
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
А подробнее?
Месяц назад наша команда получила задачу примерно следующего содержания: запускается новый сайт онлайн-магазина, работающий на Битрикс, все товары в его базе лежат уже оформленные, однако фотографии для каждого товара заполнены не полностью (для каждого товара есть только детальное фото, а превью-фотографии и дополнительные изображения отсутствуют).
Для каждого товара нужно было сделать:
Скачать каждую детальную фотографию
Ресайзнуть ее в необходимое разрешение и обработать в зависимости от статуса товара (разрешение фотографии для люкс-товара больше, чем для товара из категории "масс-маркет")
Загрузить эту фотографию как дополнительную картинку
Ресайзнуть эту же фотографию в разрешение требуемое для трех типов превью-картинок товара и загрузить в поля превью-картинок
Выкачать для каждого товара дополнительные фотографии со старого сайта, и подогнать под разрешение основной фотографии (в рамках этого поста будем считать, что доступа к базе старого сайта нет)
Загрузить дополнительные фотографии в раздел дополнительных картинок
Так как мы общаемся в основном на языке питона, с Битриксом не знакомы, а написание и использование модулей на PHP это вообще для нас мрак, мы начали искать информацию как это сделать просто, желательно еще и на Python. Информации было мало, а точнее почти ноль, поэтому, для таких же любителей навалить жесткого пайтон-кода в таком случае, а не решать все вопросы встроенными инструментами и написана эта статья. Предпологается, что вы знаете как работать c Python и SQL, знаете библиотеки requests, bs4, sqlite3, если нет, то все равно информация будет полезной.
Шаг 1. Массово получаем ссылки на изображения с Битрикса
На этом этапе мы потратили больше всего времени, потому что не заметили одну маленькую кнопочку, которая позволяет намного упростить выкачку изображений и не заниматься написанием парсеров, которые эмулируют сессию и так далее.
Первое, что нужно знать: для того, чтоб скачать изображение с помощью питона да и просто скачать нужно получить прямую ссылку на это изображение. Это можно сделать пропарсив карточку товара в Битриксе, а можно просто (как оказалось) скачать таблицу с соответствием ID товара и ссылкой на детальное изображение.
Для этого идем в Контент > Каталог > Каталог товаров > Элементы

Видите шестеренку, выделенную на фото? Жмем на нее и настраиваем поля, которые будут отображены в таблице в зависимости от вашей задачи.

Для конкретно нашей задачи нам нужна была только детальная картинка, но в зависимости от вашей настройки могут отличаться.
Нажимаем кнопку "Применить" и получаем вот такой прекрасный вид на таблицу наших товаров
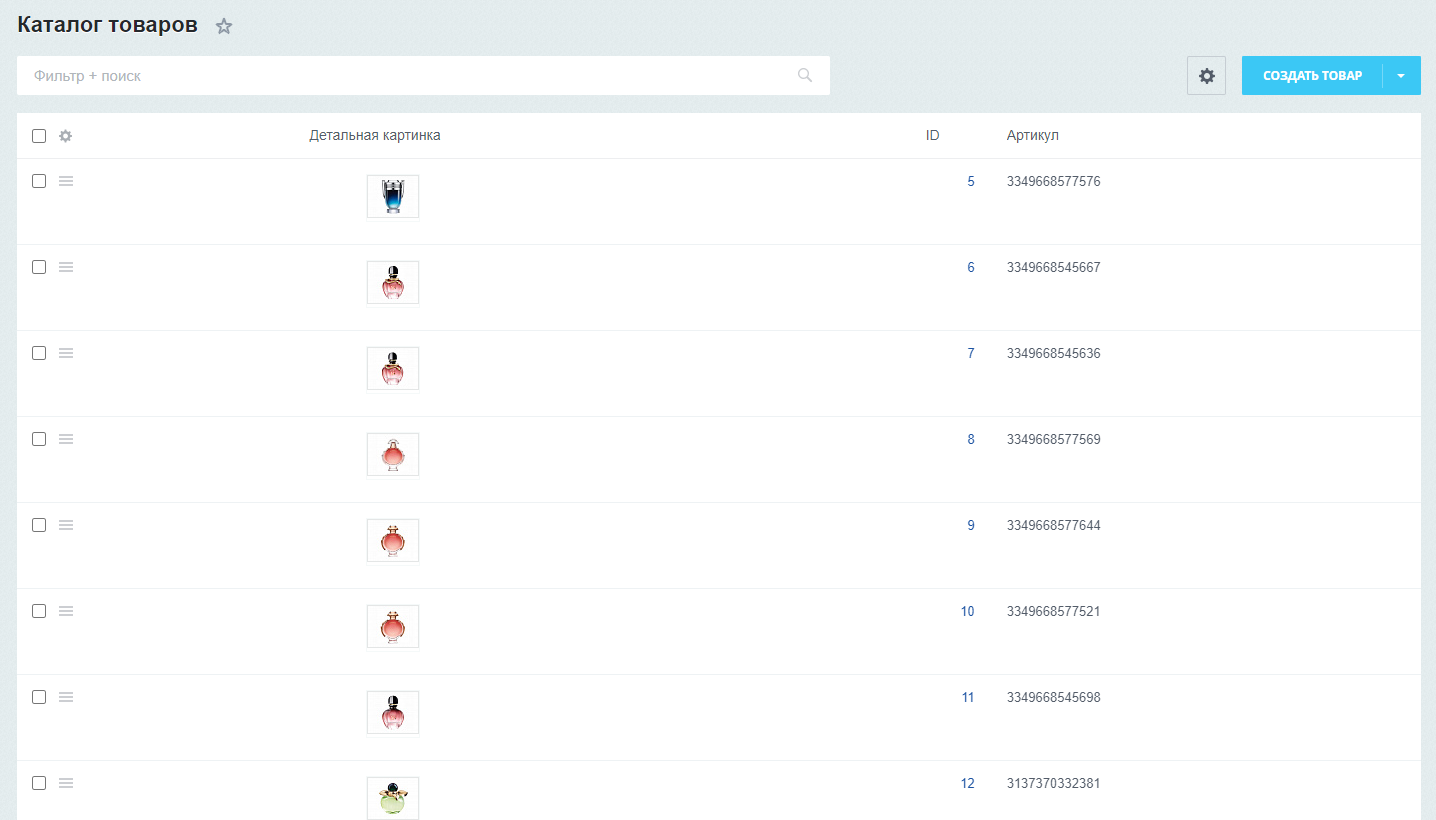
Теперь нам эту таблицу нужно скачать как обычную Excel таблицу. Для этого нажимаем вот эту кнопочку:

Поздравляем, вы загрузили полную Excel-таблицу со всеми товарами, их айдишниками, артикулами и ссылками на детальную фотографию.
И если вы уже приготовились расчехлять свой модуль для работы с эксель-таблицами в питоне, то спешу вас обломать и открыть скачанный файл в текстовом редакторе:

Оказывается, это обычный html-документ, что не может нас конечно не радовать. Было бы неплохо привести полученные данные в плюс-минус удобный формат, то есть загрузить это в локальную базу данных. Прежде чем что-то загружать в таблицу, ее необходимо создать:
(хочу обратить внимание, что этот шаг не является обязательным, и если вам удобно хранить данные в json, txt, этой же таблице, пожалуйста).
CREATE TABLE "elements" (
"id" INTEGER,
"article" INTEGER,
"detail" TEXT,
"additional" TEXT,
"prev1" TEXT,
"prev2" TEXT,
"prev3" TEXT,
"additional_handled" TEXT
);Что это за поля:
id - идентификатор товара в битриксе (логично)
article - его артикул
detail - ссылка на детальную фотографию, которую мы скачали
additional - через точку с запятой ссылки на дополнительные фотографии, которые будут получены при парсинге старого сайта
prev1 - имя файла обработанной картинки с для первой первью-картинки
prev2 - имя файла обработанной картинки с для второй первью-картинки
prev3 - имя файла обработанной картинки с для третьей первью-картинки
additional_handled - через точку с запятой имена файлов с обработанными дополнительными картинками
Вот теперь можно перегонять наш скачанный эксель в читаемую базу:
import sqlite3
from bs4 import BeautifulSoup
import lxml
# наша таблица лежит в файле detail_images.xls
with open('detail_images.xls', 'r', encoding='utf-8') as file:
""" важно не забыть указать кодировку при открытии файла, иначе
все считывание сломается"""
soup = BeautifulSoup(file.read(), features='lxml')
"""загружаем все, что мы считали с файла в соуп, не забывая указать features"""
table = soup.find('table')
"""находим таблицу в файле по тэгу"""
rows : list= table.find_all('tr')
""" в массиве rows лежат все ряды таблицы"""
database_connection = sqlite3.connect('base.db')
cursor = database_connection.cursor()
# открываем соединение с базой и получаем курсор
for row in rows[1:]: # срез нужен потому, что в нулевой строке таблицы лежат заголовки
cols : list = row.find_all('td')
# в массиве cols лежат ячейки таблицы в конкретном ряду row
detail = cols[0].text
element_id = int(cols[1].text)
try: article = int(cols[2].text); # артикулы иногда имеют свойство быть строчками или пустыми
except Exception: article = -1; # поэтому таким товарищам мы присваиваем значение -1, потому что это
# это невалидные товары, их мы не обрабатываем
cursor.execute("INSERT INTO elements VALUES ({}, {}, '{}', '', '', '', '', '')"\
.format(element_id, article, detail))
# загружаем в таблицу elements полученные нами значения
database_connection.commit()
database_connection.close()
Теперь если мы откроем базу данных, мы увидим столь отрадную картину:
Шаг 2. Парсинг картинок со старого сайта Битрикс
Описание этого шага скорее всего будет наименее полезным, так как парсеры — это штуки, пишущиеся для каждого конкретного сайта. Однако, из этого шага можно почерпнуть некоторые полезные идеи.
Товары на старом сайте будем искать по их артикулу. Думаю, что сайты, сделанные на Битриксе работают одинаково, следовательно эта стратегия будет применима ко всем таким сайтам.
В первую очередь импортируем библиотеку requests, добавим класс ошибки, которая вылетит в случае если товар по артикулу не найден, или таких два (да, бывают и такие случаи) )
import requests
class ArticleException(Exception):
passЗагоним в переменные нужную инфу:
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:45.0) Gecko/20100101 Firefox/45.0'}
oldSiteSearchUrlTemplate : str = "https://bma.kz/catalog/?search={}"
# в этой строке должно лежать значение адресной строки браузера при
# выполнении поиска на сайте, с параметрами поиска замененными на {}
old_site_domain = "https://bma.kz"
# просто адрес сайтаheaders - это заголовки GET-запроса, которые подпишут наши автоматические запросы как совсем не автоматические
Дальше соберем массив артикулов наших товаров
database_connection = sqlite3.connect('base.db')
cursor = database_connection.cursor()
cursor.execute("SELECT * FROM elements") # забираем все элементы из базы
articles = [x[1] for x in cursor.fetchall()] # сохраняем в массив только поле с
# индексом 1, то есть артикул Пробегая по массиву артикулов:
for article in articles:
response = requests.get(oldSiteSearchUrlTemplate.format(article),
headers = headers)
# запрашиваем поисковую выдачу по артикулу, подставляя его в шаблон
# адреса поисковой выдачи на сайте
response_soap = BeautifulSoup(response.text, features='lxml')
try:
elementDivs = response_soap.find_all("div",
{'class' : "cata-list-item"})
# находим все элементы класса cata-list-item
# элементы этого класса — карточки товаров, которые выдаются вам
# когда вы выполняете поисковой запрос
print(len(elementDivs), end = '\t')
if len(elementDivs) == 1:
# если такой элемент ровно один, то тогда у нас все классно
# и одному артикулу соответствует один товар
elementDiv = elementDivs[0]
url = elementDiv.find('a')['href']
# выгружаем из этого элемента ссылку на карточку товара
response = requests.get(old_site_domain + url, headers = headers)
response_soap = BeautifulSoup(response.text, features = 'lxml')
# делаем запрос к карточке товара
dop_photo = response_soap.find('div', {'class' : 'cata-d-dopphoto'})
# ищем на полученной странице все элементы класса
# cata-d-dopphoto: это контейнер для дополнительных фотографий
dop_photo_containers = dop_photo.find_all('img')
# из этого контейнера вылавливаем все элементы с тегом картинки
additional_photo_urls = ';'.join(
[old_site_domain + i['src'] for i in dop_photo_containers]
)
# а вот уже из этих элементов вытягиваем свойтво src
# в котором лежит ссылка на нужную нам картинку,
# формируем через точку с запятой строчку
cursor.execute("UPDATE elements WHERE article={} SET additional='{}'".format(article, additional_photo_urls))
database_connection.commit()
# заливаем ее в базу для дальнейших экзекуций
else:
raise ArticleException
# если у нас все не классно и по одному артикулу вы нашли несколько товаров
# не стесняемся выкидывать
except ArticleException: # а затем и обрабатывать ошибку
continue
except Exception:
continue
database_connection.close()Хочу снова обратить ваше внимание, что конкретные имена классов могут отличаться. Смысл вышенаписанного в описании стратегии с помощью которой вы можете эти данные выкачать.
Шаг 3. Обработка картинок
Подробного описания обработки картинок приводить не буду, не то получится либо краткий самоучитель по PIL, либо бесполезное описание кода под одну задачу. Обозначу только главный верстовой столб, который может быть вам полезен:
PIL может работать только с изображениями, уже скачанными на жесткий диск, так что вам нужна функция, которая будет эти изображения скачивать.
def load_image(url : str, temporary_path : str, article : int) -> str:
# в temporary_path лежит адрес файла в который вы запишете скачанную картинку
try:
p = requests.get(url)
out = open(temporary_path, "wb")
out.write(p.content)
out.close()
return temporary_path
except Exception as e:
with open("Exceptions.txt", 'a', encoding = 'utf-8') as file:
file.write("{}\n".format(article))
return "ERROR"Пробегаетесь по базе данных -> получаете из нее URL-ки картинок -> скачиваете картинки -> обрабатываете их под свои задачи -> сохраняете с таким именем, которое сможете однозначно сопоставить с товаром и местом в карточке, куда эту картинку нужно загрузить -> profit.
Шаг 4. Загрузка обработанных картинок на сервер.
Все бы было клубнично-шоколадно в этой жизни, если бы загруженные через инструменты Битрикса картинки лежали бы на сервере с именами, которые были изначально прописаны у этих файлов. Но все не так просто).
Для начала фотографии нужно хоть в каком-то виде загрузить на сервер. Для этого идем Контент > Структура сайта > Медиабиблиотека > Изображения
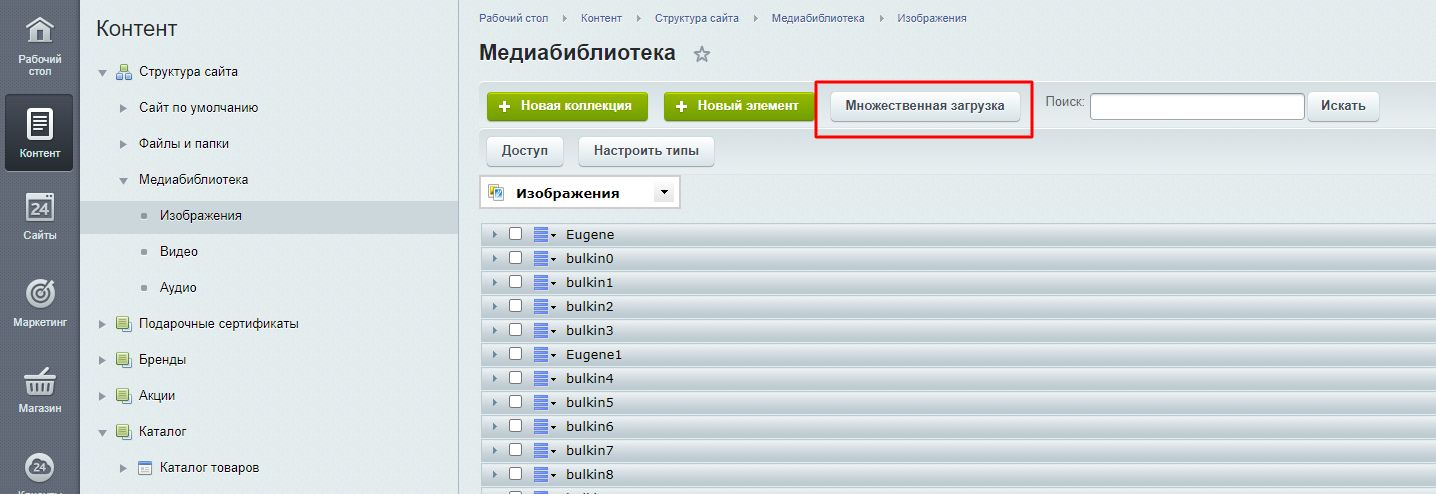
И с помощью элемента множественная загрузка загружаем все наши фотографии.
Попробуем открыть одну из загруженных фотографий.
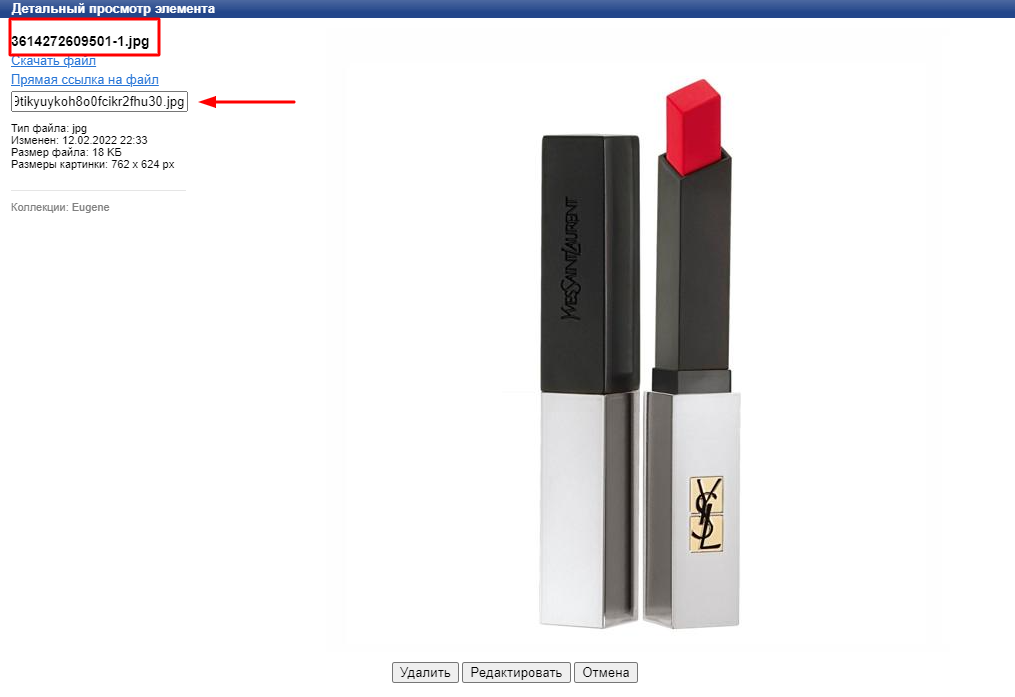
В прямоугольнике выделено имя файла, с которым он лежал в нашей файловой системе компьютера, а стрелочкой показано имя файла на сервере. На следующем этапе нужно сопоставить адреса файлов на сервере с товарами в карточки которых эти файлы нужно подгружать.
Шаг 5. Сопоставление имен файлов
На помощь нам в этом нелегком деле приходит возможность обращаться к базе данных Битрикса напрямую через встроенные инструменты. Для этого идем:
Настройки > Инструменты > SQL запрос и в поле запроса пишем
SELECT * FROM b_fileЧто вернет нам такой запрос? Таблицу с полными данными о файлах в файловой системе Битрикса. Выглядит это так:

В настройке "На странице" выберите "Все", подождите пару минут пока у вас прогрузится страница с полной базой и сохраните эту страницу как html файл.
Вот этот код поможет вам выкачать данные из таблицы
with open('SQL_response.html', 'r', encoding='utf-8') as file:
# в SQL_response.html лежит скачанная ранее страница
soap = BeautifulSoup(file.read(), features='lxml')
print("soap readed")
rows = soap.find_all('tr', {'class' : 'adm-list-table-row'})
# rows - массив строчек в таблице, adm-list-table-row это класс строки
b = len(rows)
for i in range(len(rows)):
print("{}% \t {}/{}".format(int(i/b * 100), i, b), end = '\r')
row = rows[i]
values = row.find_all('td')
subdir = values[7].text
filename = values[8].text
originalname = values[9].textИтого:
originalname - имя файла в вашей старой файловой системе
filename - имя файла на сервере
subdir - имя субдиректории в которой этот файл на сервере лежит
Общий адрес файла выглядит так:
/uploads/$subdir/$filename
Поздравляю, вы получили адреса всех загруженных файлов
Шаг 6-ой и последний. Загрузка фотографий в карточки.
Для каждой карточки товара в Битриксе работает следующая модель: каждая картинка в этой карточке задается свойством в этой карточке. Если это объяснение не совсем понятно, сейчас по ходу разберемся.
Давайте посмотрим на PHP код который обновляет картинки в конкретной карточке:
if (CModule::IncludeModule("iblock")) {
$el = new CIBlockElement;
$PRODUCT_ID = 15;
$tmpFilePath=$_SERVER['DOCUMENT_ROOT']."/upload/medialibrary/84e/jwhfc3nj1z5nqtkld4myyno74s97z45h.jpg";
$arFile=array("VALUE" => \CFile::MakeFileArray($tmpFilePath),"DESCRIPTION"=>"");
\CIBlockElement::SetPropertyValueCode($PRODUCT_ID, 'PICTURE_455_430', $arFile);
$tmpFilePath=$_SERVER['DOCUMENT_ROOT']."/upload/medialibrary/ef5/osdcpwdynvfvn7icp2bmxxp2ukajvuf8.jpg";
$arFile=array("VALUE" => \CFile::MakeFileArray($tmpFilePath),"DESCRIPTION"=>"");
\CIBlockElement::SetPropertyValueCode($PRODUCT_ID, 'PICTURE_682_430', $arFile);
$tmpFilePath=$_SERVER['DOCUMENT_ROOT']."/upload/medialibrary/fe5/lekdifxhamcxt2vedzjzb6c3oasidjo2.jpg";
$arFile=array("VALUE" => \CFile::MakeFileArray($tmpFilePath),"DESCRIPTION"=>"");
\CIBlockElement::SetPropertyValueCode($PRODUCT_ID, 'PICTURE_682_962', $arFile);
$tmpFilePath=$_SERVER['DOCUMENT_ROOT']."/upload/medialibrary/42c/0j5lhnu3px1ppmtf12x04l1tc888rpxw.jpg";
$arFiles[]=array("VALUE" => \CFile::MakeFileArray($tmpFilePath),"DESCRIPTION"=>"");
$tmpFilePath=$_SERVER['DOCUMENT_ROOT']."/upload/iblock/f50/xi47bkmj83qpm0jg6z20ms8399uoazc1.jpg";
$arFiles[]=array("VALUE" => \CFile::MakeFileArray($tmpFilePath),"DESCRIPTION"=>"");
$tmpFilePath=$_SERVER['DOCUMENT_ROOT']."/upload/iblock/a38/knzilyxmibfjlozrr40dhnjxieir8z4i.jpg";
$arFiles[]=array("VALUE" => \CFile::MakeFileArray($tmpFilePath),"DESCRIPTION"=>"");
\CIBlockElement::SetPropertyValueCode($PRODUCT_ID, 'UF_ADDPHOTO', $arFiles);
$arFiles = array();
}Мало что понятно. Понимать это и не нужно, мы сами до конца не поняли. Теперь давайте по порядку:
if (CModule::IncludeModule("iblock")) {
$el = new CIBlockElement;
$PRODUCT_ID = 15;В переменной $PRODUCT_ID лежит ID товара в Битриксе. Думаю это понятно
$tmpFilePath=$_SERVER['DOCUMENT_ROOT']."/upload/medialibrary/84e/jwhfc3nj1z5nqtkld4myyno74s97z45h.jpg";
$arFile=array("VALUE" => \CFile::MakeFileArray($tmpFilePath),"DESCRIPTION"=>"");
\CIBlockElement::SetPropertyValueCode($PRODUCT_ID, 'PICTURE_455_430', $arFile);В переменной $tmpFilePath лежит адрес файла для первой превью-картинки.
Затем он закидывается в массив $arFile.
Массив $arFile передается в свойство 'PICTURE_455_430' элементу с ID = $PRODUCT_ID
Аналогичные два блока снизу загружают файлы второй и третьей превью-картинок в свойства PICTURE_682_430 и PICTURE_682_962 соответственно
Затем для каждой дополнительной фотографии (а их может быть переменное количество) пишется такой код:
$tmpFilePath=$_SERVER['DOCUMENT_ROOT']."/upload/medialibrary/42c/0j5lhnu3px1ppmtf12x04l1tc888rpxw.jpg";
$arFiles[]=array("VALUE" => \CFile::MakeFileArray($tmpFilePath),"DESCRIPTION"=>"");Затем один раз прописывается
\CIBlockElement::SetPropertyValueCode($PRODUCT_ID, 'UF_ADDPHOTO', $arFiles);Эта строчка присваивает свойству UF_ADDPHOTO значение $arFiles.
$arFiles = array();
}после этого очищаем массив $arFiles и закрываем блок кода.
Вот по таким правилам, подставляя нужные айдишники и адреса файлов нужно с помощью питона сформировать код для всех товаров в магазине (можно делать это частями, но по наблюдениям, Битрикс хорошо справляется с обработкой кода на 2000 элементов за раз).
Этот PHP код будет у вас занимать примерно 40000 строк. И для того чтобы его выполнить идем:
Настройки > Инструменты > Командная PHP-строка
И вставляем эту огромную кучу говнокода туда. Главное, не забудьте выключить подсветку кода, она очень сильно влияет на производительность, и с подсветкой код на 2000 элементов скорее всего (точно) уронит вам сайт :)
Небольшой ответ на возможную критику этого шага:
В процессе работы над проектом мы открыли более элегантный способ обновлять свойства товаров, загружая CSV таблицу через встроенные средства Битрикса. Однако, этот способ уже достаточно хорошо расписан в других источниках, к тому же занимает по ощущениям чуть больше времени чем вышеописанный :)
В заключение
Мы открыты к критике в комментариях, и даже надеемся на то, что эксперты укажут нам более простой путь для выполнения вышеописанных задач, потому что дополнительные работы по этому проекту предполагают примерно схожие действия, так что очень просим экспертов по Битрику присоединиться к дискуссии :-)
Ваша, room304




