
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!
Меня зовут Паша Мягков, я frontend tech lead в команде монетизации Учи.ру. Несколько месяцев назад рост команды и задач привел нас к тому, что привычные рабочие процессы перестали отвечать нашим потребностям. Болезнь роста затронула прозрачность разработки, планирование и workflow. В этой статье я расскажу, как в рамках одной быстро выросшей команды нам удалось наладить процессы.
С увеличением объема работы разработка становилась менее и менее прозрачной. Часть требований к большим фичам с множеством компонентов и зависимостей в микросервисной архитектуре просто терялась, из-за чего разработка затягивалась. Продолжать жить так дальше было нельзя, поэтому мы кардинально изменили подход к работе. Наше решение не претендует на уникальность, но именно оно помогло нам справиться с увеличившимся потоком входящих задач качественно и вовремя.

К налаженному процессу разработки в условиях возросшего объема работ мы пришли не сразу. Каждый раз мы решали самую горящую проблему, а затем переходили к следующей, учитывая особенности нашей команды и подбирая инструменты под себя. От первого самого простого шага до последней вехи мы эволюционировали постепенно: уже прошли путь в четыре этапа, сейчас движемся к пятому.
Этап 1. Внезапный хаос
Около десяти месяцев назад из-за относительно низкого трафика мы занимались технической разработкой — рефакторингом и подобным. В процессе поняли, что без создания нового сервиса сделать качественные изменения не получится. Но никаких продуктовых требований по этим изменениям не было, поэтому писали весь концепт и продумали реализацию сами.
Из-за такой большой степени неопределенности команда даже не заводила в Jira примерно 75% задач. Вместе с тем команда быстро росла, росло и количество задач на новые сложные фичи. Все это привело к тому, что в один момент мы перестали понимать, сколько вообще задач находится в разработке, что осталось сделать, а предсказать, когда закончится разработка этого текущего проекта, стало невозможно. Состояние дел в Jira было максимально неинформативным. Продолжать в том же духе было невозможно.
Как это ни прозаично, упорядочить работу на этом этапе нам помогло простое решение: заводить задачи. Мы начали с того, что завели вообще все задачи по проекту. Прописали их настолько подробно, насколько было возможно. Этот первый шаг положил начало исправлению ситуации.
Этап 2. Темные времена
Тьма задач
Как только мы начали заводить задачи, таким образом выбравшись из хаоса, быстро поняли, что заводить их бесконтрольно — бесполезно, сильного прироста понимания процесса не происходит. Фич в разработке было много, по каждой — несколько задач, соответственно, бэклог спринта и общий бэклог полнились ворохом разрозненных тикетов, которые было сложно глазом объединить во что-то осмысленное. Быстро понять, что же нам осталось сделать по-прежнему не удавалось.
Чтобы вернуть себе представление об объеме работы, мы попробовали скакать с другого конца: выявляли крупные куски функционала, требующие разработки. Это могло быть какое-то осмысленное техническое улучшение или же продуктовый пользовательский сценарий. Для таких задач в Jira есть отдельный тип тикетов — User Story. Тикеты зеленые, поэтому далее я буду называть их именно по этому признаку. Наполнив сначала спринт, а потом и общий бэклог такими задачами, мы приступили к их декомпозиции, используя механизм подзадач в таск-трекере. Таким образом, весь спектр планируемых работ по всем направлениям (бэки, фронты, тестировщики, девопсы) оставался сгруппированным в зеленом тикете в виде удобного списка.

Этот шаг преобразил процесс и сделал его прозрачным. Теперь, взглянув на доску, можно понять, на каком этапе находится разработка и сколько еще осталось сделать.
Призрачное тестирование
Вместе с тем остро встал вопрос, как учитывать тестирование и выкатку. Ответа на него не было, поэтому каждый поступал по-разному:
включал задачи на тестирование и выкатку в задачи на разработку;
заводил их отдельными задачами;
вообще не учитывал (поэтому что-то вообще ускользало от тестирования).
Более того, мы не знали, что тестировать. Если с тестированием фикса бага все просто, то с тестированием крупной фичи возникали вопросы. Как ее тестировать? Что конкретно тестировать? А как делать регресс? Делать полный регресс или неполный?
Для начала мы стали заводить все даже самые мелкие задачки на тестирование и выкатку внутри тех же самых User Story. С ними картинка становилась все более полной.
Затем в контексте тестирования мы начали заводить тест-кейсы, сначала просто в табличке Google Sheets. С тестировщиками обсуждали, какие тест-кейсы нам нужно пройти в рамках тестирования каждой конкретной User Story.
Так мы перешли к достаточно логичной и предсказуемой группировке задач. В «пирамиде Маслоу» команды разработки мы закрыли базовые потребности. Это позволило нам всегда видеть скоуп работы, выполненные задачи, задачи в работе и то, что еще предстоит сделать. И главное — сосредоточиться на разработке. Следствие этого — взрывной рост скорости работы команды. Так начался…
Этап 3. Промышленная революция
Ответив на самые базовые вопросы, мы приступили к решению проблем следующего уровня:
связать код с задачами;
автоматизировать процессы;
ускорить тестирование;
придумать удобное решение для хранения кода.
Связь кода и задач
Как связать код с задачей? Что мы считаем релизами и как они связаны с выкатками? Деплой должен быть кумулятивным или мы выкатываем по одной задаче? Мы ответили на эти вопросы достаточно прозаично. Решили строить процесс вокруг релизных веток в Git и выделили несколько принципов.
Все релизные ветки начинаются с префикса release- и содержат в себе номер зеленой задачи, например `release-MTZ-120`. Именно по этому критерию скрипты деплоя могут определить, что это ветку нужно выкатывать на тестовый стенд автоматически.
Ветки каждой подзадачи начинаются с номера задачи и содержат краткое описание того, что нужно сделать. Пример: `MTZ-121-apple-pay`. Это помогает по сырому логу несмёрженных рабочих веток понять, что находится в разработке.
Все задачи проходят Pull Request (PR). По окончании разработки каждой задачи создается PR в базовую релизную ветку. Этим механизмом мы опционально пользовались и раньше, но сейчас это обязательное условие. Мне кажется, это важно: позволяет расширять владение кодом — когда каждый член команды читает весь код проекта, это сильно помогает становиться интероперабельными, да и обучение происходит быстрей.

Как минимум, эта формализация дала гораздо больше ощущения контроля. В любой момент времени можно понять, во-первых, что нужно делать, во-вторых, куда нужно катить, к какой задаче привязывать. Разработка стала понятнее и для менеджеров, и для разработчиков. Хотя в этом есть и минус: количество обязательных действий у разработчиков увеличилось, а дополнительную работу не любит никто.
Автоматизация
Члены команды все еще иногда забывали заводить в Jira мелкие задачи. Это накладывалось на то, что и команды разработки, и тестирования забывали эти задачки двигать на доске: привычка работать с ними еще не закрепилась.
Чтобы решить эту проблему, нужно было минимизировать ручные манипуляции. На этом этапе мы сделали первые шаги автоматизации внутри Jira.
За последние пару лет в Jira появились хорошие возможности для автоматизации. Мы воспользовались несколькими фичами:
Automation
Позволяет настроить любые автоматизации. Например, можно настроить создание сразу несколько подзадач при создании зеленого тикета. При этом статус группирующей задачи смотрел на статусы вложенных: например, когда все подзадачи становились сделаны, зеленый тикет тоже помечался как сделанный.
Интеграция Jira и GitHub
При создании pull request, название которого начинается с идентификатора задачи, Jira автоматически привязывает pull request к задаче и переводит ее в статус code review. А после мержа — переводит ее дальше по доске.
Ускорение тестирования
Объективно было неудобно работать с Google табличкой в контексте тест-кейсов. Мы начали думать, как это исправить и как ускорить тестирование.
Во-первых, начали заводить тест-кейсы в автоматизированной среде Qase. В ней можно выбрать, какие тест-кейсы релиз должен пройти. Во-вторых, начали писать автоматизированные тесты, о которых расскажут коллеги в одной из следующих статей.
Хранение кода
Мы начали задумываться, как улучшить систему хранения кода наших приложений, тесно связанных друг с другом. Речь в первую очередь о приложении payments, которое видит клиент, и приложении для администраторов, которые имеют общий функционал и работают с общими сущностями. Как эти приложения будет удобнее менеджерить: по отдельности или совместно?
Принято решение перевезти код приложений на фронтенде в монорепозиторий.
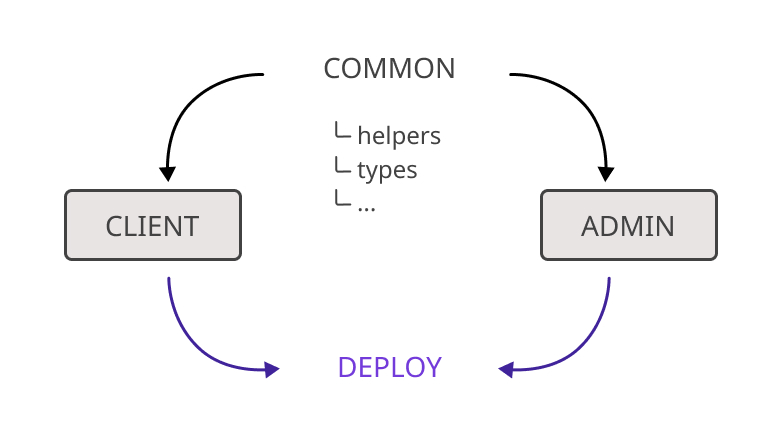
Клиентское и админское приложения лежат в одном репозитории. В отдельной папке хранятся общие данные: хелперы, конфиги, типизация. Оба проекта ее используют. Таким образом мы уверены, что код не дублируется: если кто-то сделал фикс проблемы в одном месте, она фиксится одновременно и в другом связанном приложении.
Теперь на этом этапе, который я назвал «Промышленная революция», у нас уже были отстроены основные жизненно важные процессы:
разрабатываем предсказуемо и стабильно;
задачи заводятся и двигаются по доске;
к задачам привязывается код;
релизы понятны;
тестирование наладилось.
Так или в похожих рамках работают многие команды. На этом в целом можно было бы остановиться. Но мы решили идти дальше.
Этап 4. Космическая программа
Мы начинаем строить реальный космолет. И на этом этапе, естественно, возникают проблемы.
Сборка и выкатка
Исторически вся сборка в Учи.ру происходила в кастомном интерфейсе к HashiCorp Nomad под названием Shaman. Он позволяет деплоить самостоятельно, об удобстве этого метода я писал ранее.
При работе с монолитом, Shaman облегчал работу. Когда мы начали расползаться по микросервисам, сборка новых сервисов была перенесена на GitHub Actions. Стало неудобно работать в двух системах: одна для сборки, а вторая для выкатки. Количество манипуляций, которые нужно было совершить, увеличилось. Мы начали думать, что нужно перенести все кнопки в космическом корабле на одну панель.
Такой панелью мы определили GitHub. Сейчас мы активно пилим экшены и workflow для GitHub. В результате мы катим релизную ветку на шот (стейдж) автоматом. В продакшен же катим по кнопке — запускаем workflow в GitHub, потому что, на мой взгляд, еще не доросли.
В итоге workflow выглядит так:

При мердже задач в релизную ветку, выкатка происходит по кнопке из GitHub. А на шот у нас деплоится автоматически при мерже, Pull Request из рабочей ветки в релизную. То есть релизная ветка всегда содержит в себе код, который потенциально открывает всю фичу. При этом код автоматически уходит на тестирование.
Автоматизация тестов
Автотесты при запуске идут в API Qase: создают сущности, необходимые для новых тестов, запускают и проверяют, пройдено ли тестирование.
Мы начинаем задаваться вопросами: как смотреть, что протестировано руками, а что в рамках запуска автотестов? Пока мы не определили, как это будет работать лучше всего для нашей команды. С удовольствием прочту, как решали такой же вопрос.
Итак, мы построили приборную панель космического корабля, немного полетали, но, естественно, кое-что пошло не так. Например, произошли пертурбации в команде, мы остались на время без автотестировщика, поэтому развитие в этом направлении приостановилось. Но приборная панель работает и у нас есть планы выйти на следующий уровень.
Этап 5. Светлое будущее
Какими будут наши следующие шаги — открытый вопрос. Пока я вижу два направления работы, которые сделают нас чуть ближе к тому самому светлому будущему:
Подсадить бэкенд команды монетизации на автоматические выкатки. Конечно, сложность процессов разработки на бэкенде выше, чем на фронте. Но тем не менее, мы смогли бы прийти к такому формату взаимодействия, когда мы сможем шарить все наши workflow и лучше синхронизироваться.
Наладить более тесную интеграцию Jira, функционал которой оставляет еще большое поле для экспериментов.
Коллеги из команд, которые уже пришли в свое светлое будущее гладких процессов и прозрачной разработки, как у вас налажены аналогичные процессы?



