
Pandas не нуждается в представлении: на сегодняшний день это главный инструмент для анализа данных на Python. Я работаю специалистом по анализу данных, и несмотря на то, что пользуюсь pandas каждый день, не перестаю удивляться разнообразию функционала этой библиотеки. В этой статье я хочу рассказать о пяти малоизвестных функциях pandas, которые я недавно узнал и теперь продуктивно использую.
Для новичков: Pandas — это высокопроизводительный набор инструментов для анализа данных на Python с простыми и удобными структурами данных. Название произошло от понятия «panel data», эконометрического термина, которым называют данные о наблюдениях одних и тех же субъектов в течение разных периодов времени.
Здесь можно скачать Jupyter Notebook с примерами из статьи.
1. Диапазоны дат [Date Ranges]
Нередко нужно указывать диапазоны дат при запросе данных из внешнего API или базы данных. Pandas нас не бросит в беде. Как раз для этих случаев есть функция data_range, которая возвращает массив дат, увеличенных на дни, месяцы, года, и т.д.
Скажем, нам нужен диапазон дат по дням:
date_from = "2019-01-01"
date_to = "2019-01-12"
date_range = pd.date_range(date_from, date_to, freq="D")
date_range

Преобразуем сгенерированный
date_range в пары дат «от» и «до», которые можно будет передать в соответствующую функцию.for i, (date_from, date_to) in enumerate(zip(date_range[:-1], date_range[1:]), 1):
date_from = date_from.date().isoformat()
date_to = date_to.date().isoformat()
print("%d. date_from: %s, date_to: %s" % (i, date_from, date_to))
1. date_from: 2019-01-01, date_to: 2019-01-02
2. date_from: 2019-01-02, date_to: 2019-01-03
3. date_from: 2019-01-03, date_to: 2019-01-04
4. date_from: 2019-01-04, date_to: 2019-01-05
5. date_from: 2019-01-05, date_to: 2019-01-06
6. date_from: 2019-01-06, date_to: 2019-01-07
7. date_from: 2019-01-07, date_to: 2019-01-08
8. date_from: 2019-01-08, date_to: 2019-01-09
9. date_from: 2019-01-09, date_to: 2019-01-10
10. date_from: 2019-01-10, date_to: 2019-01-11
11. date_from: 2019-01-11, date_to: 2019-01-12
2. Слияние с индикатором источника [Merge with indicator]
Слияние двух наборов данных — это, как ни странно, процесс объединения двух наборов данных в один, строки которых сопоставляются на основании общих колонок или свойств.
Один из двух аргументов функции слияния, который я как-то упустил, —
indicator. «Индикатор» добавляет колонку _mergeв DataFrame, которая показывает, откуда взялась строка, из левого, правого, или обоих DataFrames. Колонка _merge может оказаться очень полезной при работе с большими наборами данных для проверки корректности слияния.left = pd.DataFrame({"key": ["key1", "key2", "key3", "key4"], "value_l": [1, 2, 3, 4]})
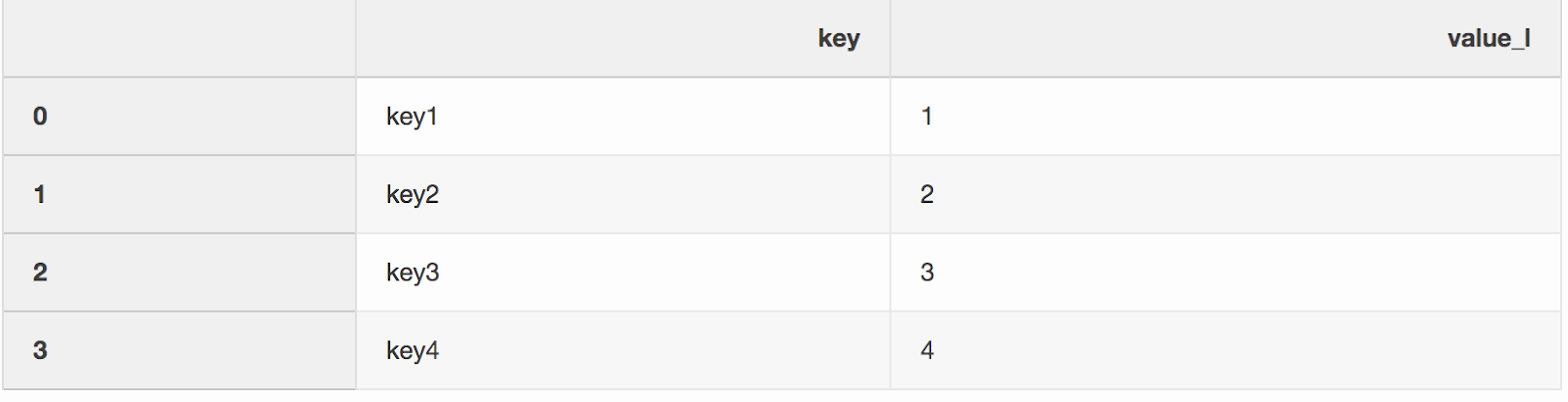
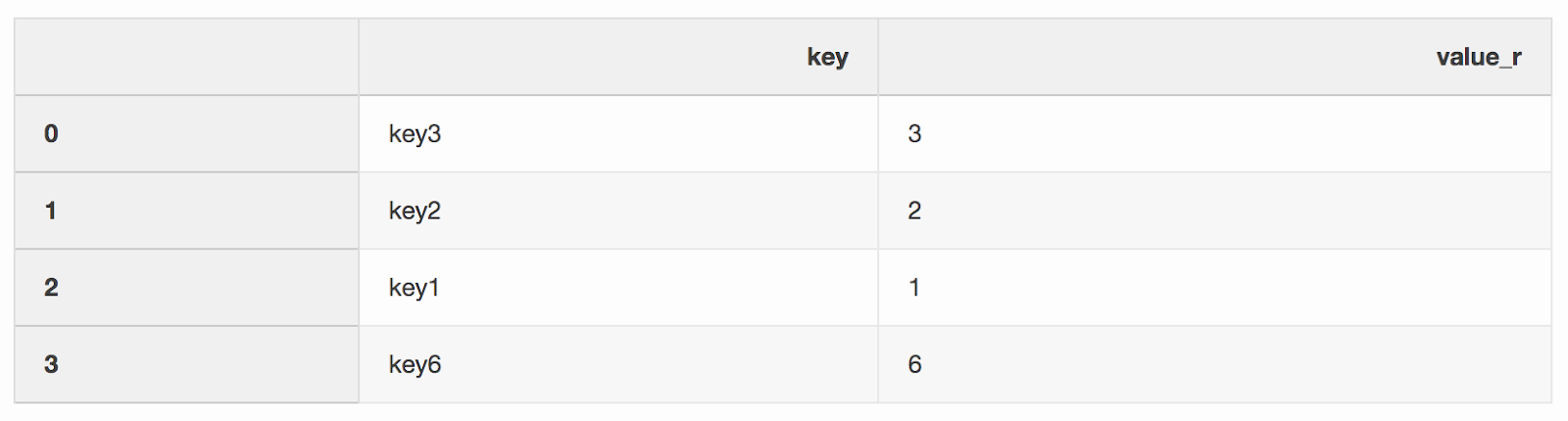
right = pd.DataFrame({"key": ["key3", "key2", "key1", "key6"], "value_r": [3, 2, 1, 6]})
df_merge = left.merge(right, on='key', how='left', indicator=True)
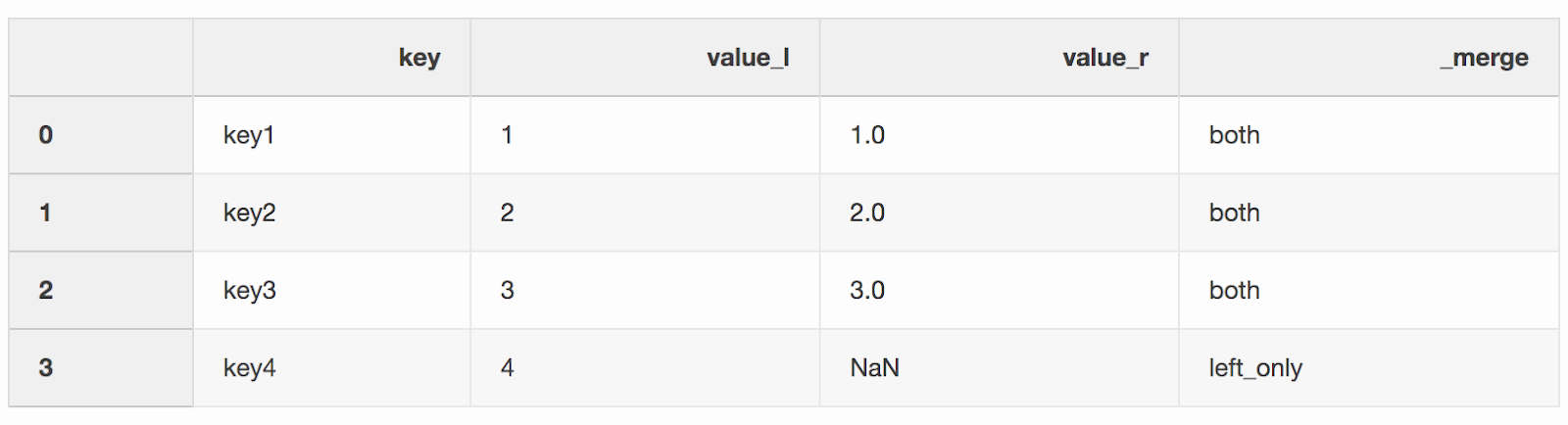
Колонку
_merge можно использовать, чтобы проверить, правильное ли количество строк с данными было взято из обоих DataFrames.df_merge._merge.value_counts()
both 3
left_only 1
right_only 0
Name: _merge, dtype: int64
3. Слияние по ближайшему значению [Nearest merge]
При работе с финансовыми данными, вроде криптовалют и ценных бумаг, бывает необходимо сопоставить котировки (изменения цен) со сделками. Скажем, мы хотим объединить каждую сделку с котировкой, которая обновилась за несколько миллисекунд до сделки. В pandas есть функция
merge_asof, благодаря которой можно объединять DataFrames по ближайшему значению ключа (timestamp в нашем случае). Наборы данных с котировками и сделками взяты из примера pandas.DataFrame
quotes («котировки») содержит изменения цен для разных акций. Как правило, котировок намного больше, чем сделок.quotes = pd.DataFrame(
[
["2016-05-25 13:30:00.023", "GOOG", 720.50, 720.93],
["2016-05-25 13:30:00.023", "MSFT", 51.95, 51.96],
["2016-05-25 13:30:00.030", "MSFT", 51.97, 51.98],
["2016-05-25 13:30:00.041", "MSFT", 51.99, 52.00],
["2016-05-25 13:30:00.048", "GOOG", 720.50, 720.93],
["2016-05-25 13:30:00.049", "AAPL", 97.99, 98.01],
["2016-05-25 13:30:00.072", "GOOG", 720.50, 720.88],
["2016-05-25 13:30:00.075", "MSFT", 52.01, 52.03],
],
columns=["timestamp", "ticker", "bid", "ask"],
)
quotes['timestamp'] = pd.to_datetime(quotes['timestamp'])
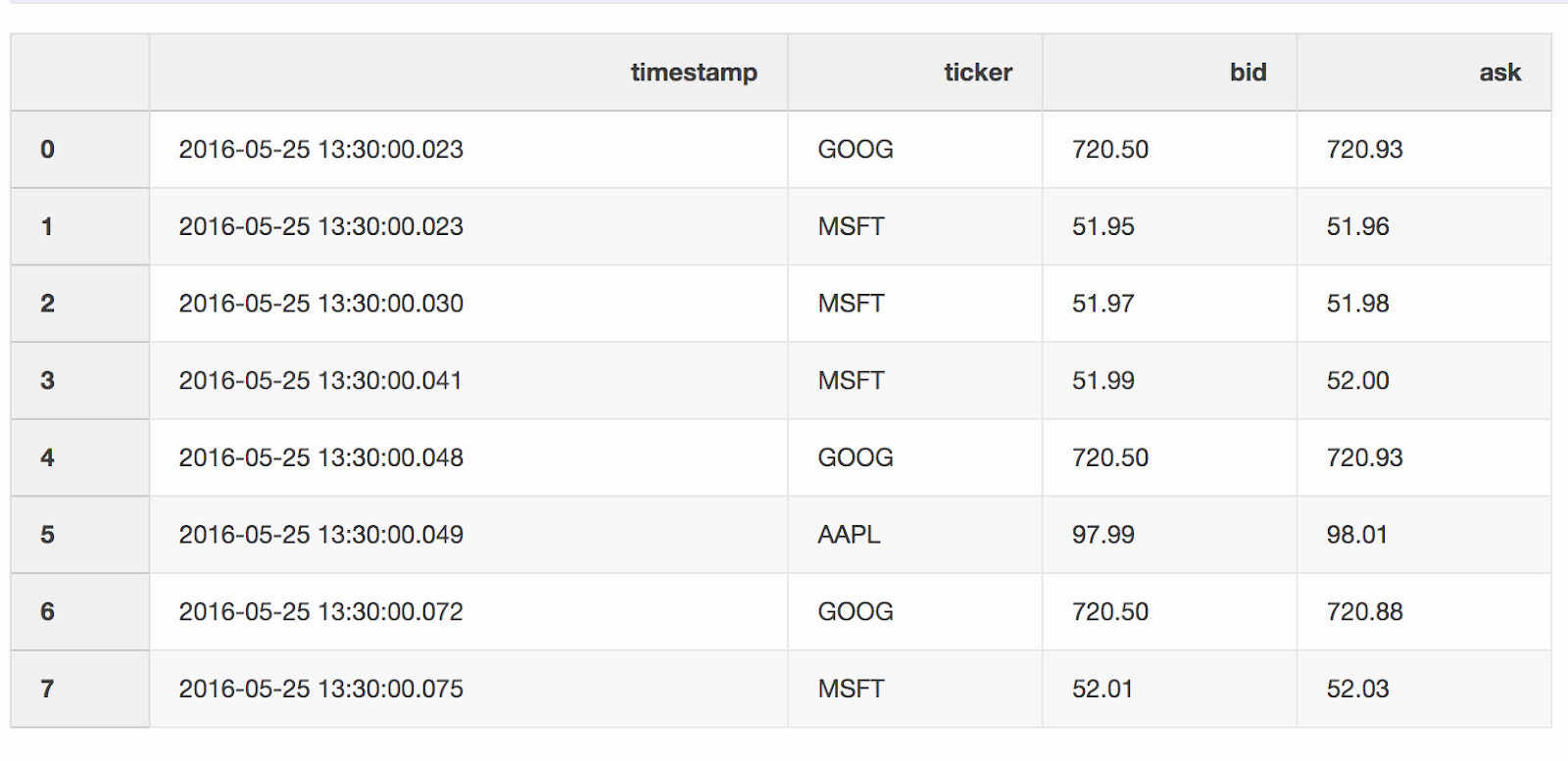
DataFrame
trades содержит сделки по разным акциям.trades = pd.DataFrame(
[
["2016-05-25 13:30:00.023", "MSFT", 51.95, 75],
["2016-05-25 13:30:00.038", "MSFT", 51.95, 155],
["2016-05-25 13:30:00.048", "GOOG", 720.77, 100],
["2016-05-25 13:30:00.048", "GOOG", 720.92, 100],
["2016-05-25 13:30:00.048", "AAPL", 98.00, 100],
],
columns=["timestamp", "ticker", "price", "quantity"],
)
trades['timestamp'] = pd.to_datetime(trades['timestamp'])
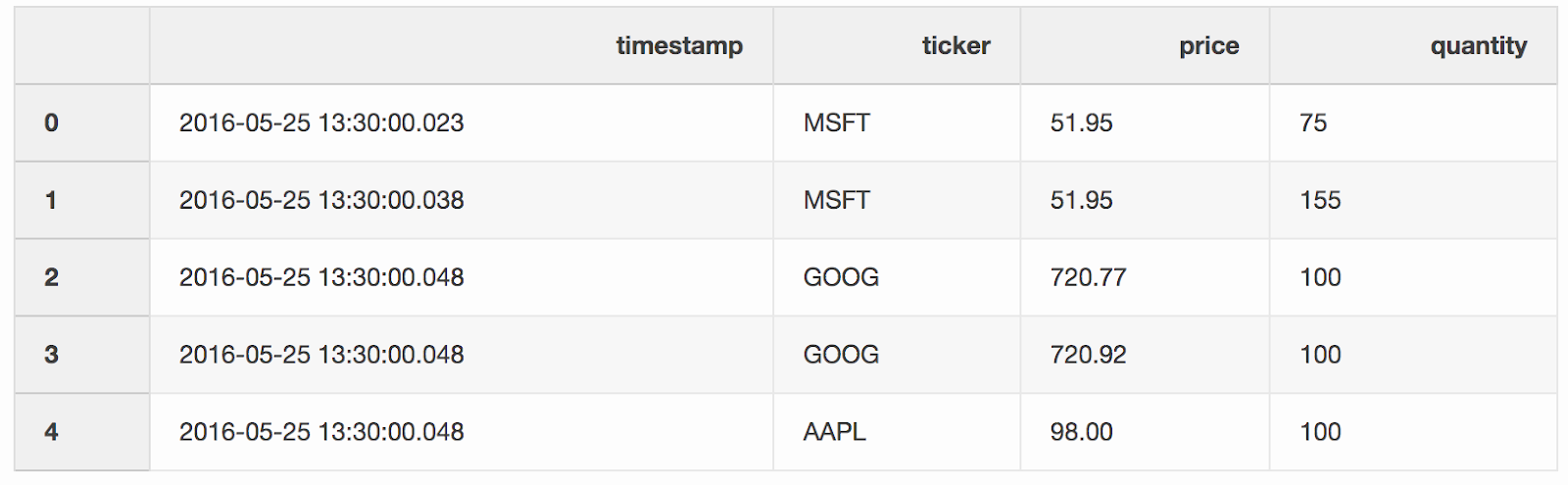
Мы сливаем сделки и котировки по тикерам (котируемый инструмент, например акции), с условием, что
timestamp последней котировки может быть на 10 мс меньше сделки. Если котировка появилась раньше сделки на более, чем 10 мс, бид (цена, которую готов заплатить покупатель) и аск (цена, по которой продавец готов продать) для этой котировки будут null (тикер AAPL в этом примере).pd.merge_asof(trades, quotes, on="timestamp", by='ticker', tolerance=pd.Timedelta('10ms'), direction='backward')

4. Создание Excel-отчёта
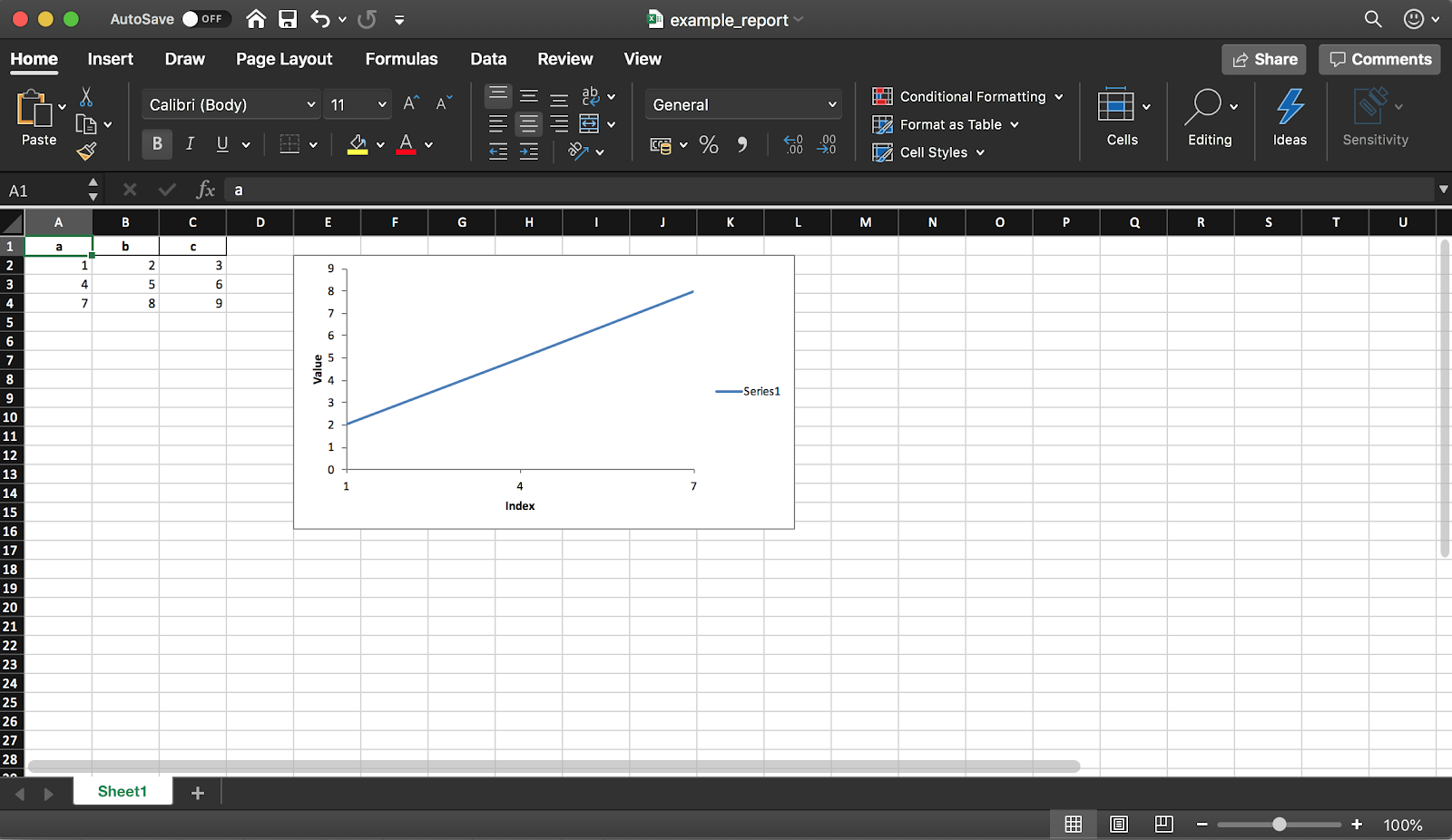
Pandas (c библиотекой XlsxWriter) позволяет создать Excel-отчёт из DataFrame. Так можно сэкономить кучу времени — никакого больше экспорта DataFrame в CSV и ручного форматирования в Excel. Доступны также все виды диаграмм и т.д.
df = pd.DataFrame(pd.np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=["a", "b", "c"])
Фрагмент кода ниже создаёт таблицу в формате Excel. Чтобы сохранить её в файл, раскомментируйте строку
writer.save().report_name = 'example_report.xlsx'
sheet_name = 'Sheet1'
writer = pd.ExcelWriter(report_name, engine='xlsxwriter')
df.to_excel(writer, sheet_name=sheet_name, index=False)
# writer.save()
Как уже упоминалось ранее, с помощью библиотеки также можно добавлять диаграммы в отчёт. Нужно задать тип диаграммы (линейная в нашем примере) и диапазон данных для неё (диапазон данных должен быть в Excel-таблице).
# определяем книгу (workbook)
workbook = writer.book
worksheet = writer.sheets[sheet_name]
# создаём линейную диаграмму
chart = workbook.add_chart({'type': 'line'})
# настраиваем диапазон данных из таблицы для диаграммы,
# используя список значений вместо формул категория/значение:
# [sheetname, first_row, first_col, last_row, last_col]
chart.add_series({
'categories': [sheet_name, 1, 0, 3, 0],
'values': [sheet_name, 1, 1, 3, 1],
})
# настраиваем оси диаграммы
chart.set_x_axis({'name': 'Index', 'position_axis': 'on_tick'})
chart.set_y_axis({'name': 'Value', 'major_gridlines': {'visible': False}})
# размещаем диаграмму на листе
worksheet.insert_chart('E2', chart)
# сохраняем файл
writer.save()
5. Экономия места на диске
Работа над большим количеством проектов по анализу данных обычно оставляет след в виде большого количества обработанных данных из разных экспериментов. SSD на ноутбуке заполняется довольно быстро. Pandas позволяет сжимать данные при сохранении данных на диск и потом снова читать их уже из сжатого формата.
Создадим большой DataFrame со случайными числами.
df = pd.DataFrame(pd.np.random.randn(50000,300))
Если сохранить его как CSV, файл займет почти 300 МБ на жёстком диске.
df.to_csv('random_data.csv', index=False)
Один аргумент
compression='gzip' уменьшает размер файла до 136 МБ.df.to_csv('random_data.gz', compression='gzip', index=False)
Сжатый файл читается тем же способом, что и обычный, так что никакой функциональности мы не теряем.
df = pd.read_csv('random_data.gz')
Заключение
Эти небольшие хитрости повысили продуктивность моей ежедневной работы с pandas. Надеюсь, из этой статьи вы узнали о какой-нибудь полезной функции, которая вам тоже поможет стать более продуктивным.
А какой ваш любимый приём в работе с pandas?

 с CRM Битрикс24")



