
Прежде чем перейти к статье, хочу вам представить, экономическую онлайн игру Brave Knights, в которой вы можете играть и зарабатывать. Регистируйтесь, играйте и зарабатывайте!

Привет, меня зовут Виктория, и я отвечаю за маркетинг в КРОК Облачные сервисы. Теперь мы регулярно проводим у себя облачные митапы. Я недавно попала на крутейшее выступление Дмитрия Аношина, который сейчас работает в Amazon, и хочу им поделиться.
У меня появилось стойкое ощущение, что крупные коммерческие компании решили собрать вообще все возможные данные в мире, до которых могут дотянуться. С одной стороны, это выливается в продвинутую аналитику, повышение продаж и привлекательность продуктов. С другой — данные стали настолько жирными и всеобъемлющими, что анекдоты про грузовики с CD-дисками уже давно обыденность.
Посмотрим, зачем может понадобиться миграция в облако, и что получила Amazon от переезда внутренней инфраструктуры на Redshift и NoSQL DynamoDB. Разберём разницу между концепциями SMP и MPP, ETL и ELT и попробуем понять, зачем нужны облака для больших данных.
Ну а если вы в курсе того, что происходило в индустрии в последние годы, то листайте сразу к конкретному кейсу. Заходите под кат, я подготовила конспект основных моментов выступления.
Телеметрия из каждой лампочки

Есть очень заметный тренд у крупных компаний на формирование комплексных экосистем вокруг своих пользователей. То есть ты проснулся, пошёл чистить зубы и параллельно проглядываешь новости в мультимедийном зеркале. Колонка Alexa включает бодрую музыку с утра и напоминает про сегодняшние встречи. Тут же ты заказываешь свежий кофе с доставкой на дом, так как старый уже на исходе. Садишься в машину, а там — снова Alexa, которая интегрирована с автомобильной мультимедийной системой и продолжает сопровождать в дороге. Плюс смарт-браслет, наушники, приложения в телефоне и тысячи других источников информации.
Это одновременно и немного пугающее будущее, которое стремительно наступает со всех сторон, попытка создать дополнительную ценность для конечного потребителя со стороны компаний. Согласитесь, круто, когда, например, по программе от Amazon «Key In-Car» ваши покупки вам доставят прямо в багажник автомобиля на стоянке. Я сейчас живу в Канаде, и подобные интеграции делают жизнь намного комфортнее. Для компании это тоже очень ценные данные с точки зрения таргетирования продаж, прогнозирования спроса, оптимизации логистики и прочего. Win-win.
Одна проблема. Как я уже говорил, есть стойкое ощущение, что компании часто собирают данные в избыточных масштабах в надежде монетизировать их в будущем. А это терабайты. Реально терабайты плохо структурированной информации, которая непрерывно льётся на серверы компании, пожирая сетевые, вычислительные и storage-ресурсы. Именно поэтому столь важной является проблема оптимальной утилизации ресурсов и обеспечения скорости вычислений. А ещё нужно дать бизнес-аналитикам нормальный интерфейс, который не потребует от них экспертных знаний в области построения облачной инфраструктуры. Поэтому многие крупные компании двинулись в сторону облаков.
There is no cloud

Облачные технологии — это тот ещё buzz-word, который всех изрядно достал. Нет, спору нет, он солидно выглядит в финансовых отчётах компании и на официальных презентациях. Тем не менее на уровне железа это всё те же старые добрые серверы, расположенные в дата-центрах по всему миру. Однако для «облачности» нужно нечто большее, чем просто удобная консоль виртуализации. Основная фишка облаков — полностью динамическое управление ресурсами и их автоматическое масштабирование при необходимости:
- Вычисление.
- Хранение.
- Сетевые ресурсы и транспорт.
- База данных.
Когда у вас есть подобная инфраструктура, вы намного более полно утилизируете имеющиеся у вас ресурсы, что при крупномасштабных бизнес-кейсах может выливаться в значительную экономию.
Для небольших компаний подобный подход тоже может быть очень привлекателен. Представьте, что вы планируете приобретение нового железа для своей инфраструктуры на будущий год. При этом вам очень сложно прогнозировать точную нагрузку, которая может колебаться от множества факторов. Например, ваш продукт совершенно внезапно становится дико популярным из-за удачной публикации на Хабре, на вас набегает целая толпа клиентов и дико разочаровывается, потому что вы не планировали такие пиковые нагрузки. А может быть и обратная ситуация, когда вы переоцениваете спрос, закупаете избыточные мощности и в итоге получаете простаивающее оборудование, которое фактически изымает из оборота компании столь необходимые деньги. Ставка исключительно на покупку железных мощностей — это почти всегда крайне инертный процесс, и он заведомо проигрывает в адаптивности на быстро меняющемся рынке.
Именно для таких ситуаций подходит частичная или полная миграция в облако, которое служит чем-то вроде конденсатора, сглаживающего пиковые всплески потребления. Или вообще полностью обеспечивает вас инфраструктурой.
Виды облаков

По сути, в зависимости от своей бизнес-модели компании обычно приходят к одной из трёх форм построения облачных систем. Небольшой бизнес обычно использует публичные облака и экономит на соответствующих специалистах, сосредотачиваясь на своём продукте. Особо крупные сами по себе похожи на множество отдельных компаний, связанных общей целью и брендом. Поэтому часто они строят приватные облака, достигая оптимальной утилизации ресурсов. Часть использует гибридные модели, которые позволяют обрабатывать особо чувствительные, защищённые законодательно данные локально и выносить на внешние облака второстепенные задачи. Pizza as a service:
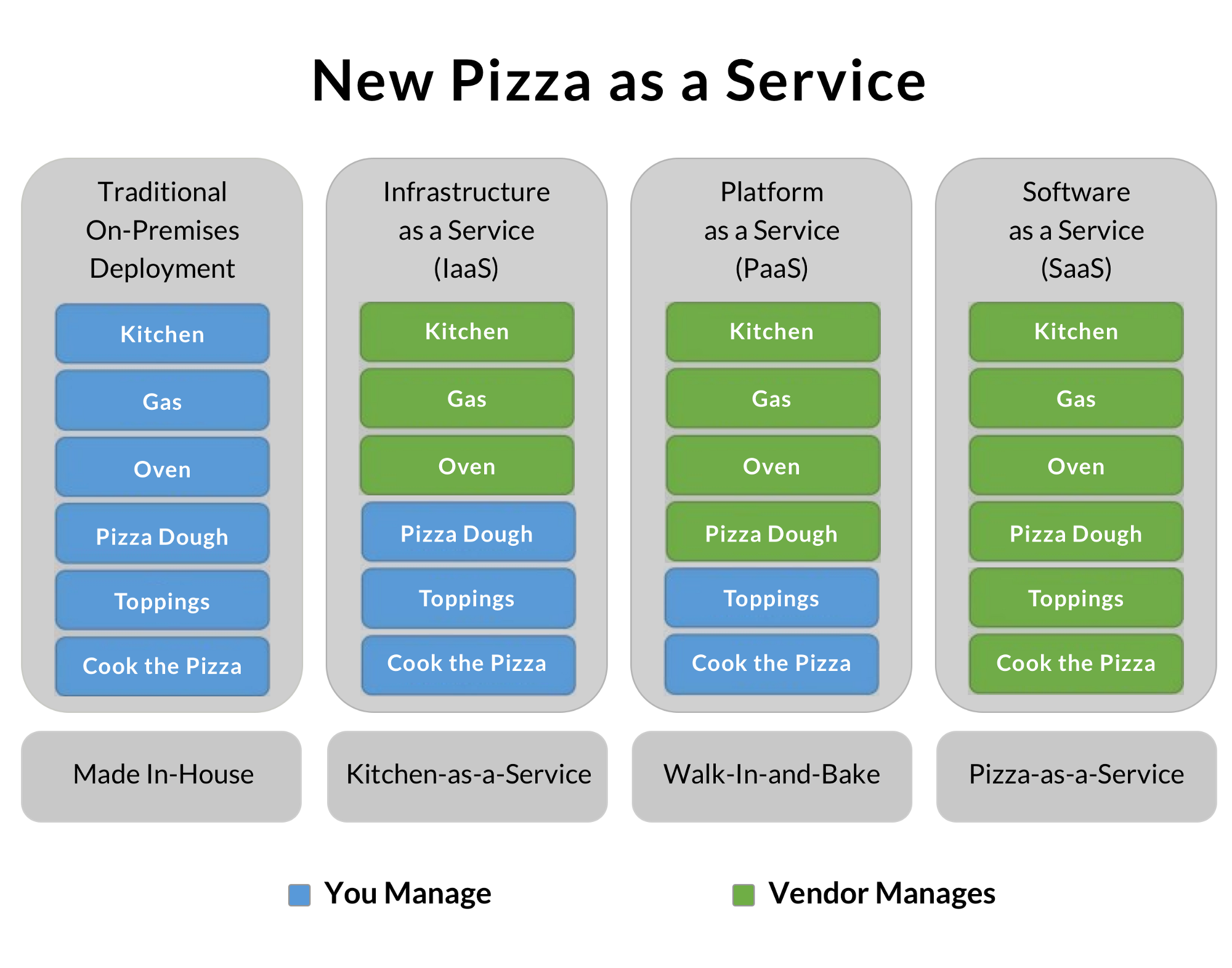
Мне всегда очень нравилась эта иллюстрация, которая хорошо показывает степень делегирования инфраструктурных задач вашей компании вендору.
Традиционный On-Premises-вариант — это пойти купить продуктов, разогреть духовку и приготовить пиццу самому. Идеально! Но нужно иметь всё оборудование, ингредиенты и прочее.
IaaS — это вариант аренды инфраструктуры. Вы арендовали кухню со всем оборудованием, принесли свои продукты и приготовили отличную пиццу. Отмывать духовку от жира будут специально обученные люди, а вам не нужно беспокоиться об остроте ножей и прочих мелочах.
PaaS — платформа как сервис. Сервис предоставляет вам какие-то дополнительные плюшки помимо голой инфраструктуры. Например, Amazon Redshift — как хранилище данных, что позволяет экономить на DBA и сосредоточиться на продукте. В нашем примере с пиццей это может быть, например, готовое сформованное тесто, которое остаётся только разморозить, намазать ароматным соусом, посыпать шампиньонами, ломтиками нежного бекона и тёртым пармезаном.
Финальный вариант — SaaS. В этом случае вы получаете максимально готовый продукт, на базе которого вы строите свой бизнес. Например, ведёте блог на базе чужой публичной платформы. В нашем примере это будет самый дорогой, но простой вариант заказа готовой пиццы на дом.
Данные на грузовиках. Snow-Mobile
Есть старый бородатый анекдот времён «нулевых» годов: «Бригада водителей многотоннажных грузовиков смогла доставить за ночь 100 000 компакт-дисков из Одессы в Киев. Тем самым они достигли скорости передачи данных в 2.43 терабайт в секунду на расстояние больше 500 км без применения дорогих кабелей».
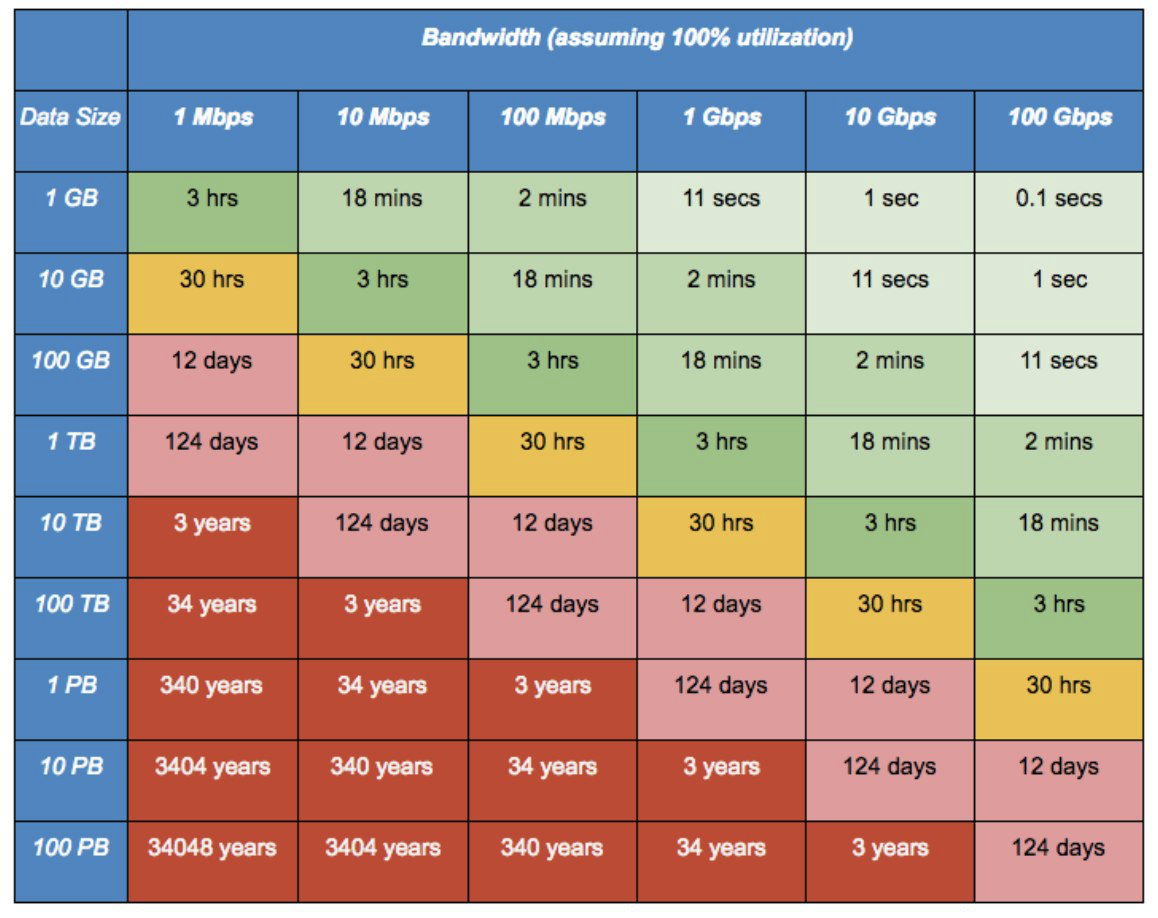
На тот момент это было просто шуткой. Однако с современными объёмами непрерывного потока фоточек с каждого мобильника, аудио-, видео- и прочей телеметрии она становится совсем несмешной и превращается в реальную проблему. Когда у вас нет прямого арендованного толстого оптического линка до дата-центра, переезд больших объёмов данных в облако может стать огромной проблемой. Тут на помощь приходят такие сервисы, как Snowball от Amazon.
Вам привозят такой вот брутальный защищённый чемоданчик, забитый 50 терабайтами скоростных дисков и 10-гигабитными сетевыми интерфейсами. Дальше вы подключаете его непосредственно к своему стораджу и сливаете все данные с максимальной скоростью. На случай кражи или других неприятностей данные покидают вашу серверную только в зашифрованном виде. В чемоданчике есть модуль TPM, а управление ключами шифрования происходит с помощью сервиса AWS Key Management Service (KMS). Ключи шифрования не хранятся на самом устройстве.
В особо запущенных случая можно вызвать Snowball Truck — мобильный дата-центр с ёмкостью в 100 петабайт. Когда масштабы данных приближаются к эксабайту, обычный 10-гигабитный коннект потребует 26 лет на трансфер данных. А такие белые грузовички смогут перетащить данные за шесть месяцев.
Переход Amazon с Oracle на Redshift
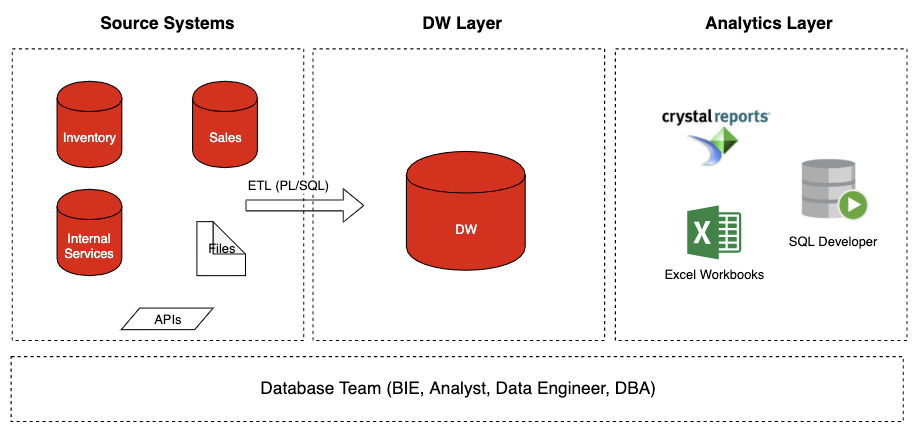
Что у нас было
Расскажу немного про тот кейс, с которым я работал в Amazon. У таких крупных торговых платформ, как Amazon, есть очень болезненный участок работы — Prime Days. Это пиковые дни продаж в Чёрную пятницу и рождественскую распродажу. В этот момент серверы плавятся под нагрузкой, склады переполнены погрузчиками, а логистика захлёбывается под непрерывным потоком товаров. Это очень важное время с точки зрения продаж, и каждый час простоя или недоступности сервиса обходится в колоссальные суммы убытков.
Проблема пришла со стороны Oracle DB. База данных просто перестала вывозить такой объём одновременных запросов, испытывая проблемы с масштабированием. Сайт практически складывался под натиском покупателей, а база данных становилась проблемой с точки зрения масштабирования.
После тщательной аналитики пришли к выводу, что традиционные SQL-базы не подходят в качестве бекэнда торговой площадки такого масштаба. Плюс Oracle ещё и крайне дорогой в плане лицензий и поддержки. В итоге было принято решение мигрировать на свою облачную платформу, в основе которой лежали Redshift и NoSQL DynamoDB.
DynamoDB был внутренней разработкой c синхронной репликацией между дата-центрами и крайне эффективным механизмом снижения избыточности данных, что позволило значительно сэкономить на их хранении. Очень важной фичей был Auto Scaling — динамический скейлинг БД под требуемый объём данных. Также была проработана отличная интеграция с Hadoop.
В чём же основная проблема традиционной БД?
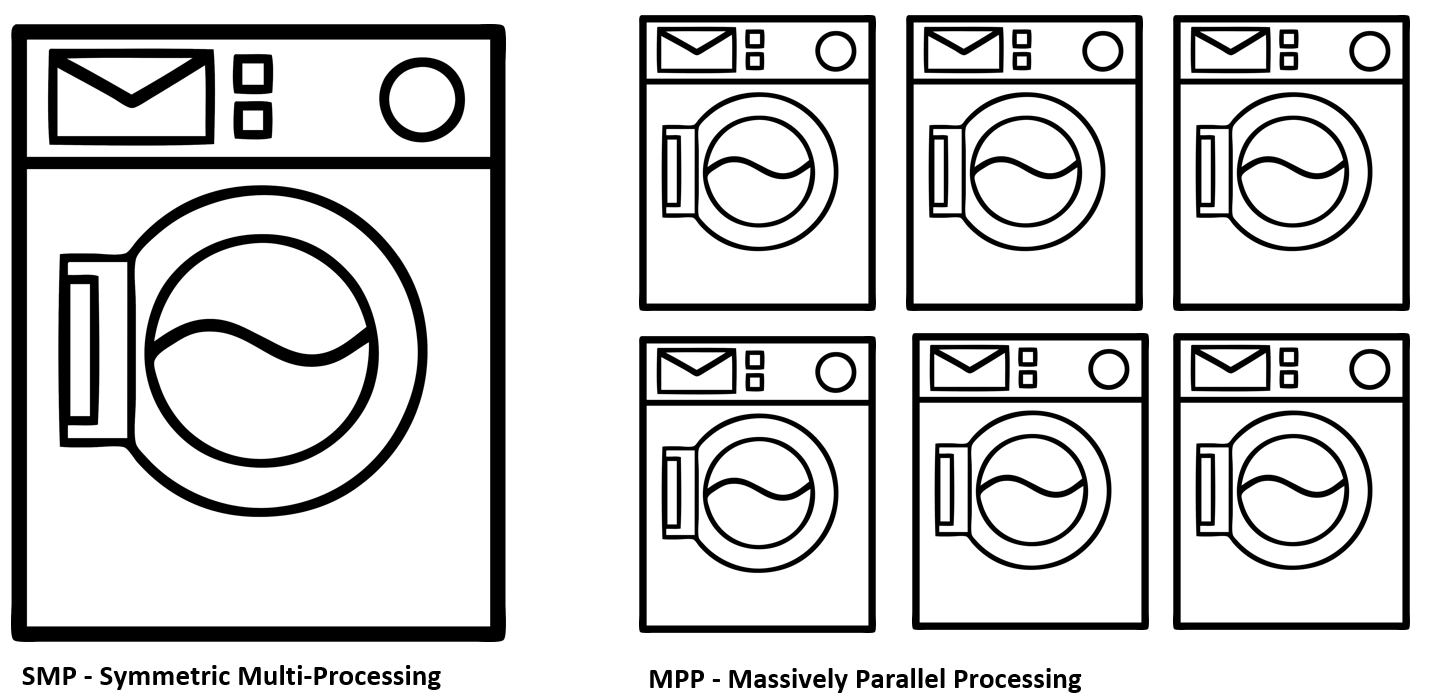
Проблема в том, что старый вариант с Oracle относится к SMP-архитектуре, которая предполагает только вертикальное масштабирование. То есть у вас есть мощная машина с определённой памятью, кучей быстрого стораджа, и все запросы так или иначе стекаются к ней. Это классическая модель Oracle, которая сфокусирована на поставке своих мощных отдельно стоящих серверов. При этом в компании особо не верили в облака, и параллельные вычисления не считались перспективным решением. А нам был нужен MPP — параллельная архитектура, которая позволяет размазать запрос на множество отдельных машин и быстрее обработать данные.
Есть ещё один важный момент — ETL vs ELT-подход к внесению данных в БД.
ETL — Extract -> Transform -> Load. То есть мы вначале получаем данные из наших источников, тщательно структурируем их и только после этого заливаем в наше хранилище. ELT-подход подразумевает заливку сырых шумных данных в хранилище и обработку уже на его стороне. В принципе RedShift поддерживает оба подхода, но у ELT есть преимущество: обращение к отфильтрованным данным происходит быстрее, ими проще манипулировать. Хотя при этом тратится больше ресурсов на первичный разбор сырой информации. Есть ещё один неочевидный момент. ETL снижает риски с точки зрения GDPR в европейском законодательстве, заблаговременно фильтруя чувствительную информацию до того, как она попадёт в общее хранилище. Это снижает риски несанкционированного доступа к данным. Основным инструментом для первичной обработки данных в новую архитектуру стал Matillion. Там уже есть приятный GUI, он отлично конфигурируется и уже поставляется в варианте, заточенном на Amazon RedShift. Благодаря ему получилось снизить порог входа. Теперь продакт-менеджеры могут сами в форме визуального конструктора конфигурировать входящие потоки данных без помощи наших дата-инженеров.
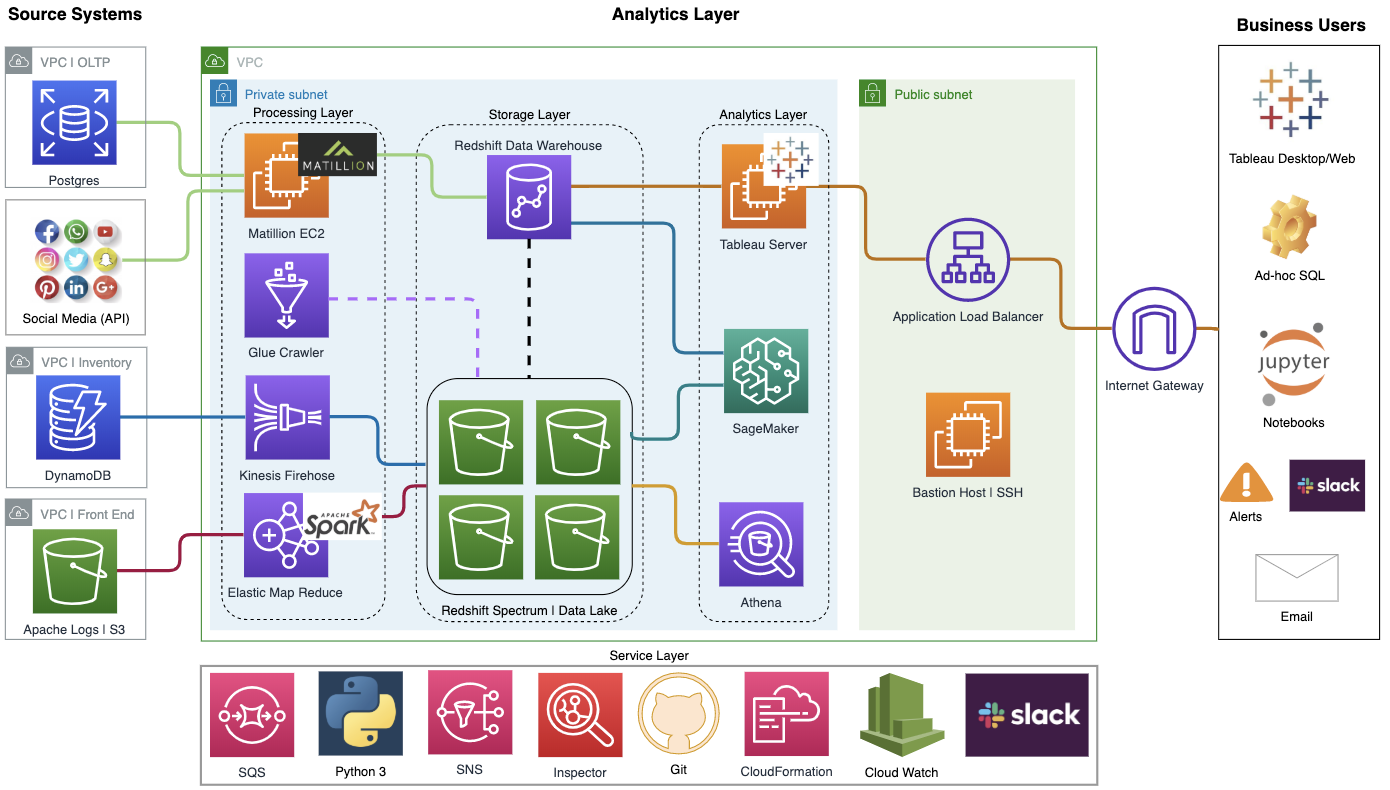
В итоге мы получили нужную нам гибкость, масштабирование и сглаживание пиковых нагрузок. Например, смогли решить задачу разгребания 50 ГБ логов веб-сервера в сутки для прогнозирования поведения посетителей.
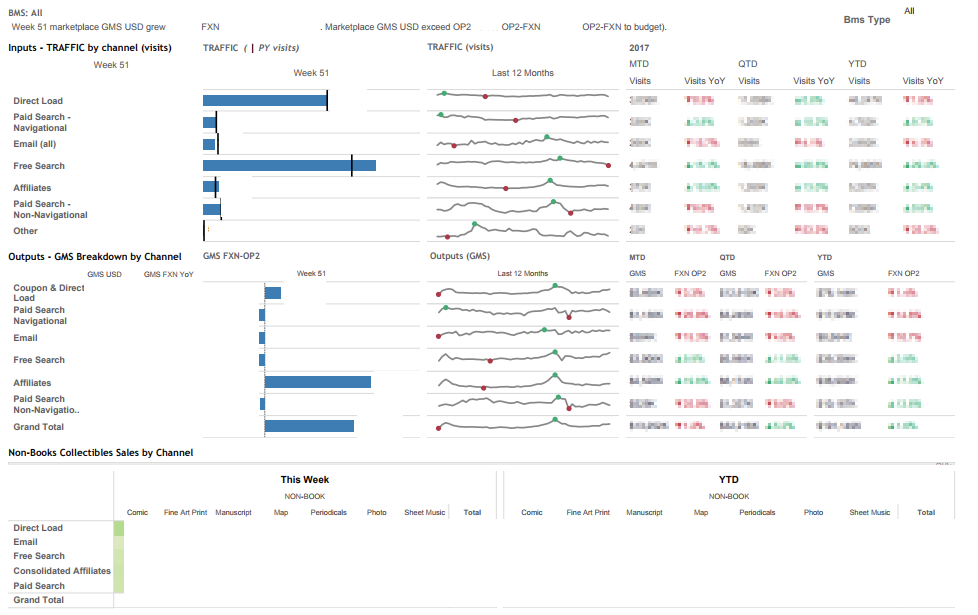
А ещё мы внедрили Tableau, что позволило перейти от плохо связанных таблиц в Excel к единым дашбордам, удобным для руководства.
И поясню ещё на всякий случай: есть Oracle OLTP (бекэнд) у магазина, есть Oracle DW — аналитическое хранилище данных. Проект был нацелен на обе вещи, но я рассказываю конкретно про Oracle DW! То есть приведённые диаграмма и описание — локальные, они касаются одной лишь команды Амазон. То же самое — про Tableau. Когда я говорю «мы внедрили Табло», имеется в виду локальный проект, так как в Амазоне всё разбито по командам, и каждый сам выбирает, что делать и что внедрять и использовать.
Облака, несмотря на несколько нездоровый хайп вокруг них, — уже текущая реальность. Скорее всего, большинство бизнес-проектов так или иначе будет строиться вокруг подобной инфраструктуры. Да, возможно, не каждой компании подойдут такие решения. Но планировать дальнейшее развитие стоит уже сейчас, иначе будет сложно быстро реагировать на стремительно меняющиеся параметры рынка и жёсткую конкуренцию.
Если кому интересна тема облачной аналитики и современных решений, заходите сюда. Я скидываю туда полезный контент.
Приходите к нам на митапы

У КРОК Облачные сервисы уже прошла целая серия выступлений отличных спикеров, например, темой одного митапа стало практическое использование сервисов AWS в жизни. На следующий год мы запланировали еще несколько ивентов, о них будем рассказывать подробно. Следите за событиями.

![[Личный опыт] Amazon vs Microsoft: чем отличается процесс собеседований в крупных ИТ-компаниях](/upload/resize_cache/iblock/cf7/105_70_0/cf7534b771bf8335172223116010c985.png "[Личный опыт] Amazon vs Microsoft: чем отличается процесс собеседований в крупных ИТ-компаниях")


