
Хабр, привет! Сегодня я расскажу, как мы делали аудит изображений, используя компьютерное зрение, сверточную нейронную сеть FaceNet, а также про кластеризацию гистограмм с целью поиска аномальных изображений.

Меня зовут Александр, я развиваю направление аналитики данных и технологий для целей внутреннего аудита группы Росбанк. Мы с командой используем машинное обучение и нейронные сети для выявления рисков в рамках проверок внутреннего аудита. В нашем арсенале сервер ~300 GB RAM и 4 процессора по 10 ядер. Для алгоритмического программирования или моделирования мы используем Python.
Перед нами стояла задача проанализировать фотографии (портреты) клиентов, сделанные сотрудниками банка во время оформления банковского продукта. Наша цель – выявить ранее непокрытые риски, исходя из этих фотографий. Для выявления риска мы генерируем и тестируем набор гипотез. В этой статье я опишу какие гипотезы мы придумали и как мы их тестировали. Для упрощения восприятия материала буду использовать Мону Лизу – эталон портретного жанра.

Сперва мы использовали подход без машинного обучения и компьютерного зрения, просто сравнивая контрольные суммы файлов. Для их формирования мы взяли широко распространённый алгоритм md5 из библиотеки hashlib.
Реализация на Python*:
При формировании контрольной суммы мы сразу проверяем наличие дублей с помощью словаря.
Этот алгоритм невероятно прост с точки зрения вычислительной нагрузки: на нашем сервере 1000 изображений обрабатывается не более 3 секунд.
Такой алгоритм помог нам выявить дубли фото среди наших данных, и как следствие найти места для потенциального улучшения бизнес-процесса банка.
Несмотря на положительный результат работы метода контрольных сумм, мы отлично понимали, что в случае изменения хотя бы одного пикселя в изображении его контрольная сумма получится кардинально другой. Как логическое развитие первой гипотезы, мы предположили, что изображение могло быть изменено по битовой структуре: подвергнуться пересохранению (то есть повторная компрессия jpg), изменению размера, обрезке или повороту.
Для демонстрации обрежем края по красному контуру и повернем Мону Лизу вправо на 90 градусов.

В таком случае дубликаты необходимо искать по визуальному контенту изображения. Для этого мы решили использовать библиотеку OpenCV, метод построения ключевых точек изображения и поиска расстояния между ключевыми точками. На практике ключевыми точками могут быть углы, градиенты цвета или изломы поверхностей. Для наших целей подошел один из самых простых методов — Brute-Force Matching. Для измерения расстояния между ключевыми точками изображения мы использовали расстояние Хэмминга. На картинке ниже результат поиска ключевых точек на исходном и измененном изображениях (отрисованы 20 наиболее близких по расстоянию ключевых точек изображений).
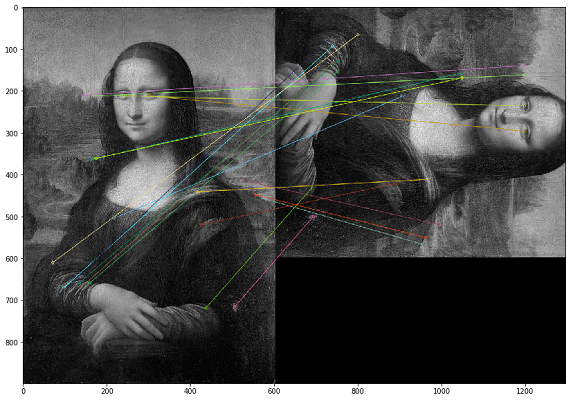
Важно отметить, что мы анализируем изображения в черно-белом фильтре, так как это оптимизирует время работы скрипта и дает более однозначную интерпретируемость ключевых точек. Если одно изображение будет с фильтром «сепия», а другое — в цветном оригинале, то, когда мы приведем их к черно-белому фильтру, ключевые точки будут идентифицированы независимо от цветовой обработки и фильтров.
Пример кода для сравнения двух изображений*
В ходе тестирования результатов мы осознали, что в случае зеркального отображения изображения (flip) порядок пикселей в рамках ключевой точки меняется и такие изображения не идентифицируются как одинаковые. В качестве компенсирующей меры можно самостоятельно сделать зеркальное отображение каждого изображения и анализировать двойной объем (или даже тройной), что гораздо более затратно с точки зрения вычислительной мощности.
Данный алгоритм имеет высокую вычислительную сложность, а наибольшую нагрузку создает операция вычисления расстояния между точками. Так как нам приходится каждое изображение сравнивать с каждым, то, как вы понимаете, вычисление такого декартова множества требует большого количество вычислительных циклов. В одной из аудиторских проверок подобное вычисление заняло больше месяца.
Ещё одной проблемой данного подхода оказалась плохая интерпретируемость результатов теста. Мы получаем коэффициент расстояний между ключевыми точками изображений, и возникает вопрос: «Какой порог данного коэффициента выбрать достаточным, чтобы считать изображения дублирующимся?».
С использованием компьютерного зрения нам удалось найти случаи, не покрытые первым тестом с контрольными суммами. На практике это оказались пересохраненные jpg-файлы. Более сложных случаев изменения изображений в анализируемом датасете мы не выявили.
Разработав два кардинально разных подхода к поиску дублей и заново использовав их в нескольких проверках, мы пришли к выводу, что для наших данных контрольная сумма даёт более ощутимый результат в более короткие сроки. Поэтому если у нас есть достаточного времени на проверку, то мы делаем сравнение и по ключевым точкам.
Проанализировав результаты выполнения теста по ключевым точкам, мы заметили, что фотографии, сделанные одним сотрудником, имеют примерно похожее число близких ключевых точек. И это логично, ведь если он общается с клиентами у себя на рабочем месте и делает снимки в одном и том же помещении, то фон на всех его фото будет совпадать. Это наблюдение привело нас к мысли, что мы можем найти фотографии-исключения непохожие на остальные фотографии этого сотрудника, которые, возможно, сделаны вне офиса.
Возвращаясь к примеру с Моной Лизой, получается, что на этом же фоне будут появляться другие люди. Но, к сожалению, таких примеров у нас не нашлось, поэтому в этом разделе мы покажем метрики данных без примеров. Для увеличения скорости вычисления в рамках тестирования этой гипотезы мы решили отказать от ключевых точек, а использовать гистограммы.
Первый шаг состоит в переводе картинки в объект (гистограмму), который мы можем измерить для того, чтобы сравнить картинки по расстоянию между их гистограммами. По сути гистограмма — это график, который дает общее представление об изображении. Это график со значениями пикселей по оси абсцисс (оси X) и соответствующим количеством пикселей в изображении по оси ординат (оси Y). Гистограмма — простой способ интерпретации и анализа изображения. С помощью гистограммы картинки можно получить интуитивное представление о контрасте, яркости, распределении интенсивности и так далее.
Для каждой картинки мы создаем гистограмму с помощью функции calcHist из OpenCV.

В приведенных примерах для трех изображений мы описали их с помощью 256 факторов по горизонтальной оси (все типы пикселей). Но также мы можем перегруппировать пиксели. Наша команда не делала много тестов в этой части, так как результат был довольно хорошим при использовании 256 факторов. Если нужно, мы можем поменять этот параметр напрямую в функции calcHist.
После того, как мы создали гистограммы для каждой картинки, мы можем просто обучить модель DBSCAN по изображениям для каждого сотрудника, который сфотографировал клиента. Технический момент здесь состоит в подборе параметров DBSCAN (epsilon и min_samples) для нашей задачи.
После использования DBSCAN мы можем сделать кластеризацию изображений, а после применить метод PCA для визуализации полученных кластеров.

Как видно из распределения анализируемых изображений, у нас есть два ярко выраженных кластера синего цвета. Как оказалось, в разные дни сотрудник может работать в разных кабинетах – фотографии, сделанные в одном из кабинетов, создают отдельный кластер.
В то время как зеленые точки – это фотографии исключения, где фон отличается от этих кластеров.
При детальном анализе фотографий мы обнаружили много ошибочно негативных фото. Самые частые случаи — это засвеченные фотографии или фотографии, на которых большой процент площади занимает лицо клиента. Получается, что этот метод анализа требует обязательного человеческого вмешательства для валидации полученных результатов.
С помощью данного подхода можно найти интересные аномалии в фото, но при этом потребуется инвестиции времени в ручной разбор результатов. По этим причинам мы редко выполняем подобные тесты в рамках проверок.
Итак, мы уже протестировали с разных сторон наш датасет и, продолжая развивать сложность тестирования, мы переходим к следующей гипотезе: а есть ли на фото лицо предполагаемого клиента? Наша задача научиться определять лица на картинках, дать функции на вход картинку и получить на выходе количество лиц.
Такого рода реализация уже существует, и мы решили выбрать для нашей задачи MTCNN (многозадачная каскадная сверточная нейронная сеть) из модуля FaceNet от Google.
FaceNet – это архитектура глубокого машинного обучения, которая состоит из сверточных слоев. FaceNet возвращает 128-мерный вектор для каждого лица. На самом деле FaceNet — это несколько нейронных сетей и набор алгоритмов для подготовки и обработки промежуточных результатов работы этих сетей. Механику поиска лиц этой нейронной сетью мы решили описать подробнее, так как материалов об этом не так много.
Первое действие, которое делает MTCNN, это создание множества размеров нашей фотографии.
MTCNN будет пытаться распознать лица внутри квадрата фиксированного размера на каждой фотографии. Использование такого распознавания на одной и той же фотографии разных размеров увеличит наши шансы на верное распознавание всех лиц на фотографии.

Лицо может не распознаться при нормальном размере изображения, но может быть распознано на изображении другого размера в квадрате фиксированного размера. Этот шаг выполняется алгоритмически без нейронной сети.
После создания разных копий нашей фотографии в ход вступает первая нейронная сеть – P-Net. Эта сеть используя ядро 12х12 (блок), которое будет сканировать все фотографии (копии одного фото, но разного размера), начиная с верхнего левого угла, и двигаться вдоль картины, используя шаг размером в 2 пикселя.

После сканирования всех картинок разного размера MTCNN снова стандартизирует каждую фотографию и пересчитывает координаты блоков.
P-Net дает координаты блоков и уровни доверия (насколько точно это именно лицо) относительно содержащегося в нем лица для каждого блока. Оставлять блоки с определенным уровнем доверия можно с помощью параметра порогового значения.
При этом мы не можем просто выбрать блоки с максимальным уровнем доверия, потому что картина может содержать несколько лиц.
Если один блок перекрывает другой и покрывает почти такую же область, то этот блок удаляется. Эти параметром можно управлять при инициализации сети.

В данном примере желтый блок будет удален. В основном, результатом работы P-Net являются блоки с низкой точностью. На примере ниже представлены реальные результаты работы P-Net:

R-Net выполняет отбор наиболее подходящих блоков, сформированных в результате работы P-Net, которые в группе наиболее вероятно являются лицом. R-Net имеет похожую на P-Net архитектуру. На этом этапе формируются полносвязные слои. Выходные данные R-Net также схожи с выходными данными из P-Net.

O-Net сеть — последняя часть MTCNN сети. В дополнение к последним двум сетям она формирует пять точек для каждого лица (глаза, нос, углы губ). Если эти точки полностью попадают в блок, то он определяется как наиболее вероятно содержащий лицо. Дополнительные точки отмечены синим:

В результате мы получаем финальный блок с указанием точности факта, что это – лицо. Если лицо не найдено, то мы получим нулевое количество блоков с лицом.
В среднем обработка такой сетью 1000 фотографий занимает на нашем сервере 6 минут.
Эту нейронную сеть мы неоднократно использовали в проверках, и она помогла нам в автоматическом режиме выявить аномалии среди фотографий наших клиентов.
Про использование FaceNet хотелось бы добавить, что если вместо Мона Лизы вы станете анализировать полотна Рембрандта, то результаты будут примерно как на изображении ниже, и вам придется разбирать весь список идентифицированных лиц:

Приведенные гипотезы и подходы к тестированию демонстрируют, что с абсолютно любым набором данных можно выполнять интересные тесты и искать аномалии. Cейчас многие аудиторы пытаются развивать подобные практики, поэтому я хотел показать практические примеры использования компьютерного зрения и машинного обучения.
Отдельно хочу добавить, что как следующую гипотезу для тестирования мы рассматривали сравнение лиц (Face Recognition), но пока данные и специфика процессов не дают разумного основания для использования этой технологии в наших проверках.
В целом это все, что я хотел бы рассказать про наш путь в тестировании фотографий.
Желаю вам хорошей аналитики и размеченных данных!
* Пример кода взят из открытых источников.
Самоидентификация
Меня зовут Александр, я развиваю направление аналитики данных и технологий для целей внутреннего аудита группы Росбанк. Мы с командой используем машинное обучение и нейронные сети для выявления рисков в рамках проверок внутреннего аудита. В нашем арсенале сервер ~300 GB RAM и 4 процессора по 10 ядер. Для алгоритмического программирования или моделирования мы используем Python.
Введение
Перед нами стояла задача проанализировать фотографии (портреты) клиентов, сделанные сотрудниками банка во время оформления банковского продукта. Наша цель – выявить ранее непокрытые риски, исходя из этих фотографий. Для выявления риска мы генерируем и тестируем набор гипотез. В этой статье я опишу какие гипотезы мы придумали и как мы их тестировали. Для упрощения восприятия материала буду использовать Мону Лизу – эталон портретного жанра.
Контрольная сумма
Сперва мы использовали подход без машинного обучения и компьютерного зрения, просто сравнивая контрольные суммы файлов. Для их формирования мы взяли широко распространённый алгоритм md5 из библиотеки hashlib.
Реализация на Python*:
#алгоритм определения контрольной суммы
with open(file,'rb') as f:
#последовательно берём блоки файла определенного размера
for chunk in iter(lambda: f.read(4096),b''):
#накопительно калькулируем контрольную сумму файла
hash_md5.update(chunk)
При формировании контрольной суммы мы сразу проверяем наличие дублей с помощью словаря.
#итерируемся по файлам в папке
for file in folder_scan(for_scan):
#определяем контрольную сумму для файла
ch_sum = checksum(file)
#проверяем была ли уже такая контрольная сумма в проверяемых файлах
if ch_sum in list_of_uniq.keys():
#логика в случае неуникального ключа, например, мы фиксируем это в dataframe
df = df.append({'id':list_of_uniq[chs],'same_checksum_with':[file]}, ignore_index = True)
Этот алгоритм невероятно прост с точки зрения вычислительной нагрузки: на нашем сервере 1000 изображений обрабатывается не более 3 секунд.
Такой алгоритм помог нам выявить дубли фото среди наших данных, и как следствие найти места для потенциального улучшения бизнес-процесса банка.
Ключевые точки (компьютерное зрение)
Несмотря на положительный результат работы метода контрольных сумм, мы отлично понимали, что в случае изменения хотя бы одного пикселя в изображении его контрольная сумма получится кардинально другой. Как логическое развитие первой гипотезы, мы предположили, что изображение могло быть изменено по битовой структуре: подвергнуться пересохранению (то есть повторная компрессия jpg), изменению размера, обрезке или повороту.
Для демонстрации обрежем края по красному контуру и повернем Мону Лизу вправо на 90 градусов.
В таком случае дубликаты необходимо искать по визуальному контенту изображения. Для этого мы решили использовать библиотеку OpenCV, метод построения ключевых точек изображения и поиска расстояния между ключевыми точками. На практике ключевыми точками могут быть углы, градиенты цвета или изломы поверхностей. Для наших целей подошел один из самых простых методов — Brute-Force Matching. Для измерения расстояния между ключевыми точками изображения мы использовали расстояние Хэмминга. На картинке ниже результат поиска ключевых точек на исходном и измененном изображениях (отрисованы 20 наиболее близких по расстоянию ключевых точек изображений).
Важно отметить, что мы анализируем изображения в черно-белом фильтре, так как это оптимизирует время работы скрипта и дает более однозначную интерпретируемость ключевых точек. Если одно изображение будет с фильтром «сепия», а другое — в цветном оригинале, то, когда мы приведем их к черно-белому фильтру, ключевые точки будут идентифицированы независимо от цветовой обработки и фильтров.
Пример кода для сравнения двух изображений*
img1 = cv.imread('mona.jpg',cv.IMREAD_GRAYSCALE) # Исходное изображение
img2 = cv.imread('mona_ch.jpg',cv.IMREAD_GRAYSCALE) # Изображение для сравнения
# Инициализируем ORB определитель
orb = cv.ORB_create()
# Ищем ключевые точки с помощью ORB
kp1, des1 = orb.detectAndCompute(img1,None)
kp2, des2 = orb.detectAndCompute(img2,None)
# Создаем Brute-Force Matching сравнитель
bf = cv.BFMatcher(cv.NORM_HAMMING, crossCheck=True)
# Сравниваем ключевые точки.
matches = bf.match(des1,des2)
# Сортируем их по растоянию.
matches = sorted(matches, key = lambda x:x.distance)
# Создаем новое изображение с 20 наиболее близкими ключевыми точками
img3 = cv.drawMatches(img1,kp1,img2,kp2,matches[:20],None,flags=cv.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS)
plt.imshow(img3),plt.show()
В ходе тестирования результатов мы осознали, что в случае зеркального отображения изображения (flip) порядок пикселей в рамках ключевой точки меняется и такие изображения не идентифицируются как одинаковые. В качестве компенсирующей меры можно самостоятельно сделать зеркальное отображение каждого изображения и анализировать двойной объем (или даже тройной), что гораздо более затратно с точки зрения вычислительной мощности.
Данный алгоритм имеет высокую вычислительную сложность, а наибольшую нагрузку создает операция вычисления расстояния между точками. Так как нам приходится каждое изображение сравнивать с каждым, то, как вы понимаете, вычисление такого декартова множества требует большого количество вычислительных циклов. В одной из аудиторских проверок подобное вычисление заняло больше месяца.
Ещё одной проблемой данного подхода оказалась плохая интерпретируемость результатов теста. Мы получаем коэффициент расстояний между ключевыми точками изображений, и возникает вопрос: «Какой порог данного коэффициента выбрать достаточным, чтобы считать изображения дублирующимся?».
С использованием компьютерного зрения нам удалось найти случаи, не покрытые первым тестом с контрольными суммами. На практике это оказались пересохраненные jpg-файлы. Более сложных случаев изменения изображений в анализируемом датасете мы не выявили.
Контрольная сумма VS ключевые точки
Разработав два кардинально разных подхода к поиску дублей и заново использовав их в нескольких проверках, мы пришли к выводу, что для наших данных контрольная сумма даёт более ощутимый результат в более короткие сроки. Поэтому если у нас есть достаточного времени на проверку, то мы делаем сравнение и по ключевым точкам.
Поиск аномальных изображений
Проанализировав результаты выполнения теста по ключевым точкам, мы заметили, что фотографии, сделанные одним сотрудником, имеют примерно похожее число близких ключевых точек. И это логично, ведь если он общается с клиентами у себя на рабочем месте и делает снимки в одном и том же помещении, то фон на всех его фото будет совпадать. Это наблюдение привело нас к мысли, что мы можем найти фотографии-исключения непохожие на остальные фотографии этого сотрудника, которые, возможно, сделаны вне офиса.
Возвращаясь к примеру с Моной Лизой, получается, что на этом же фоне будут появляться другие люди. Но, к сожалению, таких примеров у нас не нашлось, поэтому в этом разделе мы покажем метрики данных без примеров. Для увеличения скорости вычисления в рамках тестирования этой гипотезы мы решили отказать от ключевых точек, а использовать гистограммы.
Первый шаг состоит в переводе картинки в объект (гистограмму), который мы можем измерить для того, чтобы сравнить картинки по расстоянию между их гистограммами. По сути гистограмма — это график, который дает общее представление об изображении. Это график со значениями пикселей по оси абсцисс (оси X) и соответствующим количеством пикселей в изображении по оси ординат (оси Y). Гистограмма — простой способ интерпретации и анализа изображения. С помощью гистограммы картинки можно получить интуитивное представление о контрасте, яркости, распределении интенсивности и так далее.
Для каждой картинки мы создаем гистограмму с помощью функции calcHist из OpenCV.
histo = cv2.calcHist([picture],[0],None,[256],[0,256])В приведенных примерах для трех изображений мы описали их с помощью 256 факторов по горизонтальной оси (все типы пикселей). Но также мы можем перегруппировать пиксели. Наша команда не делала много тестов в этой части, так как результат был довольно хорошим при использовании 256 факторов. Если нужно, мы можем поменять этот параметр напрямую в функции calcHist.
После того, как мы создали гистограммы для каждой картинки, мы можем просто обучить модель DBSCAN по изображениям для каждого сотрудника, который сфотографировал клиента. Технический момент здесь состоит в подборе параметров DBSCAN (epsilon и min_samples) для нашей задачи.
После использования DBSCAN мы можем сделать кластеризацию изображений, а после применить метод PCA для визуализации полученных кластеров.
Как видно из распределения анализируемых изображений, у нас есть два ярко выраженных кластера синего цвета. Как оказалось, в разные дни сотрудник может работать в разных кабинетах – фотографии, сделанные в одном из кабинетов, создают отдельный кластер.
В то время как зеленые точки – это фотографии исключения, где фон отличается от этих кластеров.
При детальном анализе фотографий мы обнаружили много ошибочно негативных фото. Самые частые случаи — это засвеченные фотографии или фотографии, на которых большой процент площади занимает лицо клиента. Получается, что этот метод анализа требует обязательного человеческого вмешательства для валидации полученных результатов.
С помощью данного подхода можно найти интересные аномалии в фото, но при этом потребуется инвестиции времени в ручной разбор результатов. По этим причинам мы редко выполняем подобные тесты в рамках проверок.
Есть ли лицо на фото? (Face Detection)
Итак, мы уже протестировали с разных сторон наш датасет и, продолжая развивать сложность тестирования, мы переходим к следующей гипотезе: а есть ли на фото лицо предполагаемого клиента? Наша задача научиться определять лица на картинках, дать функции на вход картинку и получить на выходе количество лиц.
Такого рода реализация уже существует, и мы решили выбрать для нашей задачи MTCNN (многозадачная каскадная сверточная нейронная сеть) из модуля FaceNet от Google.
FaceNet – это архитектура глубокого машинного обучения, которая состоит из сверточных слоев. FaceNet возвращает 128-мерный вектор для каждого лица. На самом деле FaceNet — это несколько нейронных сетей и набор алгоритмов для подготовки и обработки промежуточных результатов работы этих сетей. Механику поиска лиц этой нейронной сетью мы решили описать подробнее, так как материалов об этом не так много.
Шаг 1: Предобработка
Первое действие, которое делает MTCNN, это создание множества размеров нашей фотографии.
MTCNN будет пытаться распознать лица внутри квадрата фиксированного размера на каждой фотографии. Использование такого распознавания на одной и той же фотографии разных размеров увеличит наши шансы на верное распознавание всех лиц на фотографии.
Лицо может не распознаться при нормальном размере изображения, но может быть распознано на изображении другого размера в квадрате фиксированного размера. Этот шаг выполняется алгоритмически без нейронной сети.
Шаг 2: P-Net
После создания разных копий нашей фотографии в ход вступает первая нейронная сеть – P-Net. Эта сеть используя ядро 12х12 (блок), которое будет сканировать все фотографии (копии одного фото, но разного размера), начиная с верхнего левого угла, и двигаться вдоль картины, используя шаг размером в 2 пикселя.
После сканирования всех картинок разного размера MTCNN снова стандартизирует каждую фотографию и пересчитывает координаты блоков.
P-Net дает координаты блоков и уровни доверия (насколько точно это именно лицо) относительно содержащегося в нем лица для каждого блока. Оставлять блоки с определенным уровнем доверия можно с помощью параметра порогового значения.
При этом мы не можем просто выбрать блоки с максимальным уровнем доверия, потому что картина может содержать несколько лиц.
Если один блок перекрывает другой и покрывает почти такую же область, то этот блок удаляется. Эти параметром можно управлять при инициализации сети.
В данном примере желтый блок будет удален. В основном, результатом работы P-Net являются блоки с низкой точностью. На примере ниже представлены реальные результаты работы P-Net:
Шаг 3: R-Net
R-Net выполняет отбор наиболее подходящих блоков, сформированных в результате работы P-Net, которые в группе наиболее вероятно являются лицом. R-Net имеет похожую на P-Net архитектуру. На этом этапе формируются полносвязные слои. Выходные данные R-Net также схожи с выходными данными из P-Net.
Шаг 4: O-Net
O-Net сеть — последняя часть MTCNN сети. В дополнение к последним двум сетям она формирует пять точек для каждого лица (глаза, нос, углы губ). Если эти точки полностью попадают в блок, то он определяется как наиболее вероятно содержащий лицо. Дополнительные точки отмечены синим:
В результате мы получаем финальный блок с указанием точности факта, что это – лицо. Если лицо не найдено, то мы получим нулевое количество блоков с лицом.
В среднем обработка такой сетью 1000 фотографий занимает на нашем сервере 6 минут.
Эту нейронную сеть мы неоднократно использовали в проверках, и она помогла нам в автоматическом режиме выявить аномалии среди фотографий наших клиентов.
Про использование FaceNet хотелось бы добавить, что если вместо Мона Лизы вы станете анализировать полотна Рембрандта, то результаты будут примерно как на изображении ниже, и вам придется разбирать весь список идентифицированных лиц:
Заключение
Приведенные гипотезы и подходы к тестированию демонстрируют, что с абсолютно любым набором данных можно выполнять интересные тесты и искать аномалии. Cейчас многие аудиторы пытаются развивать подобные практики, поэтому я хотел показать практические примеры использования компьютерного зрения и машинного обучения.
Отдельно хочу добавить, что как следующую гипотезу для тестирования мы рассматривали сравнение лиц (Face Recognition), но пока данные и специфика процессов не дают разумного основания для использования этой технологии в наших проверках.
В целом это все, что я хотел бы рассказать про наш путь в тестировании фотографий.
Желаю вам хорошей аналитики и размеченных данных!
* Пример кода взят из открытых источников.




