
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Как выжить в схватке с техническим долгом? Что делать, если у вас легаси тяжелой стадии? В статье на примере трёх кейсов предлагаю разобраться, как построить процесс работы с техническим долгом и какие инженерные подходы для этого использовать.
Меня зовут Денис, я — Backend Team Lead в компании Wrike. Отвечаю за delivery в своей команде и за рост разработчиков в нескольких командах. Так получилось, что почти весь мой опыт — это работа на финтех. Я поработал на два крупных банка, а сейчас работаю в Wrike.
В банках учишься работать с системами, в которых важна надежность и отказоустойчивость. А еще там много легаси, и все это я испытал на себе как разработчик и помогал другим испытывать на себе уже как lead команды.
Wrike — это SaaS решение для совместной работы команд, которое мы продаем нашим клиентам. Мы делаем Wrike, используя Wrike для организации разработки.
Wrike разрабатывают тридцать скрам-команд. Сервис доступен 24/7, поэтому решения, которые мы делаем, должны быть надежными. Если что-то пойдет не так, то это повлияет на работу почти всех команд.
Почему звездолеты?
Звездолет — это метафора, которую я использую для описания того, с чем мы, программисты, работаем. Приложение начинается с нескольких модулей. Потом начинает разрастаться: на него приходит большая нагрузка, появляются микросервисы, коммуникация между ними, интеграции, внешние API, клиенты. Получается большая и связанная экосистема. Чем больше и старше приложение, тем более связанной становится экосистема. И тем важнее поддерживать в актуальном и надежном состоянии её значимые узлы. Становится очень грустно, когда наиболее важные из них либо не удовлетворяют сегодняшним требованиям, либо выходят из строя.
Ваш звездолет не прыгнет в варп, если работает на АИ-95. Система не проложит навигацию через четыре галактики, если центральный компьютер — это Intel Celeron.
Что такое технический долг?
Представьте, что у вас есть фича, в которой постоянно появляются баги. К вам приходит тестировщик и говорит: «Мы на этой неделе нашли там четыре новых бага». Является это техническим долгом или нет? А если наличие этой фичи блокирует другие истории, которые нужно сделать? А если с решением просто трудно работать, и вы каждый раз его рефакторите? Если на фичу жалуются пользователи? А если она не удовлетворяет требованиям, которые предъявляются к ней сегодня, или оскорбляет чувства разработчиков, которые стремятся к совершенству?
В статье под техническим долгом я буду понимать те фичи, решения или подходы, которые мешают развивать продукт дальше. Все описанные выше проблемы — это следствия наличия технического долга. Это конкретные причины: почему он есть и почему нужно с ним работать.
Алгоритм работы с техническим долгом
Для эффективной работы с техническим долгом, нужно задать три основных вопроса.
- Зачем? Зачем мы беремся с ним что-то делать? Для чего нам эта работа? Зачем тратить деньги компании, часы разработки, время инженеров? Должно быть четкое понимание, какую выгоду мы получим, решив ту или иную проблему. Из определения понятно, что технический долг блокирует развитие продукта. Работая с ним, мы получим новые функциональности и возможности.
- Что? Мы должны четко понимать, где начинается технический долг, где он заканчивается, как он выглядит и какой объем работы придется проделать для его устранения.
- Как? Действия, которые нужно сделать с техническим долгом, чтобы него от избавиться.
Для ответа на последний вопрос есть простой итерационный алгоритм из четырех шагов. Первый шаг — выделить технический долг и понять его границы. Следующий шаг — отделить его от всего остального: инкапсулировать, ввести контракт работы между решением, которое вы выделили, и всей остальной системой. После можно создать рядом новое решение, заменить его, и, тем самым, из приложения уйдет часть технического долга. Повторив эту итерацию некоторое количество раз, вы получите готовое решение.
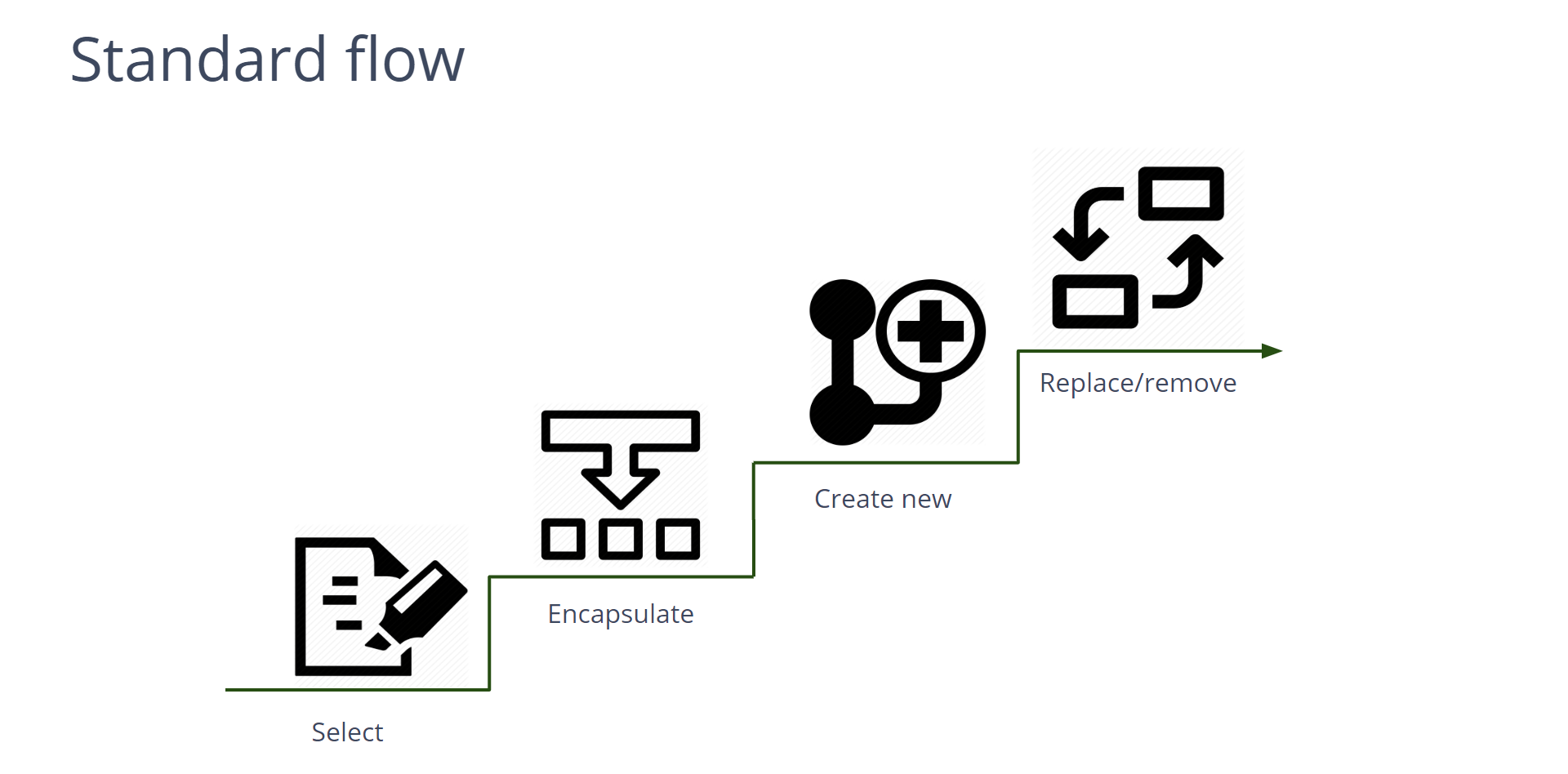
А теперь давайте посмотрим, как алгоритм работает в реальности на примере нескольких кейсов.
Первый кейс
Есть приложение, которое работает с заказами от клиентов — order management system. Приложение написано давно, в 2010-м, и построено на актуальных технологиях того времени. Приложение успешно работает в продакшн последние 9 лет, но сегодня бизнес понимает, что нужно захватывать новые рынки и развивать систему дальше. При этом важно сохранить данные и наращивать в системе новый функционал.
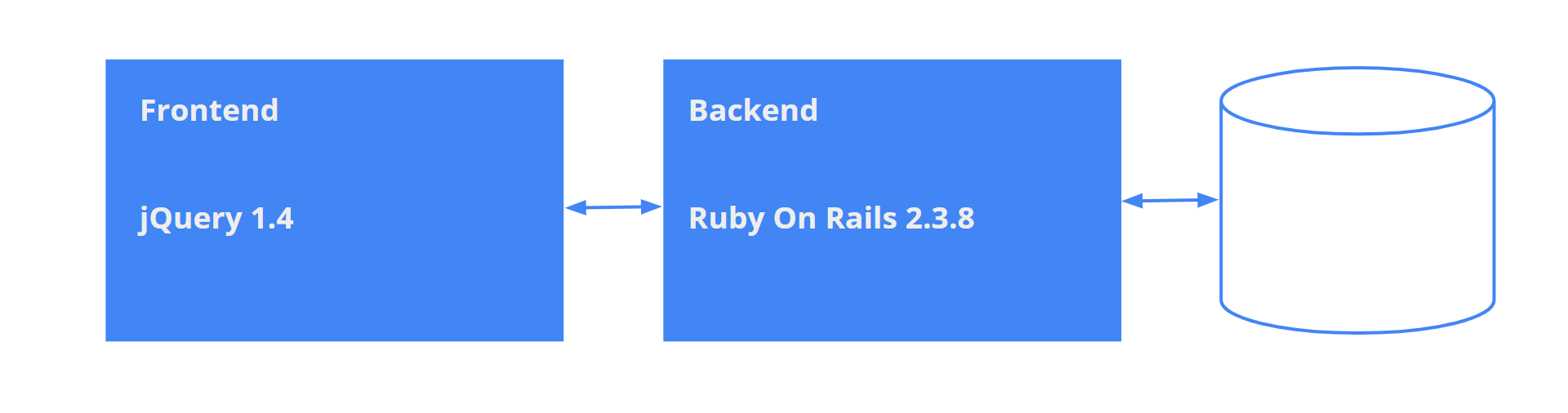
Получается, что есть давно умершие технологии, но также есть данные, которые нельзя потерять. Далеко не все возможности можно реализовать в приложении на старых технологиях. Поэтому ситуация, если быть абсолютно честным, выглядит примерно так:

Проблема здесь не в старых фреймворках, а в ситуации, которую мы имеем: приложение не поддерживается, найти разработчиков на фреймворки десятилетней давности почти невозможно. Надо что-то с этим делать.
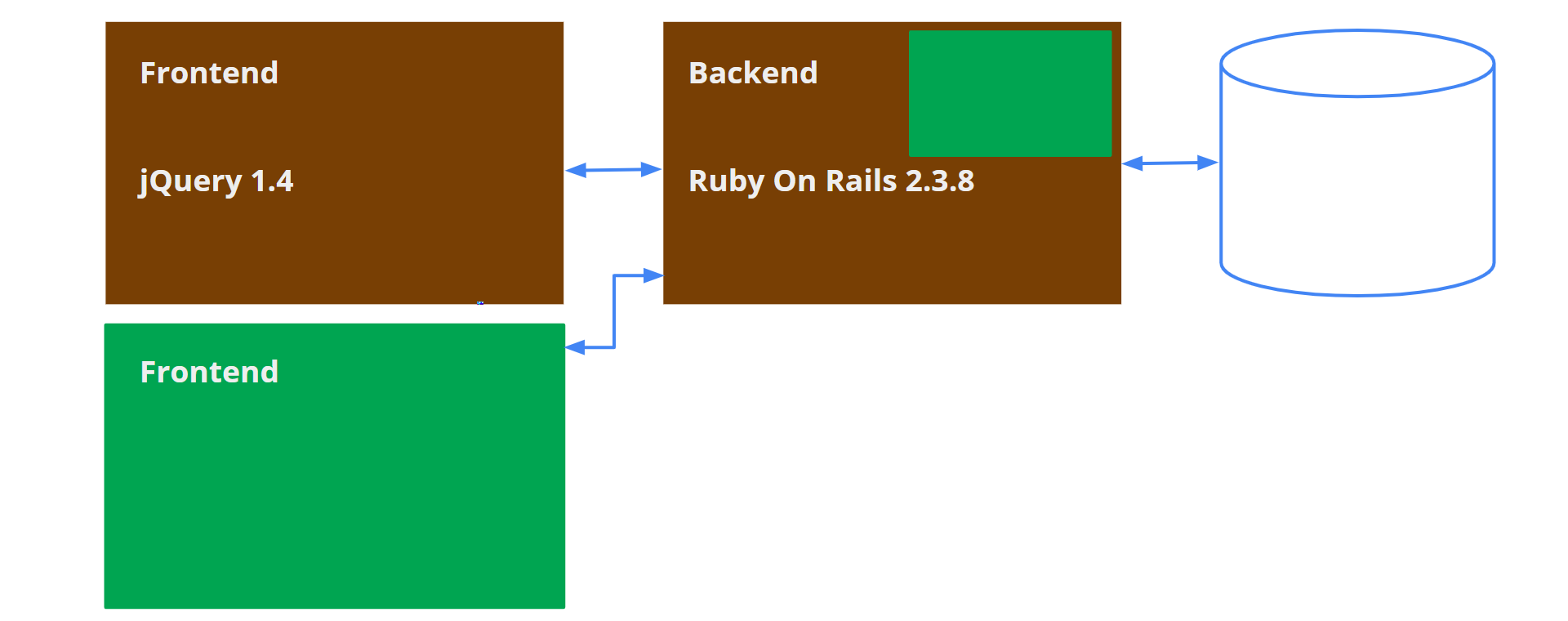
Давайте запускать алгоритм. Можно выделить несколько частей технического долга и итерационно подойти к этому процессу. Сначала разберемся с Frontend. Мы можем запустить новый Frontend, используя старый Backend. Новый Frontend мы сможем расширить, адаптировать к современным технологиям, он будет соответствовать нашим целям. Мы либо сможем целиком опираться на старый Backend, либо его придется немного доработать для работы с новым Frontend. Следующий шаг — инкапсуляция. С инкапсуляцией здесь нам помогает архитектура. Точкой инкапсуляции в данном случае будет контракт с Backend. После того, как мы запустили новый Frontend, старую часть Frontend можем убирать. Теперь все наше приложение будет становиться все зеленее и зеленее.
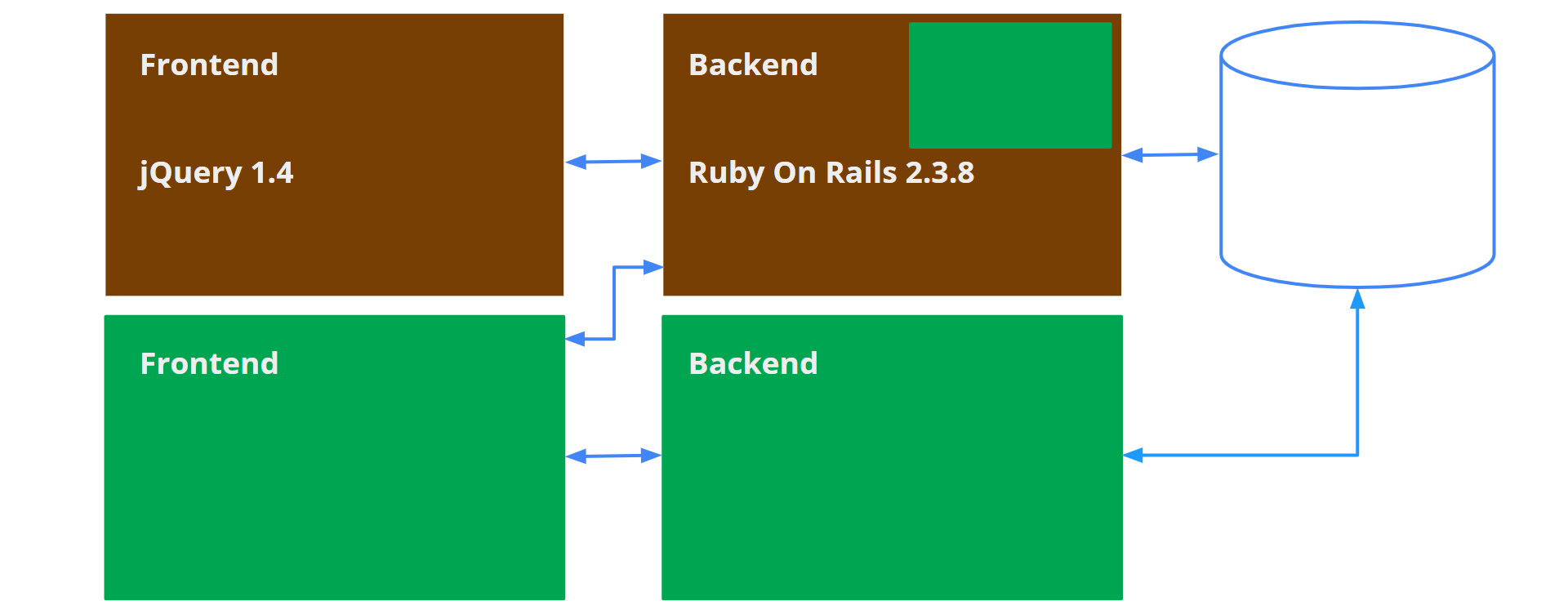
Следующий этап — работа с Backend. Здесь точкой инкапсуляции уже будет слой работы с базой данных. Получается, что архитектура опять сделает эту инкапсуляцию за нас. И мы можем сделать рядом новое решение, работающее с теми же данными, и перевести на него Frontend. Теперь мы полностью отказались от старого решения и можем его выбросить. Это позволяет нам достичь цель, которую мы ставили перед этим проектом.
Второй кейс
Возьмем кейс похитрее. Есть приложение, в нем есть конкретная фича, которая отвечает за сохранение валютных пар в базу данных. Например, рубль-доллар, доллар-йена и так далее. Информация хранится в базе данных в таблице. И, чтобы было чуть-чуть веселее, добавим парочку зависимостей: есть потребитель, который получает данные напрямую из базы, и поставщик данных, который может их поставлять, опять же, напрямую в базу данных.
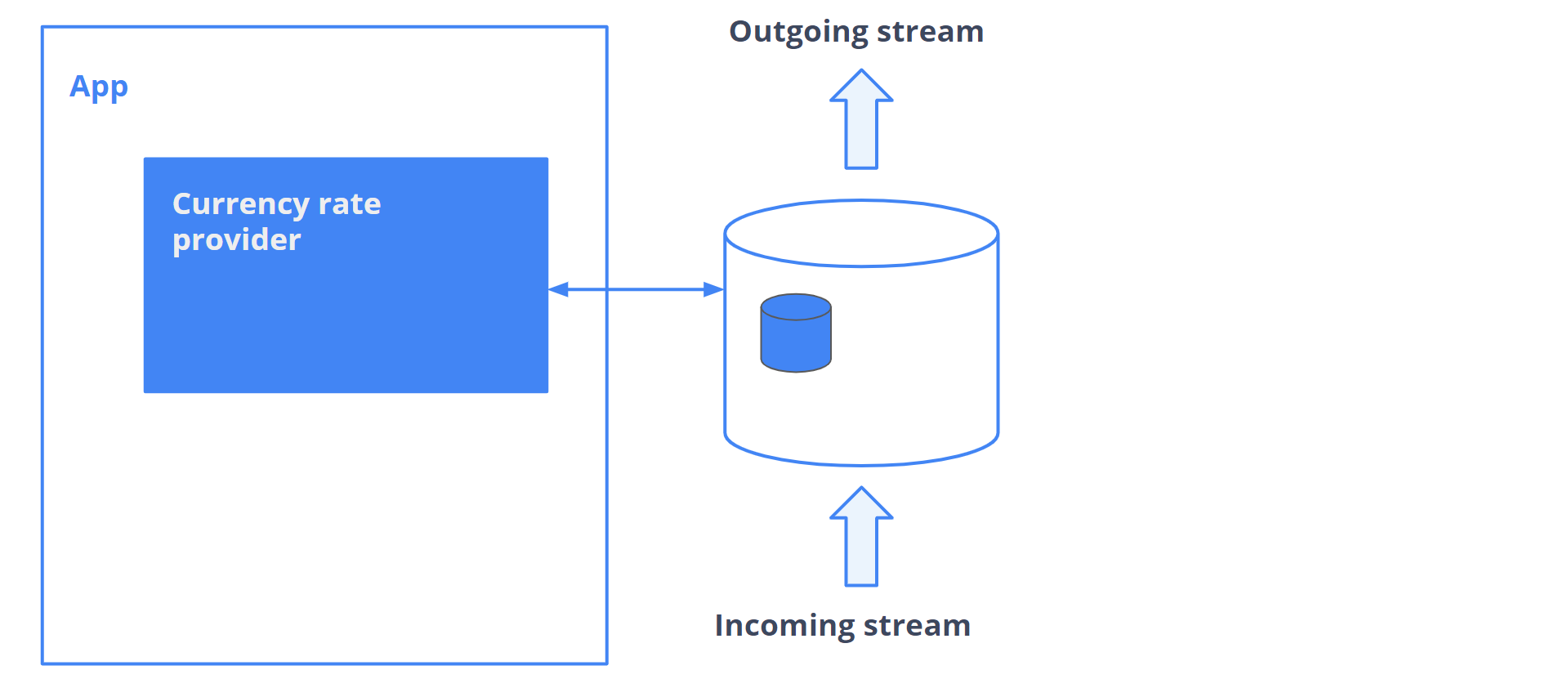
Нас не устраивает формат данных и то, каким образом эти данные попадают в базу. Но нужно исправлять это аккуратно, есть много зависимостей.
Чтобы это сделать, выделяем конкретный кусок — данные. Нужно их инкапсулировать. Для этого нужно ввести прослойки. Их задача — сделать так, чтобы потребитель и поставщик не заметили никаких изменений. В этом смысл инкапсуляции. Теперь мы можем менять структуру хранения, потому что это не повлияет на внешние зависимости. После можем построить новое решение, которое записывает данные в новом формате. И последним шагом можем перевести старые данные в новый формат и получить то, что мы хотели от нашего проекта: данные в новом формате, а старую логику можно убирать из приложения.
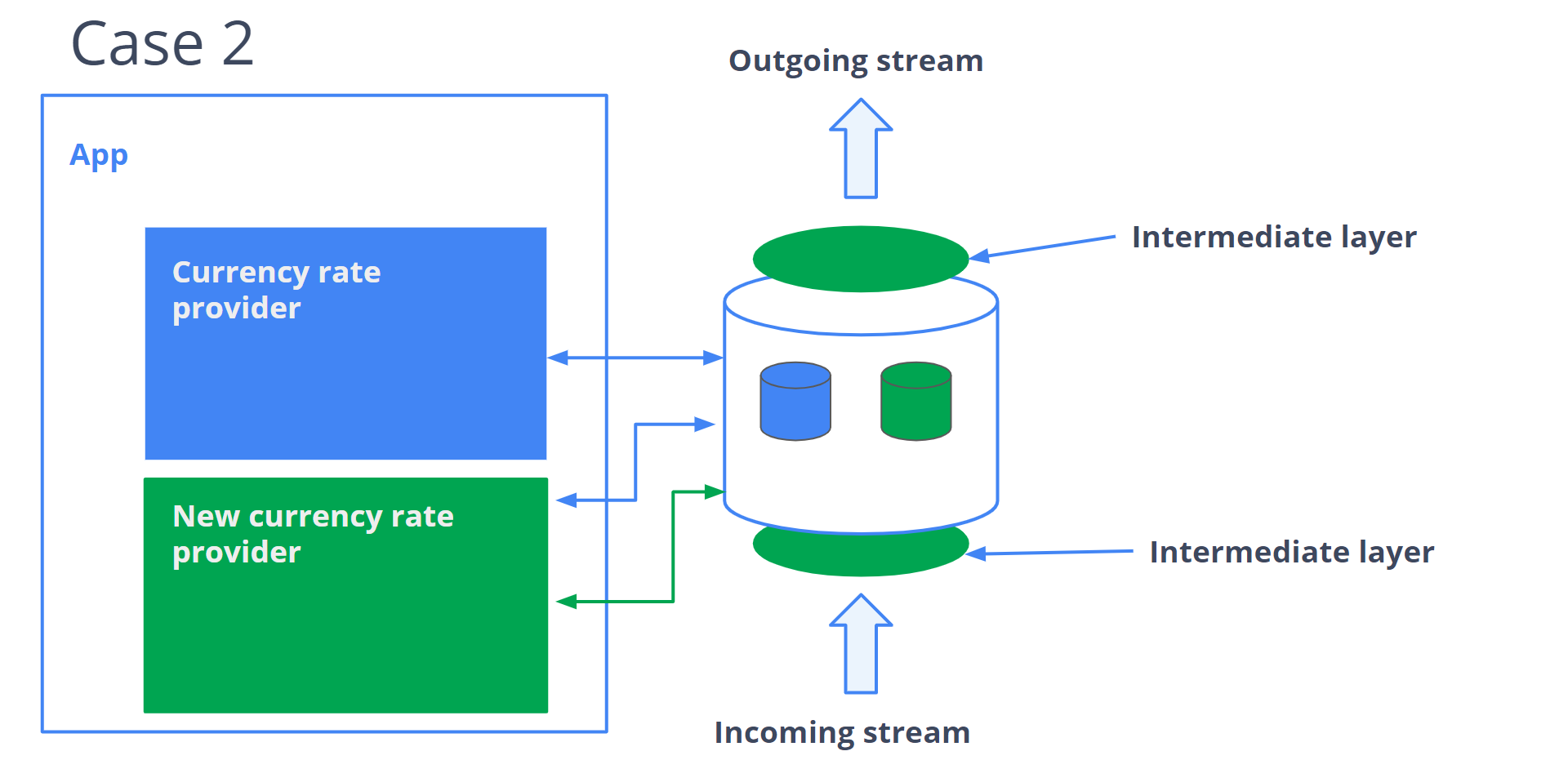
В этом процессе потребители данных не заметят изменений, а значит мы сделали это полностью безопасно, сохранив обратную совместимость. После, если это необходимо для проекта, можно работать с потребителем и с поставщиком данных, чтобы они тоже использовали новый формат.
Третий кейс
Чтобы увеличить масштаб и понять, как это работает в крупных проектах, представим, что есть большой проект, большая кодовая база и какая-то ключевая функциональность, которая прорастает абсолютно во все точки приложения. Ей пользуются другие куски Backend, у неё есть выход в Public API, то есть данные куда-то утекают. Фича используется во Frontend, во внешних системах и еще в довесок уходит напрямую из базы в аналитику. Чтобы пример был повеселее, добавим сюда щепотку легаси. Ну, капельку.

Два забавных факта о легаси:
- Оно точно работает.
- Никто не знает, как именно оно работает. На то оно и легаси.
При работе с таким кейсом, в котором есть много точек соприкосновения и много неизвестного, стоит понять: с чем, действительно, мы работаем, как выглядит это решение и какие у него возможности. Важно понимать, как решение, которое мы хотим переработать или от которого хотим избавиться, взаимодействует со всем остальным приложением. Нужно найти все точки соприкосновения: понимать, как они работают, понимать их контракты, чтобы иметь возможность предложить что-то другое.
Здесь есть несколько подходов, которые могут помочь, особенно если масштаб бедствия достаточно большой в объеме кода:
- Разметить код. В Java можно использовать аннотации с комментариями, чтобы разметить код, который показывает, как используется это решение. Потом на основе этих аннотаций можно строить автоматические отчеты, видеть, как картина выглядит, и понимать, что с ней делать;
- Нарисовать диаграммы. Любые диаграммы, которые показывают, как эти решения работают, как они взаимодействуют. Конкретная, сведенная и нарисованная вами диаграмма упростит понимание сложной системы, с которой вы работаете. Это будет полезно не только вам, но и всей команде;
- Поместить проект в таск-трекер.
Если мы нашли точки соприкосновения в коде, можно их использовать и обернуть решение точками инкапсуляции. Вводим новые контракты по взаимодействию приложения с нашей фичой.

Здесь убавилось количество легаси, потому что в этот самый момент мы уже начинаем вводить в приложение то, что мы хотим.
Дальше нужно сделать первый шаг на пути к новому решению — тесты. Они закроют тот самый забавный факт о легаси №2, который я упоминал ранее. Тесты покажут, как именно работает ваше решение. Кроме проверки ключевых флоу нужно убедиться в том, что оно еще и падает ровно там, где вы от него это ожидаете, и ровно так, как вы от него ожидаете.
Часто бывает, что решение, созданное однажды под бизнес-цели, использовалось на 100%, а сегодня пересекается с нынешними целями лишь на 30%, а на 70% — нет. В сегодняшних реалиях эти 70% уже не важны. Написанные вами тесты позволят выделить те самые 30%. Прогнав тест с покрытием, можно понять, какой код вообще не используется, удалить его и снизить связность и сложность вашего решения.
Если мы, написав тесты и поняв, как это работает, начнем вводить новое решение в инкапсулированной области, мы потихоньку вытесним все старое, что нам не нужно, уберем легаси и заменим решение на новое, подходящее под наши нужды.
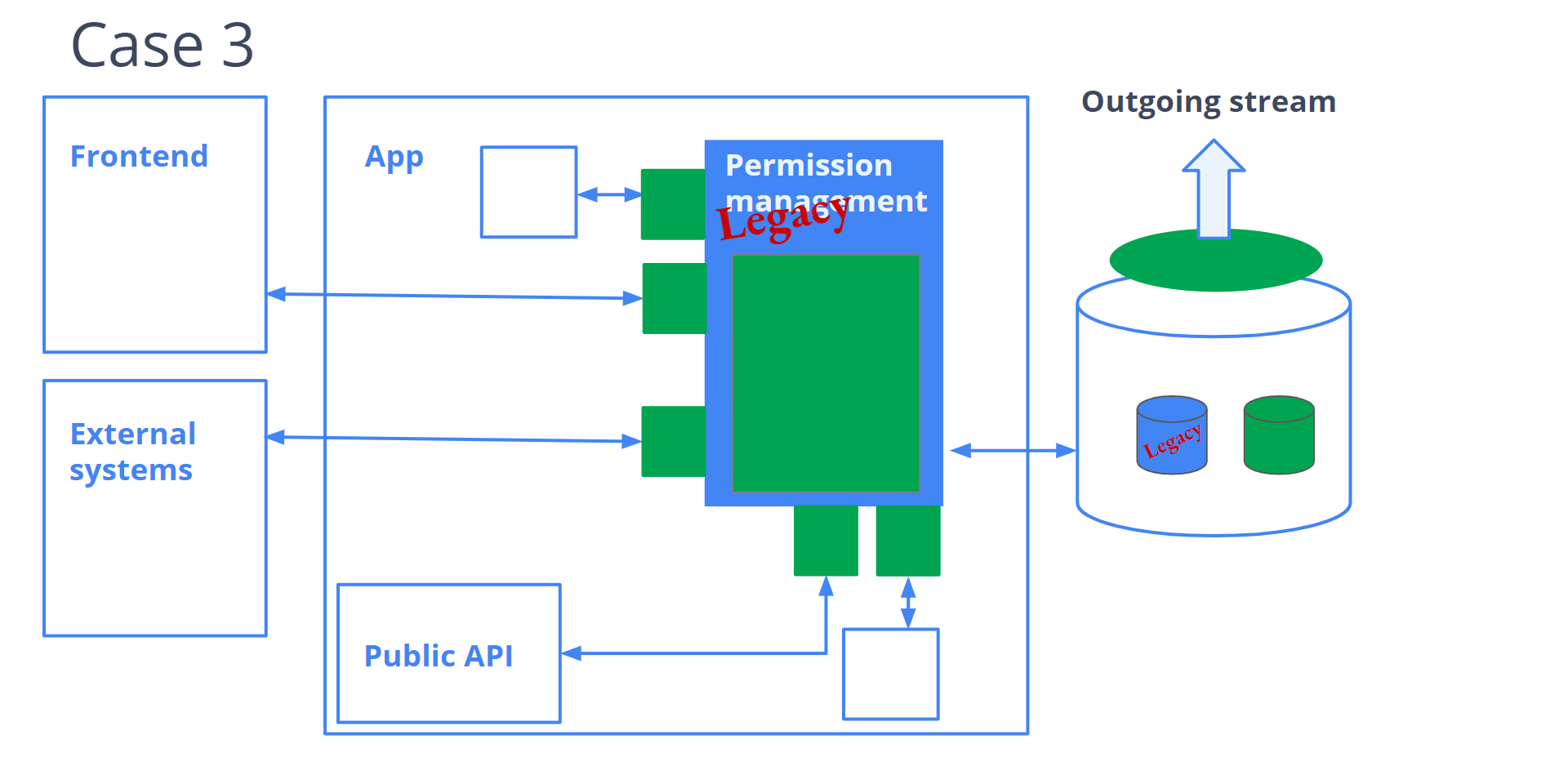
Новое решение должно быть простое, понятное и должно решать конкретно вашу проблему, конкретно сегодня и на конкретные ближайшие цели. Не нужно углубляться в оверинжиниринг, потому что мы закрываем конечную сегодняшнюю цель.
И это то самое место, где стоит остановиться, зависнуть в моменте и подумать: «А зачем мы это делаем?». На этом этапе у вас будет достаточно много информации о том, как решение работает, что в нем есть и чего нет. Вы написали тесты, разметили код, сделали диаграмму и понимаете теперь на порядок больше. Возможно, это та самая точка, где стоит остановиться и понять: можно ли решить гораздо большую проблему? И это то, что однажды спасло нашему проекту порядка квартала разработки, потому что мы выбрали правильное направление развития проекта.
Как организовать работу
Мы придерживаемся подхода, при котором стараемся разбивать новое решение на итерации. Это его конкретные части, которые можно выкатить в продакшн и которые что-то в нем изменят.
Чтобы понять, что такое итерация и какой набор задач в ней содержится, мы позаимствовали понятие Definition оf Done из Scrum. Это набор критериев, которые должны быть выполнены, чтобы история считалась выполненной.
Здесь же я использую это понятие немного в ином виде. Под Definition оf Done я понимаю описание того, что изменится в приложении, когда конкретная итерация пойдет в продакшн.
Давайте вспомним первый пример с системой order management. В нем пользователь мог создать новый заказ, используя новый UI и старый Backend. Это и есть вид итерации — конкретная часть функциональности, которую мы можем выкатить в продакшн, и она будет работать. Либо пользователь может авторизоваться с новой моделью прав доступа — это тоже качественное изменение. Так можно описать, что именно дает каждая итерация в вашем крестовом походе в борьбе с техническим долгом.
Когда вы разобьете решение на итерации, задач может быть много. Между ними будет зависимость, получится целый граф. В этом графе будет несколько путей достижения конечного результата. Можно использовать обратное планирование — инструмент, который поможет сократить время работы. Начинаем с финальной точки проекта и задаем вопрос: «Что необходимо сделать, чтобы достичь эту цель?». Понимаем, что для достижения этой цели нужно сделать предыдущий шаг. Так, двигаемся от конца к началу и на каждом промежуточном шаге отвечаем на этот вопрос, проходя критический путь. Когда-то такой подход сохранил нам квартал разработки.
Для визуализации работы хорошо подойдет инструмент, который называется Gantt chart. Это диаграмма, которая показывает зависимости между задачами, их длительность и то, как выглядит проект наглядно. На картинке скриншот из Wrike. У нас есть этот инструмент, мы его активно используем для работы с проектами.
Если вы работаете над обширным решением, вы можете столкнуться с ситуацией, когда кто-то меняет код, который вы рефакторите, адаптируете, ведете по своему процессу и который вы только что продумали. Эти изменения могут затруднять ваш путь в борьбе с техническим долгом.
От таких изменений можно защититься несколькими способами:
- Самый простой способ — доставлять всё в продакшн как можно быстрее. Тем самым, другой разработчик, которому нужно что-то изменить в вашем коде или воспользоваться вашим решением, будет работать с самой актуальной версией кода и сделает минимальное количество ошибок.
- Можно использовать автоматическую систему, которая будет мониторить все изменения. Можно использовать git hook, встроить проверку на момент git commit или git push. Можно написать unit test, который будет проверять, есть ли изменения в каких-то модулях или классах, и, если они есть, предупреждать: нужно сходить к коллеге и проконсультироваться или не делать их вообще.
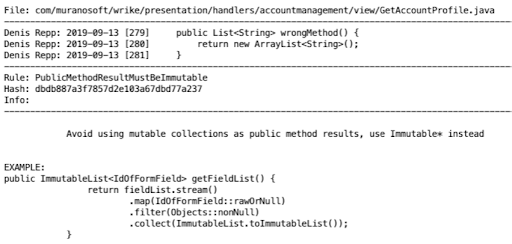
Можно также настроить внешнюю систему мониторинга на ваш код. В Wrike мы используем PMD. Система запускается и проверяет на соответствие определенным правилам каждую новую строчку кода. На картинке пример из build log. Здесь правило “public method results must be immutable” нарушилось, PMD об этом говорит и показывает, в какой строке — здесь это метод “wrong method”. Ниже подсказка, что нужно с ним сделать, чтобы исправить. Тем самым, мы всегда знаем, где нарушено правило и как это исправить.
Как пройти финального босса
Важная вещь, про которую мы не проговорили — это финальный босс, которого приходится проходить во время работы с техническим долгом. Бизнес, product owner, заказчик — у всех он называется по-разному. Он может мешать тащить наши инженерные инициативы вперед в продакшн.
Все мы знаем про случаи, когда product owner продавливал не самые оптимальные с инженерной точки зрения решения. Но даже если ваш product owner взглядом прогибает титановый лист, с ним все равно можно договориться. Работая с техническим долгом, вы открываете новые возможности, а они нужны product owner для развития своего продукта.
Можно договориться о квоте времени. Например, 10% времени разработчиков будут выделяться на работу над техническим долгом. Такая квота не позволит избавиться от технического долга, но позволит ему не раздуваться.
Очевидно, что трудно говорить про технический долг, если не понятно о чем конкретно идет разговор. Поэтому в вашей команде должен быть технический backlog, в котором есть оцененные и приоритизированные разрабочтиками задачи.
Однако, перечисленные выше инструменты не позволят разобраться с масштабными проектами. И в этом случае важно, оперируя тем, что было перечислено ранее (3 вопроса техдолгу, проект в трекере, критический путь в графе и т.д.), суметь объяснить выгоду от проекта вашему заказчику. И чем более проработанной будет история, тем больше понимания вы до него донесете. У бизнеса есть цели, которые вы помогаете ему достичь. Вам важно быть в курсе происходящего не только сейчас, но и планов, которые станут реальностью через кварталы. Поэтому общайтесь с бизнесом, понимайте, что он хочет сделать и какие есть пути достижения этих целей, и используйте это знание для объединения ваших инженерных целей и целей бизнеса.
Возможно, цели совпадут не сразу, а через квартал или даже через год. Но это позволит вам понять, когда бизнес будет готов к изменениям.
Если у вас получится синхронизировать цели, вы получите все бонусы: приоритизацию, ресурсы и организацию всей работы. Product owner поможет вам это сделать. Главная задача — договориться с ним.
Итог
Когда мы говорим про изменения в ключевых местах продукта, простой алгоритм из четырех шагов усложняется:
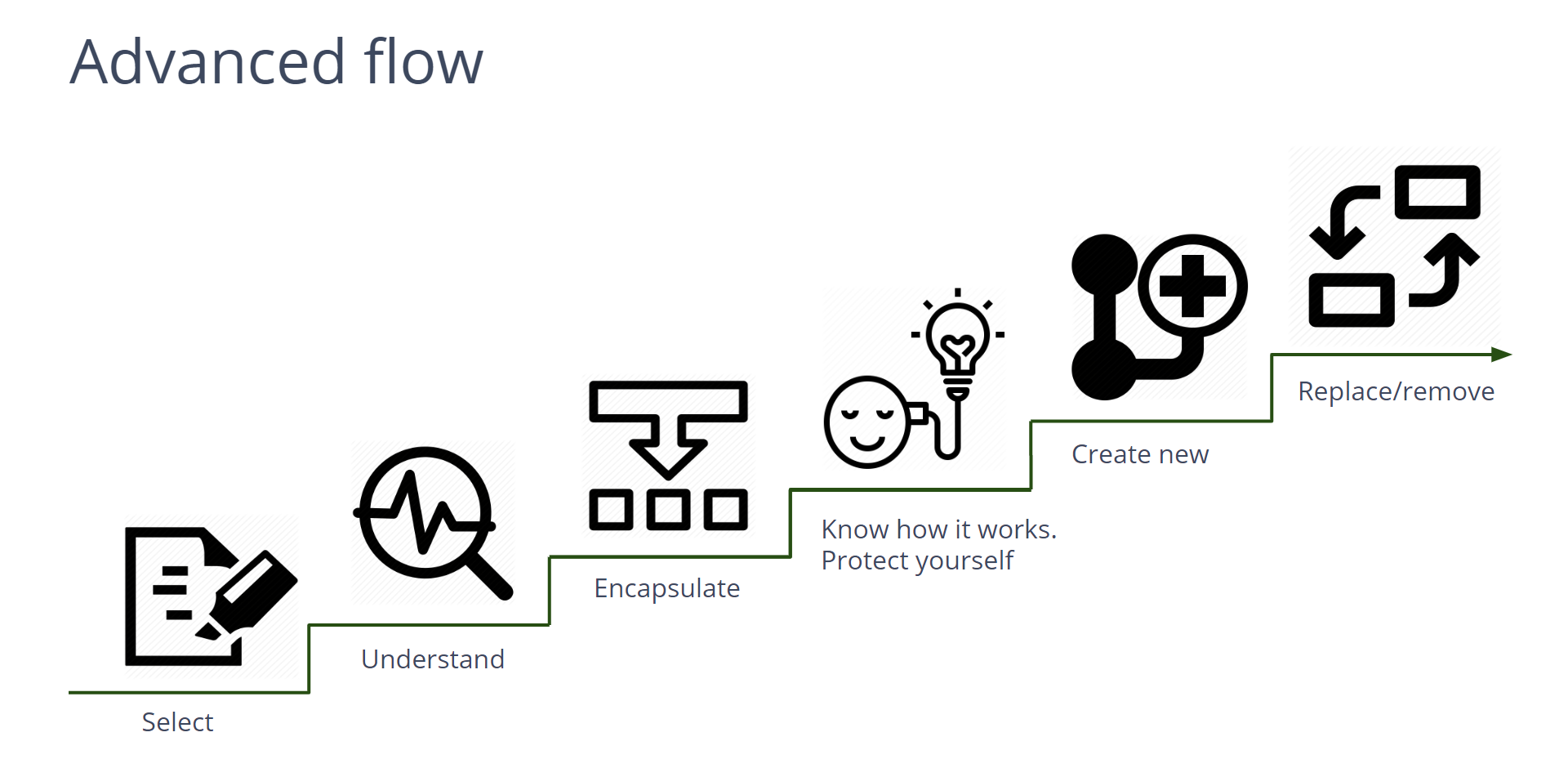
Добавляются еще два шага. Первый — понимание того, с чем мы работаем. Второй — после инкапсуляции — понимание того, как работает решение и как не допустить изменений в вашем коде.
Используя этот алгоритм и мои рекомендации по организации процесса, можно работать с любым техническим долгом.
Статья основана на моём выступлении на митапе, можете посмотреть видеозапись доклада.




