
Стремление уйти от ручного регрессионого тестирования — хороший повод внедрить автотесты. Вопрос, какие именно? Разработчики интерфейсов Наталья Стусь и Алексей Андросов вспомнили, как их команда прошла несколько итераций и построила тестирование фронтенда в Авто.ру на базе Jest и Puppeteer: юнит-тесты, тесты на отдельные React-компоненты, интеграционные тесты. Самое интересное из этого опыта — изолированное тестирование React-компонентов в браузере без Selenium Grid, Java и прочего.

Алексей:
— Для начала надо немного рассказать, что такое Авто.ру. Это сайт по продаже машинок. Там есть поиск, личный кабинет, автосервисы, запчасти, отзывы, кабинеты дилеров и многое другое. Авто.ру — очень большой проект, очень много кода. Весь код мы пишем в большой монорепе, потому что это все перемешивается. Одни и те же люди делают схожие задачи, например, для мобильных и десктопа. Получается много кода, и монорепа нам жизненно необходима. Вопрос — как ее тестировать?

У нас есть React и Node.js, который выполняет рендеринг на стороне сервера и запрашивает данные из бэкенда. Остались и небольшие кусочки на БЭМ.

Наталья:
— Мы начали думать в сторону автоматизации. Релизный цикл наших отдельных приложений включал в себя несколько шагов. Сначала фича разрабатывается программистом в отдельной ветке. После этого в этой же отдельной ветке фича тестируется ручными тестировщиками. Если все хорошо, задача попадает в релиз-кандидат. Если нет, то снова возвращаемся на итерацию разработки, снова тестируем. Пока тестировщик не скажет, что в этой фиче всё ок, она не попадет в релиз-кандидат.
После сборки релиза-кандидата идет ручной регресс — не всего Авто.ру, а только того пакета, который мы собираемся катить. Например, если мы собираемся катить декстопный веб, то идет ручной регресс десктопного веба. Это очень много тест-кейсов, которые проводятся вручную. Такой регресс занимал примерно один рабочий день одного ручного тестировщика.
Когда регресс пройден, происходит релиз. После этого релизная ветка вливается в мастер. На этом моменте мы как раз можем влить мастер-код, который мы протестировали только для десктопного веба, и этот код может сломать мобильный веб, например. Это проверяется не сразу, а только на следующем ручном регрессе — мобильного веба.

Естественно, самым больным местом в этом процессе был ручной регресс, который проводился очень долго. Все ручные тестировщики, естественно, устали проходить каждый день одно и то же. Поэтому мы решили все автоматизировать. Первое решение, которое было выполнено, — автотесты Selenium и Java, написанные отдельной командой. Это были end-to-end-тесты, e2e, которые тестировали все приложение целиком. Написали около 5 тысяч таких тестов. Чего мы в итоге добились?
Естественно, мы ускорили регресс. Автотесты проходят гораздо быстрее, чем это делает ручной тестировщик, где-то раз в 10 быстрее получилось. Соответственно, с ручных тестировщиков сняли рутинные действия, которые они выполняли каждый день. Найденные баги из автотестов проще воспроизводить. Просто перезапускаешь этот тест или смотришь по шагам, что он делает — в отличие от ручного тестировщика, который скажет: «Я что-то нажал, и все сломалось».
Обеспечили стабильность покрытия. У нас всегда запускается один и тот же run тестов — в отличие, опять же, от ручного тестирования, когда тестировщик может посчитать, что вот это место мы не трогали, и я его в этот раз проверять не буду. Мы добавили тесты на сравнение скриншотов, повысили точность тестирования UI — теперь проверяем расхождение в пару пикселей, которое тестировщик глазами не увидит. Всё благодаря скриншотным тестам.
Но были и минусы. Самой большой — для e2e-тестов нам нужно тестовое окружение, которое полностью соответствует проду. Его нужно всегда поддерживать в актуальном и рабочем состоянии. Для этого нужно практически столько же сил, сколько на поддержку стабильности прода. Естественно, мы не всегда можем себе это позволить. Поэтому у нас часто были ситуации, когда тестовое окружение лежит или где-то что-то сломано, и у нас падают тесты — хотя в самом фронтовом пакете проблем не было.
Еще эти тесты разрабатывает отдельная команда, у которой свои задачи, своя очередь в трекере задач, и новые фичи покрываются с некоторой задержкой. Они не могут сразу после релиза новой фичи прийти и тут же написать на нее автотесты. Поскольку тесты дорогие и их сложно писать и поддерживать, мы покрываем ими не все сценарии, а только самые критичные. При этом отдельная команда нужна, и у нее будут отдельные инструменты, отдельная инфраструктура, все свое. И разбор упавших тестов — тоже нетривиальная задача для ручных тестировщиков или для разработчиков. Покажу пару примеров.
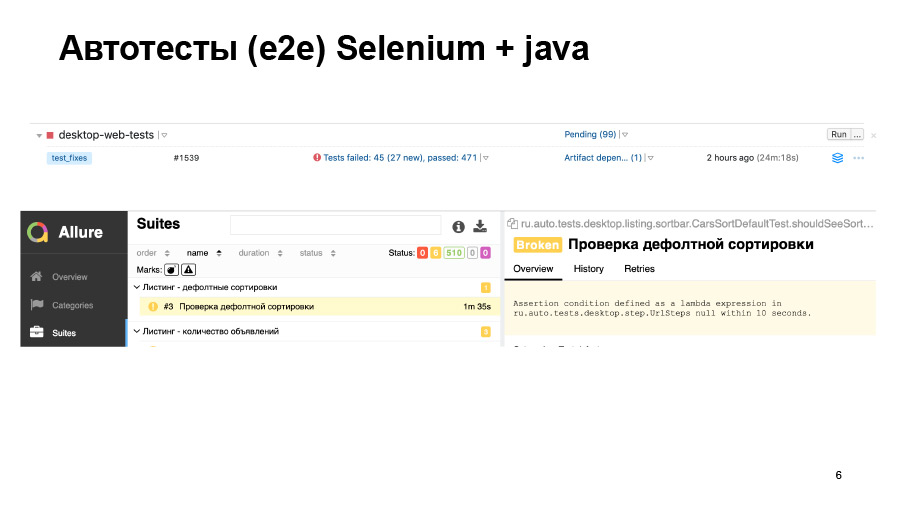
У нас есть run-тесты. 500 тестов прошло, из них сколько-то упало. Мы в отчете можем увидеть вот такую штуку. Тут тест просто не запустился, и не понятно, хорошо там всё или нет.
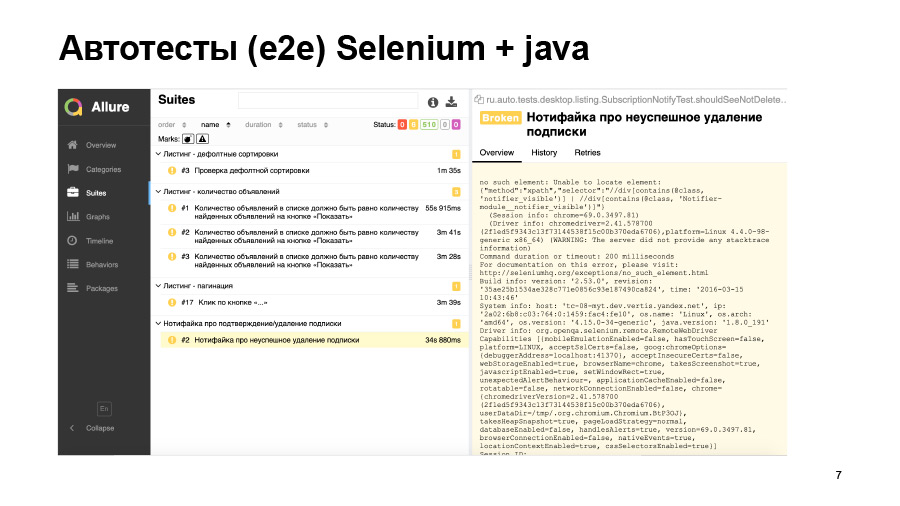
Еще один пример — тест запустился, но упал вот с такой ошибкой. Он не смог найти какой-то элемент на странице, но почему — мы не знаем. Либо этот элемент просто не появился, либо оказался не на той странице, либо поменялся локатор. Это все нужно идти и дебажить руками.
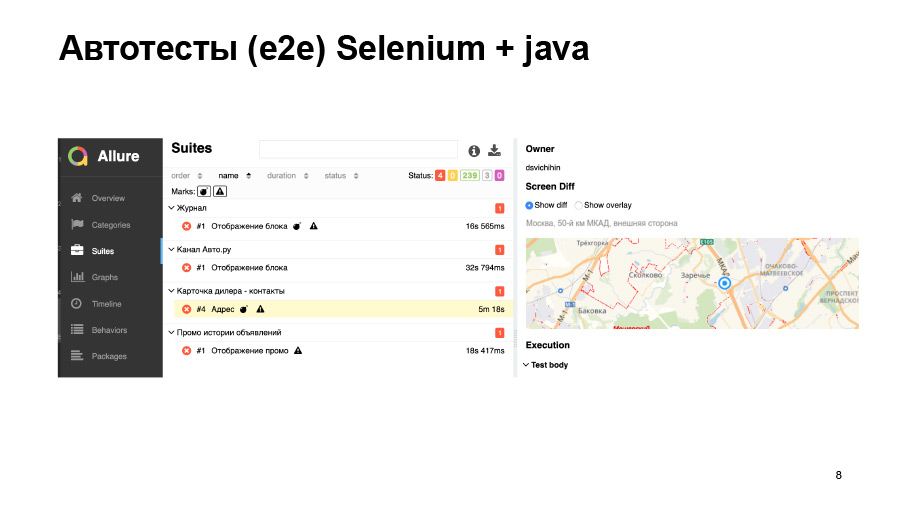
Скриншотные тесты тоже не всегда дают нам хорошую точность. Здесь мы загружаем какую-то карту, она чуть-чуть сдвинулась, у нас тест упал.

Мы попытались решить ряд этих проблем. Часть тестов мы стали запускать на проде — те, которые не задевают юзерских данных, не меняют ничего в базе. То есть мы на проде сделали отдельную машинку, которая смотрит в прод-окружение. Мы просто ставим новый пакет фронтенда и прогоняем там тесты. Прод, по крайней мере, стабильный.
Часть тестов мы перевели на моки, но у нас очень много разных бэкендов, разных API, и все это замокать — очень тяжелая задача, тем более для 5 тысяч тестов. Для этого был написан специальный сервис, который называется mockritsa, он помогает довольно легко сделать нужные моки для фронтенда и довольно легко в них проксироваться.
Также нам пришлось купить кучу железа, чтобы наш Selenium grid устройств, с которых запускаются эти тесты, был больше, чтобы они не падали, потому что не смогли поднять браузер, и, соответственно, проходили побыстрее. Даже после того, как мы попробовали решить эти проблемы, мы все равно пришли к выводу, что для CI нам такие тесты не подходят, они идут очень долго. Мы не можем запускать их на каждый пул-реквест. Мы просто никогда в жизни потом не разберем эти отчеты, которые будут генериться на каждый пул-реквест.

Соответственно, для CI нам нужны быстрые и стабильные тесты, которые не будут падать по каким-то рандомным причинам. Мы хотим запускать тесты на пул-реквест без всяких тестовых стендов, бэкендов, баз данных, без каких-то сложных юзерских кейсов.
Мы хотим, чтобы эти тесты писались одновременно с кодом, и чтобы по результатам тестов было сразу понятно, в каком файле что-то пошло не так.
Алексей:
— Да, и мы решили попробовать все, что мы хотим, прямо все от начала и до конца поднять в одной и той же инфраструктуре Jest. Почему мы выбрали Jest? Мы уже писали юнит-тесты на Jest, он нам нравился. Это популярный, поддерживаемый инструмент, у него там уже есть куча готовых интеграций: React test render, Enzyme. Все работает из коробки, ничего строить не надо, все просто.

И Jest лично для меня выиграл тем, что в отличие от какой-нибудь моки, в нем сложно выстрелить себе в ногу сайд-эффектом от какого-то стороннего теста, если я его забыл почистить или что-нибудь еще. В моке это делается на раз-два, а в Jest это сложно сделать: он постоянно запускается в отдельных потоках. Можно, но сложно. И для e2e выпустили Puppeteer, мы его тоже решили попробовать. Вот что у нас получилось.

Наталья:
— Тоже начну с примера модульных тестов. Когда мы пишем тесты просто на какую-то функцию, тут особых проблем нет. Мы вызываем эту функцию, передаем какие-то аргументы, сравниваем то, что получилось, с тем, что должно было получиться.
Если речь идет про React-компоненты, то тут все становится чуть сложнее. Нам нужно их как-то рендерить. Есть React test renderer, но он не очень удобен для модульных тестов, потому что он не позволит нам протестировать компоненты изолированно. Он будет рендерить компонент полностью до конца, до верстки.
И я хочу показать, как можно с помощью Enzyme написать модульные тесты на React-компоненты на примере такого компонента, где у нас есть некий MyComponent. Он получает какие-то пропы, в нем есть какая-то логика. Дальше он возвращает компонент Foo, который, в свою очередь, будет возвращать компонент bar, который уже в компонент bar возвращает нам, собственно говоря, верстку.

Мы можем использовать такой инструмент из Enzyme, как shallow rendering. Это как раз то, что нам нужно, чтобы протестировать компонент MyComponent изолированно. И эти тесты не будут зависеть от того, что внутри себя будут содержать компоненты foo и bar. Мы просто будем тестировать логику именно компонента MyComponent.
В Jest есть такая штука, как Snapshot, и они здесь тоже могут нам помочь. «Expect что-либо toMatchSnapshot» создаст нам такую структуру, просто текстовый файл, в котором хранится, собственно, то, что мы передали в expect, то, что получается, и при первом запуске таких тестов пишется вот этот файл. При дальнейших запусках тестов то, что получается, будет сравниваться с эталоном, который содержится в файле MyComponent.test.js.snap.
Здесь мы видим как раз, что весь рендеринг, он возвращает нам ровно то, что возвращает метод рендер из MyComponent, и то, что такое foo, ему, в общем-то, пофигу. Мы можем написать такие два теста для наших двух случаев, для наших двух кейсов на компонент MyComponent.

В принципе, то же самое мы можем протестировать без Snapshot, просто проверяя нужные нам сценарии, например, проверяя, какие пропы передаются в компонент foo. Но у этого подхода есть один минус. Если мы в MyComponent добавим какой-то еще элемент, наш новый тест, это никак не отображает.

Поэтому, все-таки Snapshot-тесты — это те, которые покажут нам практически любые изменения внутри компонента. Но если мы оба теста напишем на Snapshot, а потом сделаем такие же изменения в компоненте, то мы увидим, что у нас упадут оба теста. В принципе, результаты этих упавших тестов будут говорить нам об одном и том же, что у нас там добавился какой-то «привет».

И это тоже избыточно, поэтому, я считаю, что лучше использовать один Snapshot-тест на одну и ту же структуру. Всю остальную логику проверять как-то иначе, без Snapshot, потому что Snapshot, они не очень показательны. Когда ты видишь Snapshot, просто видишь, что что-то отрендеилось, но не понятно, какую именно логику ты здесь тестировала. Это совершенно не подойдет для TDD, если вы хотите это использовать. И не пойдет, как документация. То есть потом, когда пойдете смотреть на этот компонент, вы увидите, что да, Snapshot соответствует чему-то, но какая там была логика, не очень понятно.


Точно так же мы напишем модульные тесты на компонент foo, на компонент bar, допустим, Snapshot.

У нас получится стопроцентный coverage для этих трех компонент. Мы считаем, что мы все проверили, мы молодцы.
Но, допустим, мы поменяли что-то в компоненте bar, добавили ему какой-то новый prop, и у нас упал тест на компонент bar, очевидно. Тест мы поправили, и все три теста у нас проходят.

Но на самом деле если мы соберем всю эту историю, то работать ничего не будет, потому что MyComponent не соберется вот с такой ошибкой. Мы не передаем, на самом деле, в компонент bar те prop, которые он ожидает. Поэтому мы говорим о том, что в этом случае нужны еще интеграционные тесты, которые будут проверять, в том числе, правильно ли мы вызываем из своего компонента его дочерний компонент.

Имея такие компоненты и поменяв один из них, вы сразу видите, на что изменения в этом компоненте повлияли.
Какие возможности у нас есть в Enzyme для того, чтобы проводить интеграционное тестирование? Shallow rendering сам по себе возвращает вот такую структуру. В нем есть метод dive, если он вызван на каком-то React-компоненте, он провалится в него. Соответственно, вызывая его на компоненте foo, мы получаем то, что рендерит компонент foo, это bar, если мы сделаем dive еще раз, мы получим, собственно, уже ту верстку, которую нам возвращает компонент bar. Это как раз будет уже интеграционный тест.

Либо можно отрендерить сразу все с помощью метода mount, который осуществляет full DOM rendering. Но я не советую это делать, потому что это будет очень тяжелый Snapshot. И, как правило, вам не нужно проверять полностью всю структуру. Вам нужно только проверить интеграцию между родительским и дочерним компонентом в каждом случае.

И для MyComponent мы добавляем интеграционный тест, таким образом, в первом тесте я добавляю просто dive, и получается, что мы протестировали не только логику самого компонента, но и интеграцию его с компонентом foo. То же самое, интеграционный тест мы добавим для компонента foo, что он правильно вызывает компонент bar, и тогда мы проверим всю эту цепочку, и будем уверены, что никакие изменения нам не сломают, собственно, рендеринг MyComponent

Еще один пример, уже из реального проекта. Просто кратко про то, что еще умеют Jest и Enzyme. Jest умеет моки. Вы можете, если используете какую-то внешнюю функцию в своем компоненте, можете ее замокать. Например, в этом примере мы вызываем какой-то api, мы не хотим, естественно, в модульных тест ни в какое api ходить, поэтому мы просто мокаем функцию geiResource неким объектом jest.fn. На самом деле, мок-функция. Потом мы сможем проверить, была ли она вызвана или не была, сколько раз она была вызвана, с какими аргументами. Это все позволяет делать Jest.

В shallow-рендеринге в компонент можно передать store. Если вам нужен store, вы просто можете его передать туда, и он будет работать.

Также в уже отрендеренном компоненте можно поменять State и prop.

Можно вызвать на каком-то компоненте метод simulate. Он просто вызовет обработчик. Например, если делать simulate click, вызовет onClick для компонента button вот здесь. Все это можно прочитать, естественно, в документации на Enzyme, очень много полезных штук. Это просто несколько примеров из реального проекта.

Алексей:
— Мы приходим к самому интересному вопросу. Мы умеем проверять Jest, умеем писать юнит-тесты, проверять компоненты, проверять, какие элементы неправильно реагируют на клик. Умеем проверять у них html. Теперь нам надо проверить верстку компонента, css.

И желательно это сделать так, чтобы принцип тестирования никак не отличался от того, который я описал раньше. Если я проверяю html, то я вызвал shallow rendering, он мне взял и отрендерил html. Я хочу проверить css, просто вызвать какой-то рендер и просто проверить — ничего не поднимая, никаких инструментов не настраивая.

Я начал это искать, и примерно везде давался один и тот же ответ на всю эту штуку, которая называется Puppeteer, или Selenium grid. Вы открывает какую-то вкладку, вы переходите на какой-то page html, делаете скриншот и сравниваете его с предыдущим вариантом. Если не изменился, значит, все хорошо.
Вопрос, что такое page html, если я просто хочу один компонент изолированно проверить? Желательно — в разных состояниях.

Я не хочу писать кучу этих page html на каждый компонент, на каждое состояние. У Авито есть хороший заход. Рома Дворнов опубликовал статью на Хабре, и выступление у него, кстати, было. Они что делали? Они берут компоненты, через стандартный рендер собирают html. Потом с помощью плагинов и всяких хитростей собирают все assets, которые у них есть, — картинки, css. Вставляют это все в html, и у них как раз таки получается нужный html.

И потом они подняли специальный сервер, отправляют html туда, он его рендерит, и возвращает какой-то результат. Очень интересная статья, почитайте, правда, можно почерпнуть много интересных идей оттуда.

Что мне там не нравится. Сборка компонента отличается от того, как оно поедет в production. У нас, например, webpack, а там собирается каким-то babel assets, там вытаскивается по-другому. Я не могу гарантировать, что я протестировал то, что сейчас покачу.
И опять же, отдельный сервис для скриншотов. Я хочу как-то попроще это сделать. И была, собственно, идея, что, давайте мы будем собирать это ровно так же, как мы будем это собирать. И попробуем использовать что-то, типа Dockerа, потому что это такая штука, ее можно поставить на комп, локально, это будет просто, изолированно, ничего не трогает, все хорошо.

Но эта проблема с page html, она остается все равно, что это такое, на самом деле. И родилась идея. Есть у вас такой упрощенный webpack.conf, и от него есть какой-то EntryPoint для клиентского js. Описаны модули, как их собирать, выходной файл, все плагины у вас описаны, все настроено, все хорошо.

А что если я сделаю вот так? Он мне в мой компонент зайдет и соберет его изолированно. И там будет ровно один компонент. Если я еще добавлю туда html webpack, то она выход мне даст еще и html, и там будут собраны вот эти ассеты, и эту штуку, правда, уже можно тестировать автоматически.
И я уже собрался все это писать, но потом нашел вот это.

Jest-puppeteer-React, молодой плагинчик. И я в него начал активно контрибьютить. Если вдруг захотите его попробовать, то можете, например, ко мне подойти, я как-то могу помочь. Проект, на самом деле, не мой.
Вы пишите обычный файл как test.js, а эти файлы нужно писать чуть отдельно, чтобы помочь их найти, чтобы не компилить вам весь проект, а скомпилить только нужные компоненты. По сути, берешь конфиг webpack. И входные точки меняются на эти файлы browser.js, то есть, таким образом, собирается ровно то, что мы хотим протестировать, запакует все в html, и с помощью Puppeteer сделает вам скриншоты.

Что он умеет? Он умеет снимать скриншоты, он умеет их сохранять с помощью другого плагина jest-image-snapshot. И сравнивать их умеет. В нем можно делать все, что можно делать в браузере, исполнять js, можно протестировать media-query, например, прямо сразу.
Если не нравится headless-режим, там сложно, мы не можем отладить, не понимаем, в чем проблема, отключаем headless-режим, и вам открывается обычный Chrome с обычным дебагером. Обычной web-консолью, и там прямо сидишь, дебажишь, понимаешь, что не так.
И эта штука умеет запускаться в Docker. У вас есть заранее подготовленный уже образ с этим хромом. Он настроен. Ничего ставить, кроме Docker, не надо. Просто есть образ. И Docker нам еще решает такую проблему, что если вы один и тот же скриншот снимете, например, на маке и на Linux, он будет чуть-чуть на полпикселя отличаться, потому что шрифты там рендерятся чуть-чуть не так. А Docker эту проблему решает, потому что он всегда будет запускаться в одном и том же окружении.

Что эта штука пока не умеет? Она не идеальна, но я прямо хочу это все доделать. Несложно, скоро будет. Там пока нет before-after, но это все можно эмулировать, не проблема. Пока нет моков, их тоже можно сделать. Если дальше смотреть, я хочу запускать эту штуку для любой версии Chrome, а в идеале еще втащить туда Firefox. Это тоже реально сделать.
И попробуем поиграться с разными сравнивалками скриншотов. Сейчас там используется pixelmatch. Но кажется, наша библиотека looksame, которая используется в «Гермионе», могла бы работать быстрее. Я пока попробовал, и вроде бы работает и правда быстрее и лучше.

Дальше — вот такой пример. Если вы вспомните, это то, чего я хотел в идеале. В принципе, все так и получилось: у меня есть какой-то рендер, я просто из библиотеки беру другой рендер и отправляю туда обычный компонент — прямо как в Enzyme. То есть я могу использовать Redux и замокать store ему. Любые компоненты. Я могу задать viewport, могу указать, что я хочу себе сделать ретину. Потом просто сравниваю, смотрю, что получилось с эталонным скриншотом.

Вот как это все может быть. Есть эталон, есть результат теста. Они отличаются? На глаз вообще не заметно, а на самом деле отличаются.

Еще один плюс: я могу на один компонент написать 5-10 тестов и проверить их абсолютно в любом состоянии. Selenium такого никогда не сделает. Ему надо проект собрать, страницу загрузить, придумать, как сэмулировать это состояние именно в этом компоненте на этой странице. На самом деле можно все сделать гораздо быстрее.

И поскольку мы уже втащили Puppeteer, бонусом мы получили e2e-тесты. То есть мы можем собрать проект, пойти прямо на тестовый сервер и своими руками написать e2e-тесты — ровно такие же, как были на Selenium.
Наталья:
— Получается, что здесь мы не пишем тесты не на Selenium Java инструментами, которыми мы не владеем. Мы пишем тесты на родном-любимом JS и на Puppeteer, который мы уже знаем, потому что пользуемся им в наших тестах на верстку.
Это пример из реального проекта, который я писала для нашего личного кабинета. Еще у меня был пример, когда я просто в первый раз пробовала и то и другое, и написала два теста.

Верхний большой — на Selenium и Java, нижний маленький — на JS Puppeteer. Выглядит чуть аккуратнее. Там еще 18 строк импортов. А здесь это все очень красиво и намного более читаемо, на мой взгляд, чем тест на Java. Поэтому кажется, что проще будет научить разработчиков писать фронтенд и поддерживать такие тесты, чем заставить их писать тесты на Java и Selenium.

Алексей:
— Что мы в итоге получили? Наши разработчики теперь могут сами все сделать. Мы можем покрыть логику, html-верстку, можем быстренько покрыть css в любом состоянии. И вдобавок e2e. Прекрасно. Кроме того, наши тесты лежат рядом с нашим кодом.

Разработчики уже по факту знают, что этот компонент протестирован, покрыт тестами. Я могу что угодно наворотить и просто проверить. Или, если тестов нет, — дописать их, например. Тесты начинают работать как документация на этот компонент, потому что там много логики. Где-то она может быть скрытой, неявной, а тут тесты тебе все рассказывают: если ты передал вот так, то должно быть вот так.
Поскольку инструмент один, и мы работаем в одних и тех же терминах, разработчику удобно все это писать. Мы запускаем тесты на git hook, на пул-реквест, получая очень быстрый фидбек для разработчика. И мы приближаем green master — у нас монорепа, он нам нужен, чтобы удостоверяться, что один проект не ломает другой. Спасибо.
Алексей:
— Для начала надо немного рассказать, что такое Авто.ру. Это сайт по продаже машинок. Там есть поиск, личный кабинет, автосервисы, запчасти, отзывы, кабинеты дилеров и многое другое. Авто.ру — очень большой проект, очень много кода. Весь код мы пишем в большой монорепе, потому что это все перемешивается. Одни и те же люди делают схожие задачи, например, для мобильных и десктопа. Получается много кода, и монорепа нам жизненно необходима. Вопрос — как ее тестировать?
У нас есть React и Node.js, который выполняет рендеринг на стороне сервера и запрашивает данные из бэкенда. Остались и небольшие кусочки на БЭМ.
Наталья:
— Мы начали думать в сторону автоматизации. Релизный цикл наших отдельных приложений включал в себя несколько шагов. Сначала фича разрабатывается программистом в отдельной ветке. После этого в этой же отдельной ветке фича тестируется ручными тестировщиками. Если все хорошо, задача попадает в релиз-кандидат. Если нет, то снова возвращаемся на итерацию разработки, снова тестируем. Пока тестировщик не скажет, что в этой фиче всё ок, она не попадет в релиз-кандидат.
После сборки релиза-кандидата идет ручной регресс — не всего Авто.ру, а только того пакета, который мы собираемся катить. Например, если мы собираемся катить декстопный веб, то идет ручной регресс десктопного веба. Это очень много тест-кейсов, которые проводятся вручную. Такой регресс занимал примерно один рабочий день одного ручного тестировщика.
Когда регресс пройден, происходит релиз. После этого релизная ветка вливается в мастер. На этом моменте мы как раз можем влить мастер-код, который мы протестировали только для десктопного веба, и этот код может сломать мобильный веб, например. Это проверяется не сразу, а только на следующем ручном регрессе — мобильного веба.
Естественно, самым больным местом в этом процессе был ручной регресс, который проводился очень долго. Все ручные тестировщики, естественно, устали проходить каждый день одно и то же. Поэтому мы решили все автоматизировать. Первое решение, которое было выполнено, — автотесты Selenium и Java, написанные отдельной командой. Это были end-to-end-тесты, e2e, которые тестировали все приложение целиком. Написали около 5 тысяч таких тестов. Чего мы в итоге добились?
Естественно, мы ускорили регресс. Автотесты проходят гораздо быстрее, чем это делает ручной тестировщик, где-то раз в 10 быстрее получилось. Соответственно, с ручных тестировщиков сняли рутинные действия, которые они выполняли каждый день. Найденные баги из автотестов проще воспроизводить. Просто перезапускаешь этот тест или смотришь по шагам, что он делает — в отличие от ручного тестировщика, который скажет: «Я что-то нажал, и все сломалось».
Обеспечили стабильность покрытия. У нас всегда запускается один и тот же run тестов — в отличие, опять же, от ручного тестирования, когда тестировщик может посчитать, что вот это место мы не трогали, и я его в этот раз проверять не буду. Мы добавили тесты на сравнение скриншотов, повысили точность тестирования UI — теперь проверяем расхождение в пару пикселей, которое тестировщик глазами не увидит. Всё благодаря скриншотным тестам.
Но были и минусы. Самой большой — для e2e-тестов нам нужно тестовое окружение, которое полностью соответствует проду. Его нужно всегда поддерживать в актуальном и рабочем состоянии. Для этого нужно практически столько же сил, сколько на поддержку стабильности прода. Естественно, мы не всегда можем себе это позволить. Поэтому у нас часто были ситуации, когда тестовое окружение лежит или где-то что-то сломано, и у нас падают тесты — хотя в самом фронтовом пакете проблем не было.
Еще эти тесты разрабатывает отдельная команда, у которой свои задачи, своя очередь в трекере задач, и новые фичи покрываются с некоторой задержкой. Они не могут сразу после релиза новой фичи прийти и тут же написать на нее автотесты. Поскольку тесты дорогие и их сложно писать и поддерживать, мы покрываем ими не все сценарии, а только самые критичные. При этом отдельная команда нужна, и у нее будут отдельные инструменты, отдельная инфраструктура, все свое. И разбор упавших тестов — тоже нетривиальная задача для ручных тестировщиков или для разработчиков. Покажу пару примеров.
У нас есть run-тесты. 500 тестов прошло, из них сколько-то упало. Мы в отчете можем увидеть вот такую штуку. Тут тест просто не запустился, и не понятно, хорошо там всё или нет.
Еще один пример — тест запустился, но упал вот с такой ошибкой. Он не смог найти какой-то элемент на странице, но почему — мы не знаем. Либо этот элемент просто не появился, либо оказался не на той странице, либо поменялся локатор. Это все нужно идти и дебажить руками.
Скриншотные тесты тоже не всегда дают нам хорошую точность. Здесь мы загружаем какую-то карту, она чуть-чуть сдвинулась, у нас тест упал.
Мы попытались решить ряд этих проблем. Часть тестов мы стали запускать на проде — те, которые не задевают юзерских данных, не меняют ничего в базе. То есть мы на проде сделали отдельную машинку, которая смотрит в прод-окружение. Мы просто ставим новый пакет фронтенда и прогоняем там тесты. Прод, по крайней мере, стабильный.
Часть тестов мы перевели на моки, но у нас очень много разных бэкендов, разных API, и все это замокать — очень тяжелая задача, тем более для 5 тысяч тестов. Для этого был написан специальный сервис, который называется mockritsa, он помогает довольно легко сделать нужные моки для фронтенда и довольно легко в них проксироваться.
Также нам пришлось купить кучу железа, чтобы наш Selenium grid устройств, с которых запускаются эти тесты, был больше, чтобы они не падали, потому что не смогли поднять браузер, и, соответственно, проходили побыстрее. Даже после того, как мы попробовали решить эти проблемы, мы все равно пришли к выводу, что для CI нам такие тесты не подходят, они идут очень долго. Мы не можем запускать их на каждый пул-реквест. Мы просто никогда в жизни потом не разберем эти отчеты, которые будут генериться на каждый пул-реквест.
Соответственно, для CI нам нужны быстрые и стабильные тесты, которые не будут падать по каким-то рандомным причинам. Мы хотим запускать тесты на пул-реквест без всяких тестовых стендов, бэкендов, баз данных, без каких-то сложных юзерских кейсов.
Мы хотим, чтобы эти тесты писались одновременно с кодом, и чтобы по результатам тестов было сразу понятно, в каком файле что-то пошло не так.
Алексей:
— Да, и мы решили попробовать все, что мы хотим, прямо все от начала и до конца поднять в одной и той же инфраструктуре Jest. Почему мы выбрали Jest? Мы уже писали юнит-тесты на Jest, он нам нравился. Это популярный, поддерживаемый инструмент, у него там уже есть куча готовых интеграций: React test render, Enzyme. Все работает из коробки, ничего строить не надо, все просто.
И Jest лично для меня выиграл тем, что в отличие от какой-нибудь моки, в нем сложно выстрелить себе в ногу сайд-эффектом от какого-то стороннего теста, если я его забыл почистить или что-нибудь еще. В моке это делается на раз-два, а в Jest это сложно сделать: он постоянно запускается в отдельных потоках. Можно, но сложно. И для e2e выпустили Puppeteer, мы его тоже решили попробовать. Вот что у нас получилось.
Наталья:
— Тоже начну с примера модульных тестов. Когда мы пишем тесты просто на какую-то функцию, тут особых проблем нет. Мы вызываем эту функцию, передаем какие-то аргументы, сравниваем то, что получилось, с тем, что должно было получиться.
Если речь идет про React-компоненты, то тут все становится чуть сложнее. Нам нужно их как-то рендерить. Есть React test renderer, но он не очень удобен для модульных тестов, потому что он не позволит нам протестировать компоненты изолированно. Он будет рендерить компонент полностью до конца, до верстки.
И я хочу показать, как можно с помощью Enzyme написать модульные тесты на React-компоненты на примере такого компонента, где у нас есть некий MyComponent. Он получает какие-то пропы, в нем есть какая-то логика. Дальше он возвращает компонент Foo, который, в свою очередь, будет возвращать компонент bar, который уже в компонент bar возвращает нам, собственно говоря, верстку.
Мы можем использовать такой инструмент из Enzyme, как shallow rendering. Это как раз то, что нам нужно, чтобы протестировать компонент MyComponent изолированно. И эти тесты не будут зависеть от того, что внутри себя будут содержать компоненты foo и bar. Мы просто будем тестировать логику именно компонента MyComponent.
В Jest есть такая штука, как Snapshot, и они здесь тоже могут нам помочь. «Expect что-либо toMatchSnapshot» создаст нам такую структуру, просто текстовый файл, в котором хранится, собственно, то, что мы передали в expect, то, что получается, и при первом запуске таких тестов пишется вот этот файл. При дальнейших запусках тестов то, что получается, будет сравниваться с эталоном, который содержится в файле MyComponent.test.js.snap.
Здесь мы видим как раз, что весь рендеринг, он возвращает нам ровно то, что возвращает метод рендер из MyComponent, и то, что такое foo, ему, в общем-то, пофигу. Мы можем написать такие два теста для наших двух случаев, для наших двух кейсов на компонент MyComponent.
В принципе, то же самое мы можем протестировать без Snapshot, просто проверяя нужные нам сценарии, например, проверяя, какие пропы передаются в компонент foo. Но у этого подхода есть один минус. Если мы в MyComponent добавим какой-то еще элемент, наш новый тест, это никак не отображает.
Поэтому, все-таки Snapshot-тесты — это те, которые покажут нам практически любые изменения внутри компонента. Но если мы оба теста напишем на Snapshot, а потом сделаем такие же изменения в компоненте, то мы увидим, что у нас упадут оба теста. В принципе, результаты этих упавших тестов будут говорить нам об одном и том же, что у нас там добавился какой-то «привет».
И это тоже избыточно, поэтому, я считаю, что лучше использовать один Snapshot-тест на одну и ту же структуру. Всю остальную логику проверять как-то иначе, без Snapshot, потому что Snapshot, они не очень показательны. Когда ты видишь Snapshot, просто видишь, что что-то отрендеилось, но не понятно, какую именно логику ты здесь тестировала. Это совершенно не подойдет для TDD, если вы хотите это использовать. И не пойдет, как документация. То есть потом, когда пойдете смотреть на этот компонент, вы увидите, что да, Snapshot соответствует чему-то, но какая там была логика, не очень понятно.
Точно так же мы напишем модульные тесты на компонент foo, на компонент bar, допустим, Snapshot.
У нас получится стопроцентный coverage для этих трех компонент. Мы считаем, что мы все проверили, мы молодцы.
Но, допустим, мы поменяли что-то в компоненте bar, добавили ему какой-то новый prop, и у нас упал тест на компонент bar, очевидно. Тест мы поправили, и все три теста у нас проходят.
Но на самом деле если мы соберем всю эту историю, то работать ничего не будет, потому что MyComponent не соберется вот с такой ошибкой. Мы не передаем, на самом деле, в компонент bar те prop, которые он ожидает. Поэтому мы говорим о том, что в этом случае нужны еще интеграционные тесты, которые будут проверять, в том числе, правильно ли мы вызываем из своего компонента его дочерний компонент.
Имея такие компоненты и поменяв один из них, вы сразу видите, на что изменения в этом компоненте повлияли.
Какие возможности у нас есть в Enzyme для того, чтобы проводить интеграционное тестирование? Shallow rendering сам по себе возвращает вот такую структуру. В нем есть метод dive, если он вызван на каком-то React-компоненте, он провалится в него. Соответственно, вызывая его на компоненте foo, мы получаем то, что рендерит компонент foo, это bar, если мы сделаем dive еще раз, мы получим, собственно, уже ту верстку, которую нам возвращает компонент bar. Это как раз будет уже интеграционный тест.
Либо можно отрендерить сразу все с помощью метода mount, который осуществляет full DOM rendering. Но я не советую это делать, потому что это будет очень тяжелый Snapshot. И, как правило, вам не нужно проверять полностью всю структуру. Вам нужно только проверить интеграцию между родительским и дочерним компонентом в каждом случае.
И для MyComponent мы добавляем интеграционный тест, таким образом, в первом тесте я добавляю просто dive, и получается, что мы протестировали не только логику самого компонента, но и интеграцию его с компонентом foo. То же самое, интеграционный тест мы добавим для компонента foo, что он правильно вызывает компонент bar, и тогда мы проверим всю эту цепочку, и будем уверены, что никакие изменения нам не сломают, собственно, рендеринг MyComponent
Еще один пример, уже из реального проекта. Просто кратко про то, что еще умеют Jest и Enzyme. Jest умеет моки. Вы можете, если используете какую-то внешнюю функцию в своем компоненте, можете ее замокать. Например, в этом примере мы вызываем какой-то api, мы не хотим, естественно, в модульных тест ни в какое api ходить, поэтому мы просто мокаем функцию geiResource неким объектом jest.fn. На самом деле, мок-функция. Потом мы сможем проверить, была ли она вызвана или не была, сколько раз она была вызвана, с какими аргументами. Это все позволяет делать Jest.
В shallow-рендеринге в компонент можно передать store. Если вам нужен store, вы просто можете его передать туда, и он будет работать.
Также в уже отрендеренном компоненте можно поменять State и prop.
Можно вызвать на каком-то компоненте метод simulate. Он просто вызовет обработчик. Например, если делать simulate click, вызовет onClick для компонента button вот здесь. Все это можно прочитать, естественно, в документации на Enzyme, очень много полезных штук. Это просто несколько примеров из реального проекта.
Алексей:
— Мы приходим к самому интересному вопросу. Мы умеем проверять Jest, умеем писать юнит-тесты, проверять компоненты, проверять, какие элементы неправильно реагируют на клик. Умеем проверять у них html. Теперь нам надо проверить верстку компонента, css.
И желательно это сделать так, чтобы принцип тестирования никак не отличался от того, который я описал раньше. Если я проверяю html, то я вызвал shallow rendering, он мне взял и отрендерил html. Я хочу проверить css, просто вызвать какой-то рендер и просто проверить — ничего не поднимая, никаких инструментов не настраивая.
Я начал это искать, и примерно везде давался один и тот же ответ на всю эту штуку, которая называется Puppeteer, или Selenium grid. Вы открывает какую-то вкладку, вы переходите на какой-то page html, делаете скриншот и сравниваете его с предыдущим вариантом. Если не изменился, значит, все хорошо.
Вопрос, что такое page html, если я просто хочу один компонент изолированно проверить? Желательно — в разных состояниях.
Ссылка со слайда
Я не хочу писать кучу этих page html на каждый компонент, на каждое состояние. У Авито есть хороший заход. Рома Дворнов опубликовал статью на Хабре, и выступление у него, кстати, было. Они что делали? Они берут компоненты, через стандартный рендер собирают html. Потом с помощью плагинов и всяких хитростей собирают все assets, которые у них есть, — картинки, css. Вставляют это все в html, и у них как раз таки получается нужный html.
Ссылка со слайда
И потом они подняли специальный сервер, отправляют html туда, он его рендерит, и возвращает какой-то результат. Очень интересная статья, почитайте, правда, можно почерпнуть много интересных идей оттуда.
Что мне там не нравится. Сборка компонента отличается от того, как оно поедет в production. У нас, например, webpack, а там собирается каким-то babel assets, там вытаскивается по-другому. Я не могу гарантировать, что я протестировал то, что сейчас покачу.
И опять же, отдельный сервис для скриншотов. Я хочу как-то попроще это сделать. И была, собственно, идея, что, давайте мы будем собирать это ровно так же, как мы будем это собирать. И попробуем использовать что-то, типа Dockerа, потому что это такая штука, ее можно поставить на комп, локально, это будет просто, изолированно, ничего не трогает, все хорошо.
Но эта проблема с page html, она остается все равно, что это такое, на самом деле. И родилась идея. Есть у вас такой упрощенный webpack.conf, и от него есть какой-то EntryPoint для клиентского js. Описаны модули, как их собирать, выходной файл, все плагины у вас описаны, все настроено, все хорошо.
А что если я сделаю вот так? Он мне в мой компонент зайдет и соберет его изолированно. И там будет ровно один компонент. Если я еще добавлю туда html webpack, то она выход мне даст еще и html, и там будут собраны вот эти ассеты, и эту штуку, правда, уже можно тестировать автоматически.
И я уже собрался все это писать, но потом нашел вот это.
Jest-puppeteer-React, молодой плагинчик. И я в него начал активно контрибьютить. Если вдруг захотите его попробовать, то можете, например, ко мне подойти, я как-то могу помочь. Проект, на самом деле, не мой.
Вы пишите обычный файл как test.js, а эти файлы нужно писать чуть отдельно, чтобы помочь их найти, чтобы не компилить вам весь проект, а скомпилить только нужные компоненты. По сути, берешь конфиг webpack. И входные точки меняются на эти файлы browser.js, то есть, таким образом, собирается ровно то, что мы хотим протестировать, запакует все в html, и с помощью Puppeteer сделает вам скриншоты.
Что он умеет? Он умеет снимать скриншоты, он умеет их сохранять с помощью другого плагина jest-image-snapshot. И сравнивать их умеет. В нем можно делать все, что можно делать в браузере, исполнять js, можно протестировать media-query, например, прямо сразу.
Если не нравится headless-режим, там сложно, мы не можем отладить, не понимаем, в чем проблема, отключаем headless-режим, и вам открывается обычный Chrome с обычным дебагером. Обычной web-консолью, и там прямо сидишь, дебажишь, понимаешь, что не так.
И эта штука умеет запускаться в Docker. У вас есть заранее подготовленный уже образ с этим хромом. Он настроен. Ничего ставить, кроме Docker, не надо. Просто есть образ. И Docker нам еще решает такую проблему, что если вы один и тот же скриншот снимете, например, на маке и на Linux, он будет чуть-чуть на полпикселя отличаться, потому что шрифты там рендерятся чуть-чуть не так. А Docker эту проблему решает, потому что он всегда будет запускаться в одном и том же окружении.
Что эта штука пока не умеет? Она не идеальна, но я прямо хочу это все доделать. Несложно, скоро будет. Там пока нет before-after, но это все можно эмулировать, не проблема. Пока нет моков, их тоже можно сделать. Если дальше смотреть, я хочу запускать эту штуку для любой версии Chrome, а в идеале еще втащить туда Firefox. Это тоже реально сделать.
И попробуем поиграться с разными сравнивалками скриншотов. Сейчас там используется pixelmatch. Но кажется, наша библиотека looksame, которая используется в «Гермионе», могла бы работать быстрее. Я пока попробовал, и вроде бы работает и правда быстрее и лучше.
Дальше — вот такой пример. Если вы вспомните, это то, чего я хотел в идеале. В принципе, все так и получилось: у меня есть какой-то рендер, я просто из библиотеки беру другой рендер и отправляю туда обычный компонент — прямо как в Enzyme. То есть я могу использовать Redux и замокать store ему. Любые компоненты. Я могу задать viewport, могу указать, что я хочу себе сделать ретину. Потом просто сравниваю, смотрю, что получилось с эталонным скриншотом.
Вот как это все может быть. Есть эталон, есть результат теста. Они отличаются? На глаз вообще не заметно, а на самом деле отличаются.
Еще один плюс: я могу на один компонент написать 5-10 тестов и проверить их абсолютно в любом состоянии. Selenium такого никогда не сделает. Ему надо проект собрать, страницу загрузить, придумать, как сэмулировать это состояние именно в этом компоненте на этой странице. На самом деле можно все сделать гораздо быстрее.
И поскольку мы уже втащили Puppeteer, бонусом мы получили e2e-тесты. То есть мы можем собрать проект, пойти прямо на тестовый сервер и своими руками написать e2e-тесты — ровно такие же, как были на Selenium.
Наталья:
— Получается, что здесь мы не пишем тесты не на Selenium Java инструментами, которыми мы не владеем. Мы пишем тесты на родном-любимом JS и на Puppeteer, который мы уже знаем, потому что пользуемся им в наших тестах на верстку.
Это пример из реального проекта, который я писала для нашего личного кабинета. Еще у меня был пример, когда я просто в первый раз пробовала и то и другое, и написала два теста.
Верхний большой — на Selenium и Java, нижний маленький — на JS Puppeteer. Выглядит чуть аккуратнее. Там еще 18 строк импортов. А здесь это все очень красиво и намного более читаемо, на мой взгляд, чем тест на Java. Поэтому кажется, что проще будет научить разработчиков писать фронтенд и поддерживать такие тесты, чем заставить их писать тесты на Java и Selenium.
Алексей:
— Что мы в итоге получили? Наши разработчики теперь могут сами все сделать. Мы можем покрыть логику, html-верстку, можем быстренько покрыть css в любом состоянии. И вдобавок e2e. Прекрасно. Кроме того, наши тесты лежат рядом с нашим кодом.
Разработчики уже по факту знают, что этот компонент протестирован, покрыт тестами. Я могу что угодно наворотить и просто проверить. Или, если тестов нет, — дописать их, например. Тесты начинают работать как документация на этот компонент, потому что там много логики. Где-то она может быть скрытой, неявной, а тут тесты тебе все рассказывают: если ты передал вот так, то должно быть вот так.
Поскольку инструмент один, и мы работаем в одних и тех же терминах, разработчику удобно все это писать. Мы запускаем тесты на git hook, на пул-реквест, получая очень быстрый фидбек для разработчика. И мы приближаем green master — у нас монорепа, он нам нужен, чтобы удостоверяться, что один проект не ломает другой. Спасибо.


