содержаться в ответе модели.
Предложенная в статье метрика основывается на метрике WMD (Word Mover’s Distance) — расстоянии между двумя документами. Оно равно минимальному расстоянию между словами в двух предложениях в пространстве векторного представления этих слов. Подробнее про WMD можно посмотреть в тьюториале, где используется WMD из Word2Vec и из GloVe.
В своей статье они предлагают новую метрику: WMS (Word Mover’s Similarity).
WMS(A, B) = exp(−WMD(A, B))Далее они определяют SMS (Sentence Mover’s Similarity). Здесь используется подход, аналогичный подходу с WMS. В качестве векторного представления предложения они берут усредненный вектор слов предложения.
При вычислении WMS слова нормируются по их частоте в документе. При вычислении SMS предложения нормируются по количеству слов в предложении.
И наконец, метрика S+WMS — это комбинация WMS и SMS. В своей статье они указывают, что эти их метрики лучше коррелируют с оценкой человеком вручную.
Чатботы
Самой полезной частью конференции, на мой взгляд, были постер-сессии. Не все доклады были интересны, а если ты начал слушать какой-то, то уже не уйдешь на в середине доклада на другой. С постерами другое дело. На постер-сессии их несколько десятков. Выбираешь те, которые понравились и можешь, как правило, пообщаться непосредственно с разработчиком о технических деталях. Есть, кстати, интересный сайт с постерами с конференций. Правда там пока постеры с двух конференций, и неизвестно, будет ли сайт обновляться.
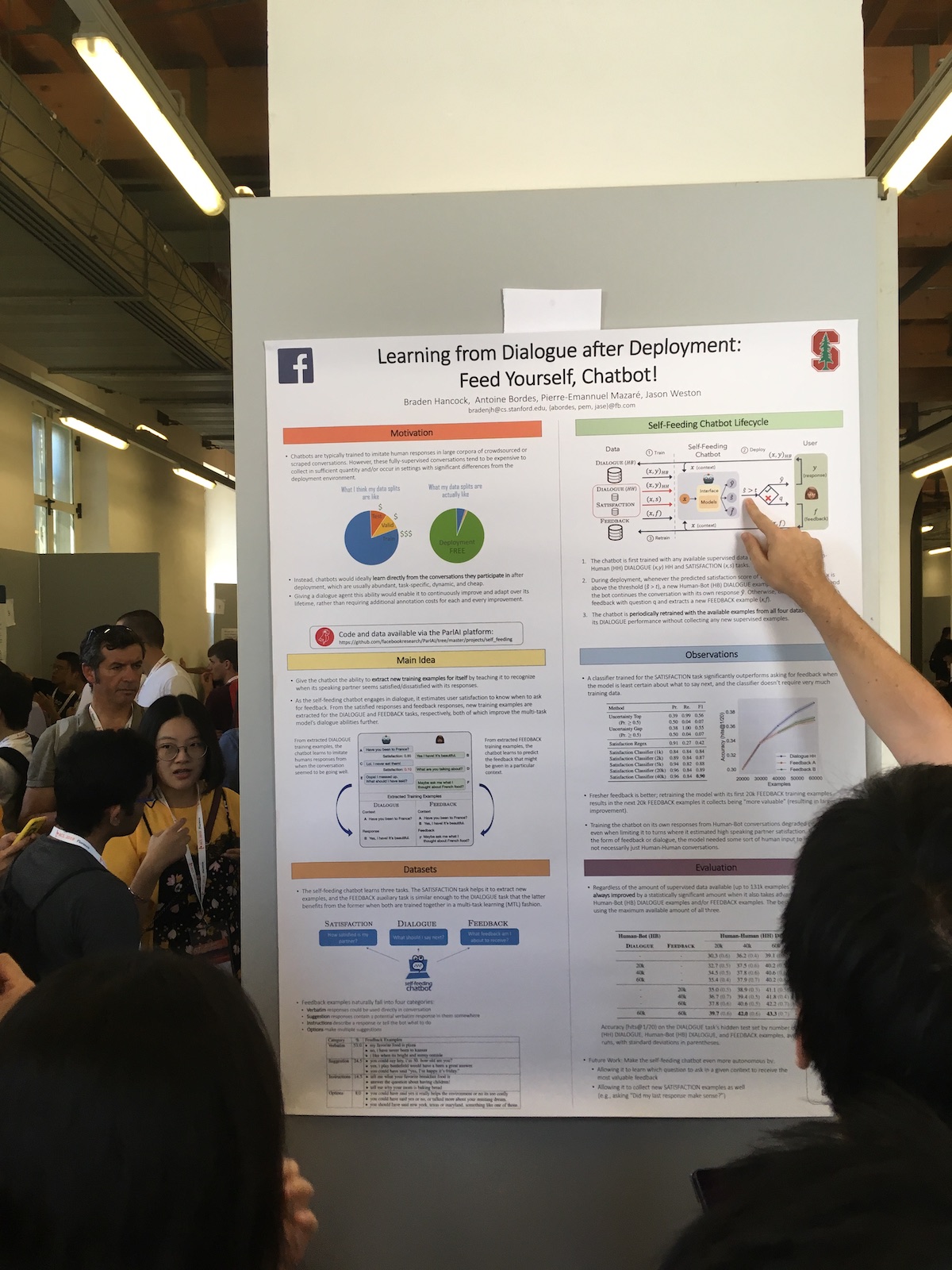
На постер-сессиях часто интересные работы представляли крупные компании. Вот, например, статья от Фейсбука Learning from Dialogue after Deployment: Feed Yourself, Chatbot!.
Особенность их системы в расширенном использовании ответов пользователей. У них есть классификатор, который по ответам оценивает, насколько пользователь удовлетворен диалогом. Эту информацию они используют для разных задач:
- Используют меру удовлетворенности как метрику качества.
- Дообучают модель, применяя таким образом подход непрерывного обучения (Continual Learning).
- Используют непосредственно в диалоге. Выражают некоторую человеческую реакцию, если пользователь удовлетворен. Или спрашивают, что не так, если пользователь неудовлетворен.
Из докладов же, был интересный рассказ про китайский чатбот от Microsoft.The design and implementation of XiaoIce, an empathetic social chatbot
Китай уже сейчас один из лидеров по внедрению технологий искусственного интеллекта. Но часто то, что происходит в Китае, недостаточно известно в Европе. А XiaoIce — удивительный проект. Он уже существует пять лет. Не так много есть работающих в данный момент чатботов такого возраста. В 2018 году у него было уже 660 млн пользователей.
В системе есть как chit-chat бот, так и система навыков. Навыков у бота уже 230. То есть, они добавляют приблизительно по одному навыку в неделю.
Для оценки же качества chit-chat бота они используют длительность диалога. Причем не в минутах, как это часто делают, а в количестве реплик в беседе. Они называют эту метрику Conversation-turns Per Session (CPS) и пишут, что на данный момент среднее ее значение 23, что является лучшим показателем среди похожих систем.
Вообще проект является очень популярным в Китае. Кроме собственно бота, система пишет стихи, рисует картины, выпускает коллекцию одежды, поет песни.
Машинный перевод
Из всех выступлений, что я посетил, самым живым был доклад о синхронном переводе Лян Хуана, представляющего Baidu Research.
Он рассказал о таких сложностях в современном синхронном переводе:
- В мире только 3000 сертифицированных синхронных переводчиков.
- Переводчики могут работать только 15-20 минут непрерывно.
- Только порядка 60% исходного текста переводится.
Перевод по целым предложениям уже достиг хорошего уровня, но для синхронного перевода еще остается место для улучшения. В качестве примера он привел их систему для синхронного перевода, которая работала на конференции Baidu World Conference. Задержка в переводе в 2018 году по сравнению с 2017 годом сократилась с 10 до 3 секунд.
Не так много команд занимается этим, и немного работающих систем существует. Например, когда Гугл переводит в онлайн-режиме фразу, которую вы пишите, он постоянно переделывает итоговую фразу. И это не является синхронном переводом, поскольку при синхронном переводе мы не можем изменить уже сказанные слова.

В своей системе они используют перевод по префиксу — части фразы. То есть, они ждут несколько слов и начинают переводить, пытаясь угадать, что дальше появится в источнике. Размер этого сдвига измеряется в словах и является адаптивным. Система после каждого шага решает, стоит ли еще подождать, или можно уже переводить. Для оценки такой задержки они вводят такую метрику: metric of Average Lagging (AL).
Основная сложность при синхронном переводе — это разный порядок слов в языках. И бороться с этим помогает контекст. Например, часто нужно переводить речи политиков, а они бывают довольно шаблонными. Но встречаются и проблемы. Тут докладчик пошутил про Трампа. Вот, говорит, если Буш прилетел в Москву, то можно с большой вероятностью предположить, что для того, чтобы встретиться с Путиным. А если куда прилетел Трамп, то он может и встретиться, и в поиграть в гольф. Вообще, при переводе люди часто придумывают, добавляют что-то от себя. А скажем, если нужно перевести какую-то шутку, и они не получается это сделать сходу, могут сказать: «Здесь была сказана шутка, просто посмейтесь».
Про машинный перевод была и статья, которая получила награду «The Best Long Paper»: Bridging the Gap between Training and Inference for Neural Machine Translation.
В ней описывается такая проблема машинного перевода. В процессе обучения мы генерируем перевод слово-за-словом, опираясь на контекст из известных слов. В процессе же использования модели, мы опираемся на контекст из только что сгенерированных слов. Здесь возникает расхождение между тренировкой модели и ее использованием.
Чтобы уменьшить это расхождение, авторы предлагают на стадии тренировки в контекст подмешивать слова, которые предсказываются моделью в процессе же тренировки. В статье обсуждается оптимальный выбор таких сгенерированных слов.
Заключение
Конечно же, конференция это не только статьи и доклады. Это так же и общение, знакомства и прочий нетворкинг. Кроме того, организаторы конференций стараются и как-то развлечь участников. На ACL, на главной вечеринке было выступление теноров, Италия все таки. А на подведении итогов были анонсы от организаторов других конференций. И самую бурную реакцию у участников вызвали сообщения от организаторов EMNLP о том, что в этом году главная вечеринка будет в Гонконгском Диснейленде, а в 2020 году конференция пройдет в Доминикане.



: все просто")
