
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Сегодня популярность проектов data science очень высока и бизнес понимает их важность и значимость. Рынок наполнен специалистами в этой области, которые умеют добиваться впечатляющих результатов. Но такие проекты нередко бывают дорогостоящими, и не всегда для простых задач нужно привлекать профессионалов в этой области. Создание некоторых прогнозов вполне по силам самим бизнес-пользователям. Например, специалисты из отдела маркетинга могут прогнозировать отклик на маркетинговые кампании. Это становится возможным при наличии инструмента, позволяющего за несколько минут построить прогноз и легко интерпретировать результаты с точки зрения бизнес-смысла.
SAP Analytics Cloud (SAC) – облачный инструмент, совмещающий в себе функции BI, планирования и прогнозирования, он также оснащен множеством функций расширенной аналитики: интеллектуальными подсказками, автоматизированным анализом данных и возможностями автоматического прогнозирования.
В этой статье мы расскажем о том, как построено прогнозирование в SAP Analytics Cloud, какие сценарии доступны на сегодняшний день, а также как этот процесс может быть интегрирован с планированием.
Функциональность Smart Predict ориентирована на бизнес-пользователя и позволяет строить прогнозы высокой точности без привлечения специалистов Data Science. Со стороны пользователя системы прогноз происходит в «черном ящике», но в реальности это, конечно же, не так. Алгоритмы прогнозирования в SAC идентичны алгоритмам модуля Automated Analytics инструмента SAP Predictive Analytics. Об алгоритмах, лежащих в основе этого продукта, есть множество материалов, мы предлагаем прочитать эту статью. На вопрос: «Получается, Automated Analytics переехал в SAP Analytics Cloud? - мы отвечаем - Да, но пока только частично». Вот какая разница и сходство в функциональных возможностях инструментов (рис.1)
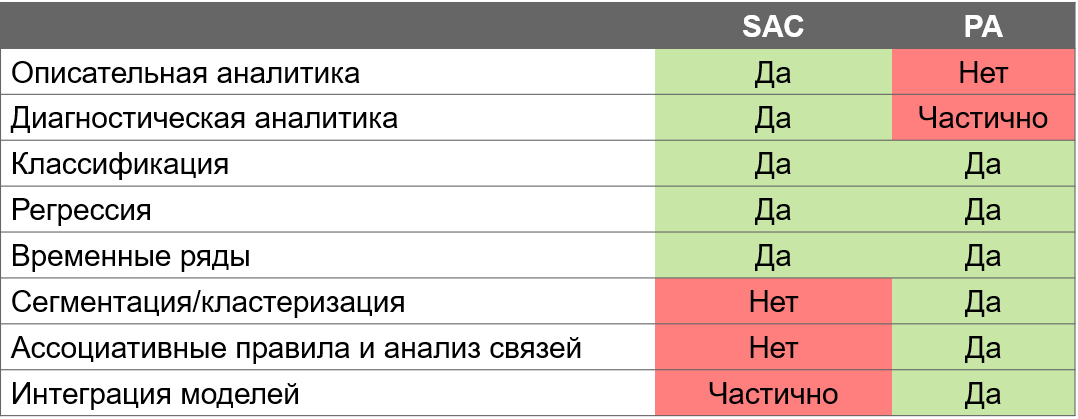
SAP Analytic Cloud в настоящее время предлагает 3 прогнозных сценария:
Классификация. В данном случае предполагается бинарная классификация: предсказываются значения целевой переменной, которая может иметь только два значения -«да» и «нет» или 0 и 1. Примерами сценария классификации могут быть:
· Прогноз оттока клиентов, где целевая переменная предсказывает, уйдет клиент или нет.
· Прогноз склонности клиента к покупке с целевой переменной, прогнозирующей будет ли клиент покупать предложенный ему товар или нет.
· Выявление мошенничества с целевой переменной, указывающей, была ли транзакция или требование мошенническим, или нет.
Регрессия. Предсказывает числовое значение целевой переменной в зависимости от переменных, описывающих ее. Примеры регрессионных сценариев:
· Количество клиентов, посещающих магазин в обеденное время.
· Выручка от каждого клиента в следующем квартале.
· Цена продажи подержанных автомобилей.
Прогнозирование временного ряда. Предсказывает значение переменной с течением времени с учетом дополнительных описательных переменных. Примеры сценария прогнозирования временных рядов:
· Выручка по каждой продуктовой линейке в течение следующих нескольких кварталов.
· Количество велосипедов, арендованных в городе в течение следующих нескольких дней.
· Командировочные расходы в ближайшие несколько месяцев.
В процессе прогнозирования мы будем работать с тремя типами датасетов: тренировочным, прикладным и результирующим (рис. 2)

Процесс прогнозирования в SAP Analytics Cloud осуществляется в несколько простых этапов. Мы рассмотрим его на примере прогнозирования оттока клиентов интернет-магазина. Для начала нам необходимо загрузить в систему тренировочный датасет из системы-источника или excel файла. Также SAP Analytics Cloud позволяет прогнозировать в режиме Live (избегая загрузки данных в облако) на таблицах SAP HANA. В этом случае для пользователя SAC процесс остается неизменным, но построение прогноза происходит на стороне SAP HANA с использованием библиотеки Automated Predictive Library (APL).
Наш тренировочный датасет имеет следующие поля:
Customer ID | Уникальный ID каждого клиента |
Usage Category (Month) | Количество времени, проведенное клиентом на портале в текущем месяце |
Average Usage (Year) | Среднее количество времени, проведенное клиентом на портале за прошедший год |
Usage Category (previous Month) | Количество времени, проведенное клиентом на портале за прошедший месяц |
Service Type | Флаговая переменная, указывающая тип сервиса клиента: премиум или стандарт |
Product Category | Категория продукта интернет-магазина, наиболее часто заказываемая клиентом |
Message Allowance | Флаговая переменная, указывающая, давал ли клиент согласие на получение сообщений |
Average Marketing Activity (Bi-yearly) | Среднее число маркетинговых предложений для клиента за последние 2 года |
Average Visit Time (min) | Среднее количество времени, проведенное клиентом на портале за каждый визит |
Pages per Visit | Среднее число страниц интернет-магазина, посещаемых клиентом за один визит |
Delta Revenue (Previous Month) | Разница между выручкой от данного клиента за предыдущий и текущий месяц |
Revenue (Current Month) | Выручка от данного клиента в текущем месяце |
Service Failure Rate (%) | Доля случаев, когда пользователь сталкивался с ошибками в работе портала |
Customer Lifetime (days) | Количество дней с момента регистрации |
Product Abandonment | Число продуктов, которые были помещены клиентом в корзину, но не оплачены за последний квартал |
Contract Activity | Флаговая переменная, указывающая, отказался ли данный пользователь от услуг интернет-магазина. Целевая переменная, которую мы будем прогнозировать. |
Следующим шагом построение прогноза будет выбор сценария прогнозирования.

Под каждой опцией есть описание, чтобы облегчить пользователю выбор правильного сценария для каждого варианта использования. Сейчас мы хотим создать модель, позволяющую предсказать, какие клиенты интернет-магазина наиболее склонны к оттоку. Исходя из описаний прогнозных типов сценариев, мы видим, что «классификация» сможет удовлетворить наши потребности. Итак, мы выбираем «Классификация».
После этого мы создаем прогнозную модель и выбираем заранее подготовленный датасет, как источник данных для обучения. У пользователя также есть возможность редактировать метаданные. Далее мы выбираем целевую переменную, ее мы будем прогнозировать. В нашем случае это переменная Contract Activity, идентифицирующая отток клиентов. Также мы можем исключить некоторые переменные, если понимаем, что они никак не повлияют на формирование прогноза. Например, в нашем случае точно можно исключить Customer ID. Это может ускорить процесс выполнения прогноза, но их сохранение не мешает процессу моделирования.

После указания всех желаемых вводных мы отправляем модель на обучение. На основе исторических данных модель выявляет закономерности, то есть находит шаблоны по характеристикам клиента, который с большой вероятностью может отказаться от услуг интернет-магазина. При этом в наборе данных обучения должно быть достаточно целевых примеров, то есть данных об ушедших клиентах.
Во время обучения инструмент автоматически протестирует и попытается уменьшить количество переменных в модели, в зависимости от критериев качества, которые мы опишем ниже. Этот выбор выполняется последовательными итерациями, и сохраняются только те переменные, которые влияют на цель.
После обучения модели нам выдается подробный отчет о ее качестве, как показано на рисунке ниже. Мы видим два ключевых показателя эффективности: прогностическая сила и достоверность прогноза.

Прогностическая сила (KI) указывает на долю информации в целевой переменной, которую могут описать другие переменные модели (объясняющие переменные). Гипотетическая модель с прогностической силой 1,0 является идеальной, поскольку позволяет объяснить 100% информации целевой переменной, а модель с прогностической силой 0 является чисто случайной.
Достоверность прогноза (KR) показывает способность модели достичь той же производительности, когда она применяется к новому набору данных, имеющему те же характеристики, что и обучающий набор данных. Приемлемой считается достоверность прогноза не менее 95%.

Также отчет предоставляет информацию о переменных, которые в процессе генерации прогнозной модели были идентифицированы как ключевые, и упорядочивает их по степени влияния на целевую переменную.
Кроме этого, на рисунке ниже мы видим кривую производительности AUC ROC. Ось X показывает, какой процент от общей выборки составляют положительные цели; ось Y представляет их верно идентифицированный процент, который обнаружил алгоритм. Здесь необходимо пояснить, что положительными целями в данном случае считается целевая группа, а именно клиенты, отказавшиеся от услуг интернет-магазина.

Зеленая кривая олицетворяет некую идеальную модель с максимально возможным процентом обнаруженной цели. Например, если 25% общей выборки будут составлять ушедшие клиенты, то идеальная модель правильно классифицирует все 25% таких клиентов.
Красная кривая показывает минимальный процент обнаруженной цели, полученный случайной моделью. То есть случайно взяв 10% населения, вы бы определили 10% клиентов.
Синяя кривая показывает процент обнаруженной цели с использованием нашей модели. Например, если 10% выборки составляют ушедшие клиенты, мы обнаруживаем примерно 75%. Чем ближе синяя линия подходит к зеленой, тем лучше модель. Чем больше расстояние между красной и синей линиями, тем больше лифт модели.
Кроме того, SAC предоставляет возможность увидеть, как именно ключевые факторы влияют на целевую переменную.

Например, посмотрим более подробную аналитику по предиктору Average Visit Time, показывающему среднее количество времени, которое клиент проводит на портале интернет-магазина. По умолчанию предлагается отследить влияние этого фактора на столбчатой диаграмме, но также существует возможность настройки различных типов визуализации.
Мы видим, что клиенты, проводившие на страницах интернет-магазина от 10 до 22 и от 1 до 3 минут, имеют наибольшую склонность отказаться от услуг. Напротив, покупатели, находящиеся на портале от 3 до 7 и от 7 до 10 минут, показывают наименьшую вероятность уйти. Результаты выглядят волне логично: уходят те, кто проводили на сайте или слишком мало, или слишком много времени. Подобный анализ можно провести по всем ключевым предикторам.
Также для оценки качества получившейся модели SAC предлагает проанализировать матрицы неточностей, различные графики, иллюстрирующие эффективность модели (лифт, чувствительность, кривая Лоренца и плотность) и смоделировать возможные выигрыши и проигрыши от использования данного прогноза.
После того, как мы проанализировали модель и убедились в качестве, мы можем ее применить. Для этого мы находим датасет, который идентичен тренировочному по структуре, но содержит данные о новых клиентах, уход которых мы хотим предсказать. Далее мы выбираем переменные, которые надо увидеть в финальном датасете, а также указываем, какие характеристики получившегося прогноза мы хотим добавить.

На выходе мы получаем датасет с прогнозными значениями целевой переменной, на основе которого может быть легко сформирована модель данных. Она, в свою очередь, может являться источником данных для построения аналитической отчетности в SAC. Например, для этого кейса мы использовали интеллектуальную функцию Smart Discovery и получили автоматических дашборд на спрогнозированных данных.

Таким образом, прогнозирование легко вписывается в процесс анализа данных в SAC. С недавних пор функционал прогнозирования в решении также может быть легко интегрирован в процесс планирования.

Теперь SAC также позволяет использовать модели планирования, как данные для обучения предиктивных моделей. Даже если модель уже есть в отчетах и плановых формах ввода, можно создать частную версию прогноза или бюджета, и использовать алгоритм прогноза временного ряда для желаемого показателя. В качестве данных для тренировки модели может быть использован как факт, так и прогноз, бюджет или любая другая существующая версия данных. В дальнейшем процесс не будет отличаться от вышеописанного: пользователю будет предоставлен подробный отчет о качестве модели. В итоге спрогнозированные показатели будут записываться в созданную нами частную версию модели планирования.
Кроме того, в процессе создания отчетов пользователи также могут использовать прогностические функции, например, автоматический прогноз. Он позволяет продлить график временного ряда.

Алгоритм выполнения такого прогноза описан здесь, линейная регрессия или тройное экспоненциальное сглаживание. Результаты прогноза видны ниже, рядом с графиком факта появляется пунктирная линия прогноза и доверительный интервал.

Также прогноз можно добавлять в таблицы и использовать оттуда данные, например, как базу для будущего плана.
Таким образом, процесс прогнозирования в SAP Analytics Cloud достаточно прост и максимально ориентирован на бизнес-пользователя, но дает возможность получения прогностических моделей высокого качества для решения типовых бизнес-задач.
Данный инструмент является stand-alone решением и может стать частью мультивендорной архитектуры. Интеграция SAP Analytics Cloud с решениями SAP нативна. Кроме того, существует стандартный бизнес контент для различных индустрий и линий бизнеса. Отчеты могут быть дополнены прогнозными и плановыми данными, а также обогащены функциями расширенной аналитики.
Автор – Анастасия Николаичева, архитектор бизнес-решений SAP CIS




