

В последнее время Prometheus стал де-факто стандартом для сбора и хранения метрик. Он удобен для разработчиков ПО - экспорт метрик можно реализовать в несколько строк кода. Для DevOps/SRE, в свою очередь, есть простой язык PromQL для получения метрик из хранилища и их визуализации в той же Grafana.
Но Prometheus имеет ряд недостатков, способы устранения которых я хочу рассмотреть в этой статье. Также разберём деплой Cortex - распределённого хранилища метрик.
Недостатки
Отсутствие отказоустойчивости
Prometheus работает только в единственном экземпляре, никакого HA.
Отсутствие распределения нагрузки
В принципе, он хорошо скейлится вверх с ростом количества ядер. Так что это проблема только для тех у кого действительно много метрик.
Нет поддержки multi-tenancy
Все метрики летят в один большой котёл и разгребать их потом используя PromQL и метки не всегда удобно. Часто хочется разделить различные приложения и\или команды по своим песочницам чтобы они друг другу не мешали.
Плюс, многие готовые дашборды для Grafana не готовы к тому что много инстансов одного приложения хранят метрики в одном и том же месте - придётся переделывать все запросы, добавлять фильтры по меткам и так далее.
В принципе, все эти проблемы можно решить настроив несколько HA-пар Prometheus и распределив по ним свои приложения. Если перед каждой парой повесить прокси, то можно получить что-то вроде отказоустойчивости.
Но есть и минусы:
После того как один хост из пары упадёт/перезагрузится/whatever - у них случится рассинхронизация. В метриках будут пропуски.
Все метрики приложения должны умещаться на один хост
Управлять таким зоопарком будет сложнее - какие-то из Prometheus могут быть недогружены, какие-то перегружены. В случае запуска в каком-нибудь Kubernetes это не так важно.
Давайте рассмотрим какими ещё способами можно решить это.
PromQL прокси
Например promxy, который размещается перед 2 или более инстансами Prometheus и делает fan-out входящих запросов на все из них. Затем дедуплицирует полученные метрики и, таким образом, закрывает пропуски в метриках (если, конечно, они не попали на один и тот же временной интервал).
Минусы подобного решения на поверхности:
Один запрос нагружает сразу все инстансы за прокси
Прокси решает только проблему с пропусками в метриках.
Но для тех, у кого нагрузка укладывается в возможности одного Prometheus (либо ее можно грамотно раскидать по нескольким HA-парам) и кому не нужен multi-tenancy - это очень хороший вариант.
Thanos

Thanos - это уже более продвинутое решение.

Он устанавливает рядом с каждым инстансом Prometheus так называемый Sidecar - отдельный демон, который подглядывает за блоками данных, которые генерирует Prometheus. Как только блок закрывается - Sidecar загружает его в объектное хранилище (S3/GCS/Azure). Длина блоков в Prometheus прибита гвоздями и равна 2 часам.
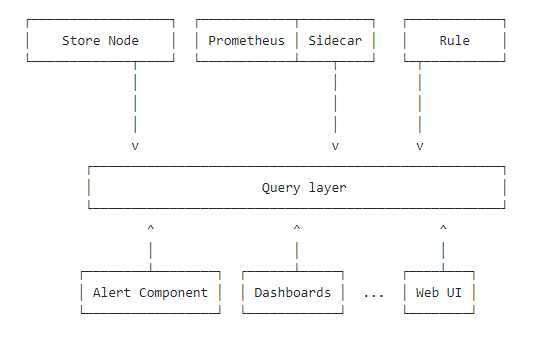
Также он является прокси между GRPC Thanos StoreAPI и Prometheus для получения метрик, которые еще не были загружены в объектное хранилище.
Отдельный компонент Querier реализует PromQL: в зависимости от временного интервала запроса и настроек глубины хранения данных в Prometheus он может направить его в объектное хранилище, в Sidecar или в разбить на два подзапроса - для свежих данных запрос пойдёт через Sidecar в Prometheus, а для более старых - в объектное хранилище.
Отказоустойчивость свежих данных в Thanos реализуется примерно так же как и в promxy - делается fan-out запросов на все причастные сервера, результаты накладываются друг на друга и дедуплицируются. Задача по защите исторических данных лежит на объектном хранилище.
Multi-tenancy есть в некотором зачаточном состоянии, но в эту сторону проект, судя по всему, не развивается особо.
Cortex
Это наиболее сложный и функциональный проект. Его начали разрабатывать в Grafana Labs для своего SaaS решения по хранению метрик и несколько лет назад выложили в open source, с тех пор разработка идёт на гитхабе.
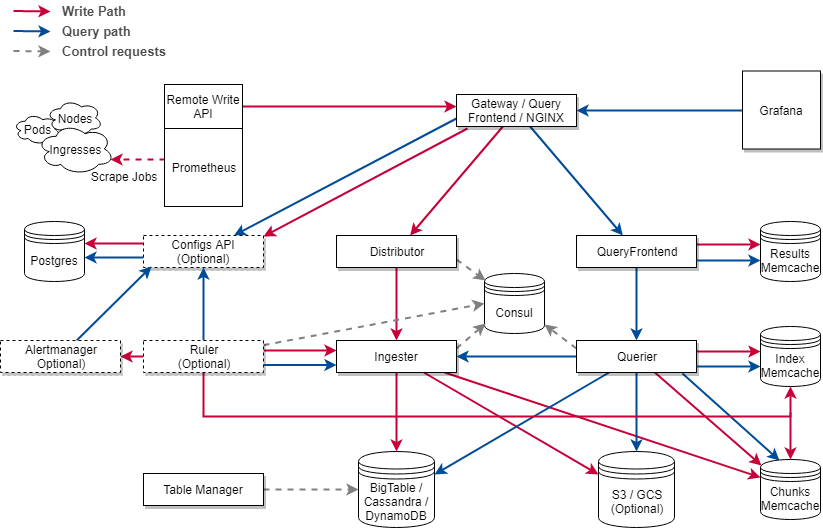
Как можно видеть на диаграмме выше - в нём очень много компонентов. Но бояться не стоит - большую часть из них можно не использовать, либо запускать в рамках одного процесса - single binary mode.
Так как Cortex изначально разрабатывался как SaaS решение - в нём поддерживается end-to-end multi-tenancy.
Хранение метрик
На данный момент в Cortex есть два движка. Оба они хранят данные в объектном хранилище, среди которых поддерживаются:
S3
GCS
Azure
OpenStack Swift (экспериментально)
Любая примонтированная ФС (например - NFS или GlusterFS). Хранить блоки на локальной ФС смысла нет т.к. они должны быть доступны всему кластеру.
Далее я буду для краткости называть объектное хранилище просто S3.
Chunks Storage
Изначальный движок в Cortex - он хранит каждую timeseries в отдельном чанке в S3 или в NoSQL (Cassandra/Amazon DynamoDB/Google BigTable), а метаданные (индексы) хранятся в NoSQL.
Chunks Storage, думается, со временем совсем выпилят - насколько я слышал, Grafana Labs свои метрики уже мигрировали в Blocks Storage.
Blocks Storage
Новый, более простой и быстрый движок, основанный на Thanos. Который, в свою очередь, использует формат блоков самого Prometheus. С ним нет нужды в NoSQL и модуле Table Manager (но нужен другой - Store Gateway).
Thanos, в данном, случае является внешней vendored зависимостью в коде Cortex. Есть разговоры о том, чтобы объединить два проекта в один, но когда это будет неизвестно (и будет ли вообще).
Архитектура
Далее я буду рассматривать работу с Blocks Storage.
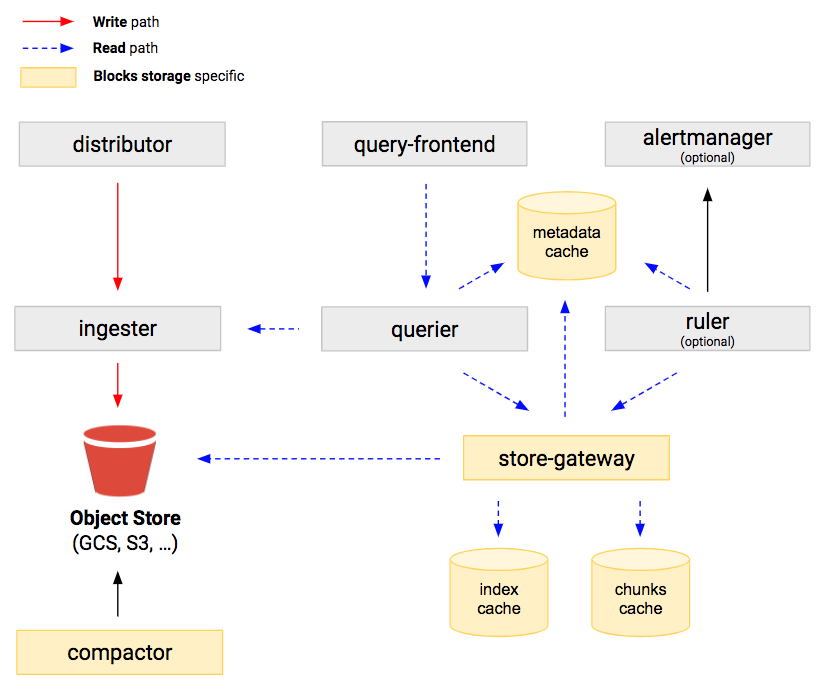
Упрощённо принцип работы следующий:
Prometheus собирает метрики с endpoint-ов и периодически отправляет их в Cortex используя Remote Write протокол. По сути это HTTP POST с телом в виде сериализованных в Protocol Buffers метрик сжатый потом Snappy. В самом Prometheus, при этом, можно поставить минимальный retention period - например 1 день или меньше- читаться из него ничего не будет.
Модуль Distributor внутри Cortex принимает, валидирует, проверяет per-tenant и глобальные лимиты и опционально шардит пришедшие метрики. Далее он передает их одному или нескольким Ingester (в зависимости от того применяется ли шардинг).
Также в рамках этого модуля работает HA Tracker (о нём ниже).
Ingester ответственен за запись метрик в долговременное хранилище и выдачу их для выполнения запросов. Изначально метрики записываются в локальную ФС в виде блоков длиной 2 часа. Затем, по истечении некоторого времени, они загружаются в S3 и удаляются с локальной ФС.
Также поддерживается репликация и zone awareness для дублирования блоков по различным availability domain (стойки, ДЦ, AWS AZ и так далее)
Store-Gateway служит для отдачи блоков из S3.
Он периодически сканирует бакет, находит там новые блоки, синхронизирует их заголовки в локальную ФС (чтобы после перезапуска не скачивать опять) и индексирует.
Querier реализует PromQL.
При получении запроса анализирует его и, если необходимо, разбивает на два - одна часть пойдёт в Store Gateway (для более старых данных), а другая - в Ingester для свежих.
По факту параллельных запросов может быть больше если запрашиваемый период большой и настроено разбиение по интервалам (об этом дальше в конфиге)
Compactor периодически просыпается и сканирует объектное хранилище на предмет блоков, которые можно склеить в более крупные. Это приводит к более эффективному хранению и быстрым запросам.
Старые блоки не удаляются сразу, а маркируются и удаляются на следующих итерациях чтобы дать время Store-Gateway обнаружить новые, которые уже сжаты.
Отказоустойчивость
Помимо репликации данных между Ingester-ами нам необходимо обеспечить отказоустойчивость самих Prometheus. В Cortex это реализовано просто и элегантно:
Два (или более) Prometheus настраиваются на сбор метрик с одних и тех же endpoint-ов
В каждом из них настраиваются специальные внешние метки, которые показывают к какой HA-группе принадлежит данный Prometheus и какой у него идентификатор внутри группы.
Например так:
external_labels:
__ha_group__: group_1
__ha_replica__: replica_2При приёме метрик Cortex из каждой группы выбирает один Prometheus и сохраняет метрики только от него
Остальным отвечает HTTP 202 Accepted и отправляет в /dev/null всё что они прислали
Если же активный инстанс перестал присылать метрики (сработал таймаут) - Cortex переключается на приём от кого-то из оставшихся в живых.
Таким образом дедупликация на этом уровне становится не нужна. Правда остаётся вопрос момента переключения - не теряется ли там что-либо (когда старый не прислал, а от нового ещё не приняли), я этот вопрос не изучал глубоко - нужно тестировать.
Авторизация
Каждый запрос на запись метрик из Prometheus должен содержать HTTP-заголовок X-Scope-OrgId равный идентификатору клиента (далее я буду называть их просто tenant, хорошего перевода не придумал). Метрики каждого tenant-а полностью изолированны друг от друга - они хранятся в разных директориях в S3 бакете и на локальной ФС
Таким же образом происходит и чтение метрик - в PromQL запросах тоже нужно тоже указывать этот заголовок.
При этом никакой реальной авторизации Cortex не проводит - он слепо доверяет этому заголовку. Auth Gateway есть в роадмапе, но когда он будет готов неизвестно. Даже просто добавить этот заголовок напрямую в Prometheus нельзя, только используя промежуточный HTTP прокси.
Для более гибкой интеграции Prometheus & Cortex я набросал простенький Remote Write прокси - cortex-tenant, который может вытаскивать ID клиента из меток Prometheus. Это позволяет использовать один инстанс (или HA-группу) Prometheus для отправки метрик нескольким разным клиентам. Мы используем этот функционал для разграничения данных разных команд, приложений и сред.
Авторизацию можно отключить, тогда Cortex не будет проверять наличие заголовка в запросах и будет подразумевать что он всегда равен fake - то есть multi-tenancy будет отключен, все метрики будут падать в один котёл.
При необходимости данные одного клиента можно полностью удалить из кластера - пока это API экспериментально, но работает.
Настройка Cortex
В первую очередь хотелось бы сказать, что Cortex имеет смысл для тех, у кого действительно много метрик, либо хочется хранить централизовано.
Для всех остальных гораздо проще установить несколько HA-пар Prometheus (например на каждую команду или каждый проект) и поверх них натянуть
promxy
Так как документация имеет некоторое количество белых пятен - я хочу рассмотреть настройку простого кластера Cortex в режиме single binary - все модули у нас будут работать в рамках одного и того же процесса.
Danger Zone! Дальше много конфигов!
Зависимости
Нам понадобится ряд внешних сервисов для работы.
etcd для согласования кластера и хранения Hash Ring
Cortex также поддерживает Consul и Gossip-протокол, которому не нужно внешнее KV-хранилище. Но для HA-трекера Gossip не поддерживается из-за больших задержек при сходимости. Так что будем юзать etcd
memcached для кеширования всего и вся.
Cortex поддерживает его в нескольких своих модулях. Можно поднять несколько инстансов и указать их все в Cortex - он будет шардить по всем равномерно. В принципе, он не обязателен, но крайне рекомендован с точки зрения производительности.
Также есть DNS-based discovery через SRV-записи, если не хочется указывать вручную.
minio для реализации распределённого S3 хранилища.
Несколько странный проект, который часто в процессе разработки ломает обратную совместимость и требует полного перезапуска кластера для апгрейда. Также SemVer это для слабаков, поэтому у них версионирование по датам. Его разрабатывают, в основном, индусы - возможно в этом причина...
Но других вариантов особо нет, можно поднять Ceph с S3 шлюзом, но это еще более громоздко.
minio поддерживает Erasure Coding для отказоустойчивости, что есть хорошо.
HAProxy для связывания компонентов воедино
cortex-tenant для распределения метрик по tenant-ам
Prometheus собственно для сбора метрик
Общие вводные
Кластер мы будем строить плоский из 4 хостов - все они будут идентичны, с одинаковым набором сервисов. Это хорошо для небольших инсталляций, упрощает структуру.
3 страйпа не поддерживает minio c Erasure Coding - он нарезает от 4 до 16 дисков в один EC-набор. В реальном проекте лучше использовать 5 или какое-либо большее нечетное число чтобы не было Split Brain.
Также, если у вас много хостов, то некоторые компоненты, такие как etcd, лучше вынести отдельно. etcd основан на Raft и реплицирует данные на все ноды кластера, смысла в их большом количестве нет - это только увеличит среднюю нагрузку лишними репликами.
Все данные будем хранить в
/dataКонфиги я буду приводить для одного хоста, для остальных обычно достаточно поменять адреса и\или хостнеймы
В качестве ОС используем RHEL7, но различия с другими дистрибутивами минимальны
У нас всё это дело, конечно, раскатывается через Ansible, но плейбук довольно сильно завязан на нашу инфраструктуру. Я постараюсь потом его подчистить и выложить
Некоторые RPM пакеты я собираю вручную (etcd, HAProxy и т.п.) с помощью FPM т.к. в репозиториях древние версии.
/etc/hosts
10.0.0.1 ctx1
10.0.0.2 ctx2
10.0.0.3 ctx3
10.0.0.4 ctx4etcd
Как и Zookeeper, с настройками по умолчанию etcd - бомба замедленного действия. Он не удаляет ненужные снапшоты и разрастается до бесконечности. Зачем так сделано - мне не понятно.
Поэтому настроим его соответственно:
/etc/etcd/etcd.conf
ETCD_NAME="ctx1"
ETCD_LOGGER="zap"
ETCD_LOG_LEVEL="warn"
ETCD_DATA_DIR="/data/etcd/ctx1.etcd"
ETCD_LISTEN_CLIENT_URLS="http://10.0.0.1:2379,http://127.0.0.1:2379"
ETCD_LISTEN_PEER_URLS="http://10.0.0.1:2380"
ETCD_ADVERTISE_CLIENT_URLS="http://10.0.0.1:2379"
ETCD_INITIAL_CLUSTER_TOKEN="cortex"
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://10.0.0.1:2380"
ETCD_AUTO_COMPACTION_RETENTION="30m"
ETCD_AUTO_COMPACTION_MODE="periodic"
ETCD_SNAPSHOT_COUNT="10000"
ETCD_MAX_SNAPSHOTS="5"
ETCD_INITIAL_CLUSTER="ctx1=http://ctx1:2380,ctx2=http://ctx2:2380,ctx3=http://ctx3:2380,ctx4=http://ctx4:2380"memcached
Тут всё просто, главное выделить нужное количество памяти. Она зависит от количества метрик, которые мы будем хранить. Чем больше уникальных комбинаций меток - тем больше нужно кеша.
/etc/sysconfig/memcached
PORT="11211"
USER="memcached"
MAXCONN="512"
CACHESIZE="2048"
OPTIONS="--lock-memory --threads=8 --max-item-size=64m"Minio
Тут минимум настроек.
По сути мы просто перечисляем хосты, которые будут использоваться для хранения данных (+ путь до директории где данные хранить - /data/minio) и указываем ключи S3. В моем случае это были ВМ с одним диском, если у вас их несколько - то формат URL несколько меняется.
По умолчанию используется странное распределение дисков под данные и под коды Рида-Соломона: половина сырого объема уходит под redundancy. Так как у нас всего 4 хоста - это не особо важно. Но на большем по размеру кластере лучше использовать Storage Classes для снижения доли Parity-дисков.
/etc/minio/minio.env
MINIO_ACCESS_KEY="foo"
MINIO_SECRET_KEY="bar"
MINIO_PROMETHEUS_AUTH_TYPE="public"
LISTEN="0.0.0.0:9000"
ARGS="http://ctx{1...4}/data/minio"Также нужно будет создать бакет с помощью minio-client - в нашем случае пусть называется cortex
HAProxy
Он у нас будет служить для равномерного распределения нагрузки по кластеру и отказоустойчивости. Все сервисы обращаются к локальному HAProxy, который в свою очередь проксирует запросы куда нужно.
Таким образом мы имеем что-то вроде Full Mesh топологии и отказ или перезапуск любого из сервисов или хостов целиком не влияет на функциональность кластера.
На больших кластерах (сотни-тысячи хостов) такая схема может быть узким местом, но если вы работаете с такими, то и сами это знаете :)
/etc/haproxy/haproxy.cfg
global
daemon
maxconn 10000
log 127.0.0.1 local2
chroot /var/empty
defaults
mode http
http-reuse safe
hash-type map-based sdbm avalanche
balance roundrobin
retries 3
retry-on all-retryable-errors
timeout connect 2s
timeout client 300s
timeout server 300s
timeout http-request 300s
option splice-auto
option dontlog-normal
option dontlognull
option forwardfor
option http-ignore-probes
option http-keep-alive
option redispatch 1
option srvtcpka
option tcp-smart-accept
option tcp-smart-connect
option allbackups
listen stats
bind 0.0.0.0:6666
http-request use-service prometheus-exporter if { path /metrics }
stats enable
stats refresh 30s
stats show-node
stats uri /
frontend fe_cortex
bind 0.0.0.0:8090 tfo
default_backend be_cortex
frontend fe_cortex_tenant
bind 0.0.0.0:8009 tfo
default_backend be_cortex_tenant
frontend fe_minio
bind 0.0.0.0:9001 tfo
default_backend be_minio
backend be_cortex
option httpchk GET /ready
http-check expect rstring ^ready
server ctx1 10.0.0.1:9009 check observe layer7 inter 5s
server ctx2 10.0.0.2:9009 check observe layer7 inter 5s
server ctx3 10.0.0.3:9009 check observe layer7 inter 5s
server ctx4 10.0.0.4:9009 check observe layer7 inter 5s
backend be_cortex_tenant
option httpchk GET /alive
http-check expect status 200
server ctx1 10.0.0.1:8008 check observe layer7 inter 5s
server ctx2 10.0.0.2:8008 check observe layer7 inter 5s backup
server ctx3 10.0.0.3:8008 check observe layer7 inter 5s backup
server ctx4 10.0.0.4:8008 check observe layer7 inter 5s backup
backend be_minio
balance leastconn
option httpchk GET /minio/health/live
http-check expect status 200
server ctx1 10.0.0.1:9000 check observe layer7 inter 5s
server ctx2 10.0.0.2:9000 check observe layer7 inter 5s backup
server ctx3 10.0.0.3:9000 check observe layer7 inter 5s backup
server ctx4 10.0.0.4:9000 check observe layer7 inter 5s backupcortex-tenant
Это просто прокси между Prometheus и Cortex. Главное - выбрать уникальное имя метки для хранения там tenant ID. В нашем случае это ctx_tenant
/etc/cortex-tenant.yml
listen: 0.0.0.0:8008
target: http://127.0.0.1:8090/api/v1/push
log_level: warn
timeout: 10s
timeout_shutdown: 10s
tenant:
label: ctx_tenant
label_remove: true
header: X-Scope-OrgIDPrometheus
В случае 4 хостов Prometheus-ы можно разбить их на две HA-пары, каждую со своим ID группы и раскидать job-ы по ним.
host1 /etc/prometheus/prometheus.yml
global:
scrape_interval: 60s
scrape_timeout: 5s
external_labels:
__ha_group__: group_1
__ha_replica__: replica_1
remote_write:
- name: cortex_tenant
url: http://127.0.0.1:8080/push
scrape_configs:
- job_name: job1
scrape_interval: 60s
static_configs:
- targets:
- ctx1:9090
labels:
ctx_tenant: foobar
- job_name: job2
scrape_interval: 60s
static_configs:
- targets:
- ctx2:9090
labels:
ctx_tenant: deadbeefhost2 /etc/prometheus/prometheus.yml
global:
scrape_interval: 60s
scrape_timeout: 5s
external_labels:
__ha_group__: group_1
__ha_replica__: replica_2
remote_write:
- name: cortex_tenant
url: http://127.0.0.1:8080/push
scrape_configs:
- job_name: job1
scrape_interval: 60s
static_configs:
- targets:
- ctx1:9090
labels:
ctx_tenant: foobar
- job_name: job2
scrape_interval: 60s
static_configs:
- targets:
- ctx2:9090
labels:
ctx_tenant: deadbeefПо сути конфигурации в пределах одной HA-группы должны отличаться только лейблом реплики.
Cortex
Ну и последнее. Так как мы будем запускать все модули вместе - конфиг получится довольно объемный. Поэтому разделим его на части, чтобы читабельнее было.
Многие модули, такие как Distributor, Ingester, Compactor, Ruler кластеризуются с помощью Hash-Ring в etcd. На весь кластер выделяется некоторое количество токенов, которые распределяются между всеми участниками кольца равномерно.
Упрощенно - при приходе, допустим, новой метрики её метки хешируются, результат делится по модулю на количество токенов и в итоге направляется на хост, который владеет данным диапазоном токенов. Если он не отвечает - то отправляют следующему по кольцу хосту.
Если хост выходит из кластера (помер, перезагружается и т.п.), то его диапазон перераспределяется по остальным.
Все настройки у нас будут лежать в /etc/cortex/cortex.yml
Также т.к. Cortex сделан для работы в контейнерах - всё можно настроить через командную строку чтобы не пропихивать конфиг в контейнер.
Глобальные настройки
# Список модулей для загрузки
target: all,compactor,ruler,alertmanager
# Требовать ли заголовок X-Scope-OrgId
auth_enabled: true
# Порты
server:
http_listen_port: 9009
grpc_listen_port: 9095
limits:
# Разрешаем HA-трекинг
accept_ha_samples: true
# Названия меток, которые мы используем в Prometheus для
# маркировки групп и реплик
ha_cluster_label: __ha_group__
ha_replica_label: __ha_replica__
# Максимальный период в прошлое на который мы можем делать
# PromQL запросы (1 год).
# Всё что больше будет обрезано до этого периода.
# Это нужно для реализации retention period.
# Для фактического удаления старых блоков нужно еще настроить lifecycle
# правило в бакете S3 на пару дней глубже
max_query_lookback: 8760hТак как Cortex создавался для работы в распределённом режиме в облаке, то работа всех модулей в одном бинарнике считается нетипичной, но я никаких проблем не наблюдал.
Другой трудностью изначально было то, что Cortex не поддерживал гибкий список модулей, которые нужно активировать. Была возможность либо указать all, который на самом деле ни разу не all:
# cortex -modules
alertmanager
all
compactor
configs
distributor *
flusher
ingester *
purger *
querier *
query-frontend *
query-scheduler
ruler *
store-gateway *
table-manager *
Modules marked with * are included in target All.Либо указать строго один модуль.
Поэтому пришлось сделать пулл-реквест чтобы добавить возможность загружать список любых модулей. В данном случае мы используем all + compactor, ruler и alertmanager
Хранилище
storage:
# Выбираем хранилище Blocks Storage
engine: blocks
# Конфигурируем его
blocks_storage:
# Тип бэкенда
backend: s3
# Параметры доступа к S3
s3:
endpoint: 127.0.0.1:9001
bucket_name: cortex
access_key_id: foo
secret_access_key: bar
# TLS у нас нет
insecure: true
tsdb:
# Где хранить локальные блоки до загрузки в S3
dir: /data/cortex/tsdb
# Через какое время их удалять
retention_period: 12h
# Сжимать Write-Ahead Log
wal_compression_enabled: true
bucket_store:
# Где хранить индексы блоков, найденных в S3
# По сути это должно быть в модуле Store-Gateway,
# но по какой-то причине тут
sync_dir: /data/cortex/tsdb-sync
# Как часто сканировать S3 в поиске новых блоков
sync_interval: 1m
# Настраиваем различные кеши на наши memcached
# Каждый кеш имеет свой префикс ключей, так что пересекаться они не будут
index_cache:
backend: memcached
memcached:
addresses: ctx1:11211,ctx2:11211,ctx3:11211,ctx4:11211
chunks_cache:
backend: memcached
memcached:
addresses: ctx1:11211,ctx2:11211,ctx3:11211,ctx4:11211
metadata_cache:
backend: memcached
memcached:
addresses: ctx1:11211,ctx2:11211,ctx3:11211,ctx4:11211Distributor
distributor:
ha_tracker:
# Включить HA-трекер для Prometheus
enable_ha_tracker: true
# Таймаут после которого срабатывает failover на другую реплику Prometheus.
# Нужно настроить так чтобы метрики приходили не реже этого интервала,
# иначе будут ложные срабатывания.
ha_tracker_failover_timeout: 30s
# Настраиваем etcd для HA-трекера
kvstore:
store: etcd
etcd:
endpoints:
- http://ctx1:2379
- http://ctx2:2379
- http://ctx3:2379
- http://ctx4:2379
# Настраиваем etcd для Hash-Ring дистрибьютеров
ring:
kvstore:
store: etcd
etcd:
endpoints:
- http://ctx1:2379
- http://ctx2:2379
- http://ctx3:2379
- http://ctx4:2379Ingester
ingester:
lifecycler:
address: 10.0.0.1
# Название зоны доступности
availability_zone: dc1
# Немного ждём чтобы всё устаканилось перед перераспределением
# токенов на себя
join_after: 10s
# Храним токены чтобы не генерировать их каждый раз при запуске
tokens_file_path: /data/cortex/ingester_tokens
ring:
# На сколько Ingester-ов реплицировать метрики.
# Если указана зона доступности, то реплики будут выбираться из разных зон
replication_factor: 2
# etcd для Hash-Ring Ingester-ов
kvstore:
store: etcd
etcd:
endpoints:
- http://ctx1:2379
- http://ctx2:2379
- http://ctx3:2379
- http://ctx4:2379Querier
По поводу подбора правильных величин лучше почитать документацию.
Основная идея в том, чтобы никогда не запрашивать те блоки, которые еще не обработал Compactor:
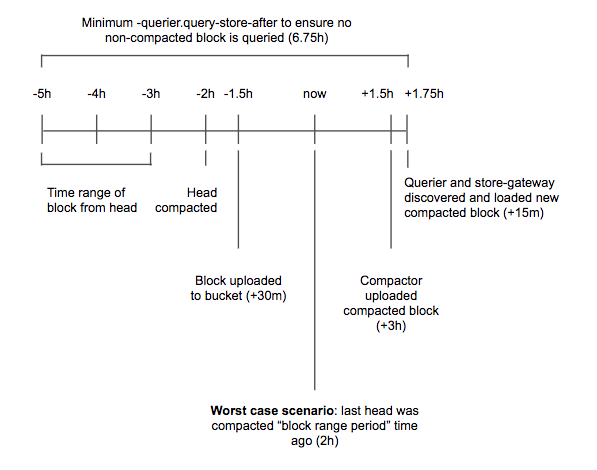
querier:
# Временные файлы
active_query_tracker_dir: /data/cortex/query-tracker
# Запросы с глубиной больше этой будут направляться в S3
query_store_after: 6h
# Запросы с глубиной меньше этой отправляются в Ingester-ы
query_ingesters_within: 6h5m
frontend_worker:
frontend_address: 127.0.0.1:9095
query_range:
# Запросы будут разбиваться на куски такой длины и выполняться параллельно
split_queries_by_interval: 24h
# Выравнивать интервал запроса по его шагу
align_queries_with_step: true
# Включить кеширование результатов
cache_results: true
# Кешируем в memcached
results_cache:
# Сжимаем
compression: snappy
cache:
# TTL кеша
default_validity: 60s
memcached:
expiration: 60s
memcached_client:
addresses: ctx1:11211,ctx2:11211,ctx3:11211,ctx4:11211Store-Gateway
Этот модуль подгружает из S3 бакета заголовки блоков (комбинации меток, временные интервалы и т.п.).
Если включить шардинг и репликацию, то участники кластера распределят все блоки между собой равномерно и каждый блок будет на 2 или более хостах.
store_gateway:
# Включаем шардинг
sharding_enabled: true
sharding_ring:
# Включаем zone awareness
zone_awareness_enabled: true
# Идентификатор зоны
instance_availability_zone: dc1
# Сколько реплик держать
replication_factor: 2
# Hash-ring для Store-Gateway
kvstore:
store: etcd
etcd:
endpoints:
- http://ctx1:2379
- http://ctx2:2379
- http://ctx3:2379
- http://ctx4:2379Compactor
Этот модуль работает сам по себе и с остальными никак не взаимодействует. Можно активировать шардинг, тогда все компакторы в кластере распределят между собой tenant-ов и будут обрабатывать их параллельно.
compactor:
# Временная директория для блоков.
# Должно быть достаточно много места чтобы можно было загрузить блоки,
# скомпактить их и сохранить результат.
data_dir: /data/cortex/compactor
# Как часто запускать компакцию
compaction_interval: 30m
# Hash-Ring для компакторов
sharding_enabled: true
sharding_ring:
kvstore:
store: etcd
etcd:
endpoints:
- http://ctx1:2379
- http://ctx2:2379
- http://ctx3:2379
- http://ctx4:2379Ruler + AlertManager
Эти модули опциональны и нужны только если хочется генерировать алерты на основе правил.
Правила в стандартном Prometheus формате мы будем складывать в
/data/cortex/rules/<tenant>/rulesN.ymlна каждом хосте. Можно использовать для этого S3 или другие хранилища - см. документациюCortex периодически сканирует хранилище и перезагружает правила
Конфиги AlertManager в стандартном формате складываем в
/data/cortex/alert-rules/<tenant>.ymlАналогично можно складывать в S3 и т.п.
Cortex запускает инстанс AlertManager (внутри своего процесса) отдельно для каждого tenant, если находит конфигурацию в хранилище
ruler:
# Временные файлы
rule_path: /data/cortex/rules-tmp
# Включаем шардинг
enable_sharding: true
# Какому AlertManager-у сообщать об алертах
alertmanager_url: http://ctx1:9009/alertmanager
# Откуда загружать правила
storage:
type: local
local:
directory: /data/cortex/rules
# Hash-ring для Ruler-ов
ring:
kvstore:
store: etcd
etcd:
endpoints:
- http://ctx1:2379
- http://ctx2:2379
- http://ctx3:2379
- http://ctx4:2379
alertmanager:
# Где хранить состояние алертов
data_dir: /data/cortex/alert-data
# Внешний URL нашего инстанса (нужен для генерации ссылок и т.п.)
external_url: http://ctx1:9009/alertmanager
# Кластеринг - какой адрес слушать и какой анонсировать пирам
cluster_bind_address: 0.0.0.0:9094
cluster_advertise_address: 10.0.0.1:9094
# Список пиров
peers:
- ctx2:9094
- ctx3:9094
- ctx4:9094
# Откуда загружать настройки
storage:
type: local
local:
path: /data/cortex/alert-rulesЗаключение
Вот и всё, можно запускать все сервисы - сначала зависимости, потом Cortex, затем - Prometheus.
Я не претендую на полноту, но этого должно быть достаточно чтобы начать работать.
Нужно учитывать, что Cortex активно развивается и на момент написания статьи часть параметров в master-ветке и документации (которая генерируется из неё) уже объявлено deprecated. Так что, вполне возможно, в новых версиях нужно будет конфиги немного исправлять.
Если есть вопросы и\или замечания - пишите, постараюсь добавить в статью.



