
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Как Web Scraping помог собрать нам данные по официальным коллекциям как у Белгазпромбанка.
Web Scraping — один из самых популярных методов считывания различных данных, расположенных на веб-страницах, для их систематизации и дальнейшего анализа. По сути, это можно назвать “парсингом сайтов”, где информация собирается и экспортируется более удобный для пользователя формат будь то таблица или API.
Инструменты Web Scraping позволяют не только вручную, но и автоматически получать новые или обновленные данные для успешной реализации поставленных целей.
Для чего используется Web Scraping?
Команда Lansoft достаточно успешно освоила данный метод. Поэтому хотим поделиться с вами одним из кейсов по сбору данных для анализа датасэтов предметов искусства для нью-йоркской компании Pryph.
Pryph анализируют знаменитые аукционные дома такие как Christie’s, Sotheby’s и Phillips и резюмируют выводы о популярности различных авторов.
Кстати на этих аукционах были куплены несколько картин в нашумевшем деле Белгазпромбанка и Виктора Бабарико. По нашему мнению эти сделки никак нельзя назвать незаконными (ссылка news.tut.by/culture/349226.html)
Для работы мы выбрали инструмент — Puppeteer. Это JavaScript библиотека для Node.js, которая управляет браузером Chrome без пользовательского интерфейса.
При помощи данной библиотеки можно достаточно легко автоматический считывать данных с различных веб-сайтов или создавать так называемые веб-скраперы, имитирующие действия пользователя.
На самом деле есть более оптимальные способы скрапинга сайтов средствами node.js
(описаны тут — habr.com/ru/post/301426).
Причины выбора Puppeteer в нашем случае были:
Итак, наша задача была зайти на сайты аукционных домов и по каждому виду аукционов собрать данные по продажам всех лотов за год с 2006 по 2019 годы.
Для примера мы вставили кусок кода, написанного на Puppeteer для извлечения ссылок картинок лотов с аукционного дома Phillips:

В подобном ключе команде Lansoft для каждого лота нужно было найти имя автора, описание работы, цену, детали о продаже и ссылку на предметы искусства.
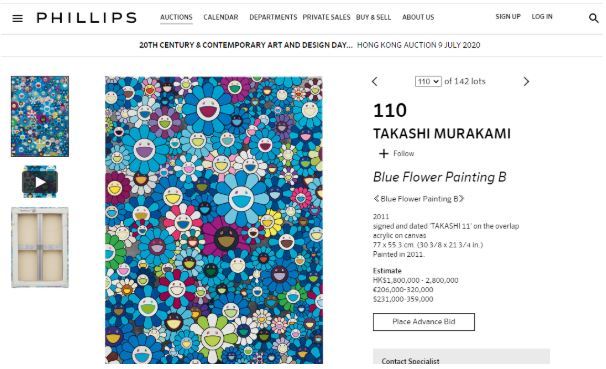
Примеры ссылок на лоты:
www.phillips.com/detail/takashi-murakami/HK010120/110
www.sothebys.com/en/buy/auction/2020/contemporary-art-evening-auction/lynette-yiadom-boayke-cloister?locale=en
Например, на картинке выше мы видим имя автора TAKASHI MURAKAMI, название картины “Blue Flower Painting B” и данные по цене в $231,000-359,000. Все необходимые поля мы собирали и записывали в csv файлы, разбитые по годам.
Выглядело это так:
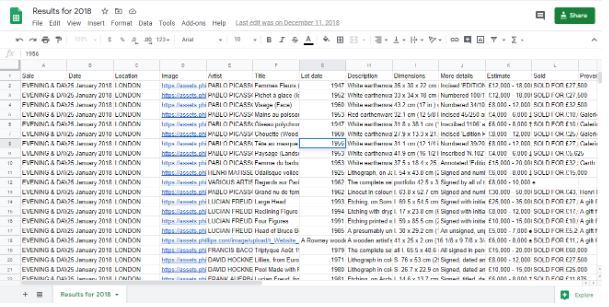
Как итог мы получили наборы csv файлов по продажам за разные годы. Размер файлов был порядка 6.000 строк. А далее клиент используя свои алгоритмы, делал анализ по трендам для различных авторов.
Результаты работы можно найти на сайте pryph.org/insights
Но в работе с Puppeteer есть некоторые нюансы:
Web Scraping — один из самых популярных методов считывания различных данных, расположенных на веб-страницах, для их систематизации и дальнейшего анализа. По сути, это можно назвать “парсингом сайтов”, где информация собирается и экспортируется более удобный для пользователя формат будь то таблица или API.
Инструменты Web Scraping позволяют не только вручную, но и автоматически получать новые или обновленные данные для успешной реализации поставленных целей.
Для чего используется Web Scraping?
- Сбор данных для маркетинговых исследований. Позволяет в сжатые сроки подготовить информацию для принятия стратегически важных решений в ведении бизнеса.
- Для извлечения определенной информации (телефонов, е-мейлов, адресов) с различных сайтов для создания собственных списков.
- Сбор данных о товарах для анализа конкурентов.
- Очистка данных сайта перед миграцией.
- Сбор финансовых данных.
- В работе HR для отслеживания резюме и вакансий.
Команда Lansoft достаточно успешно освоила данный метод. Поэтому хотим поделиться с вами одним из кейсов по сбору данных для анализа датасэтов предметов искусства для нью-йоркской компании Pryph.
Pryph анализируют знаменитые аукционные дома такие как Christie’s, Sotheby’s и Phillips и резюмируют выводы о популярности различных авторов.
Кстати на этих аукционах были куплены несколько картин в нашумевшем деле Белгазпромбанка и Виктора Бабарико. По нашему мнению эти сделки никак нельзя назвать незаконными (ссылка news.tut.by/culture/349226.html)
Для работы мы выбрали инструмент — Puppeteer. Это JavaScript библиотека для Node.js, которая управляет браузером Chrome без пользовательского интерфейса.
При помощи данной библиотеки можно достаточно легко автоматический считывать данных с различных веб-сайтов или создавать так называемые веб-скраперы, имитирующие действия пользователя.
На самом деле есть более оптимальные способы скрапинга сайтов средствами node.js
(описаны тут — habr.com/ru/post/301426).
Причины выбора Puppeteer в нашем случае были:
- анализ всего 3 сайтов с понятными разделами и структурой;
- активное продвижение данного инструмента компанией Google;
- эмуляция работы реальных пользователя на UI без риска попасть в бан, как потенциальные DDOS атаки.
Итак, наша задача была зайти на сайты аукционных домов и по каждому виду аукционов собрать данные по продажам всех лотов за год с 2006 по 2019 годы.
Для примера мы вставили кусок кода, написанного на Puppeteer для извлечения ссылок картинок лотов с аукционного дома Phillips:
В подобном ключе команде Lansoft для каждого лота нужно было найти имя автора, описание работы, цену, детали о продаже и ссылку на предметы искусства.
Примеры ссылок на лоты:
www.phillips.com/detail/takashi-murakami/HK010120/110
www.sothebys.com/en/buy/auction/2020/contemporary-art-evening-auction/lynette-yiadom-boayke-cloister?locale=en
Например, на картинке выше мы видим имя автора TAKASHI MURAKAMI, название картины “Blue Flower Painting B” и данные по цене в $231,000-359,000. Все необходимые поля мы собирали и записывали в csv файлы, разбитые по годам.
Выглядело это так:
Как итог мы получили наборы csv файлов по продажам за разные годы. Размер файлов был порядка 6.000 строк. А далее клиент используя свои алгоритмы, делал анализ по трендам для различных авторов.
Результаты работы можно найти на сайте pryph.org/insights
Но в работе с Puppeteer есть некоторые нюансы:
- некоторые ресурсы могут блокировать доступ при обнаружении непонятной активности;
- эффективность Puppeteer не высока, ее можно повысить за счет троттлинга анимации, ограничения сетевых вызовов и т. д.;
- необходимо завершать сеанс, используя экземпляр браузера;
- контекст страницы/браузера отличается от контекста ноды, в которой работает приложение;
- использовать браузер, даже в Headless режиме не так эффективно и быстро по времени для больших анализов данных.



