В данной заметке я продолжу знакомить читателей с возможностями проекта Apache NlpCraft. Первая заметка была посвящена краткому описанию ключевых особенностей системы, следующая — обзору стандартных NER компонентов. Данная статья посвящена вопросу проектирования интентов при построении диалоговых систем.
Напомню, что такое интент. Интент — это сочетание функции и правила, по которому эта функция должна быть вызвана. Правило — это чаще всего шаблон, основанный на наборе ожидаемых именованных сущностей в тексте запроса. В большинстве существующих диалоговых систем данный шаблон — это просто список элементов.
Выше приведено окно отладки интента в Amazon Alexa. Отлаживаемая модель — система управления будильником. В основе модели две сущности и один интент.
Сущности:
Правило задано очень простое — если в тексте запроса обнаружены обе эти сущности, функция интента должна быть вызвана.
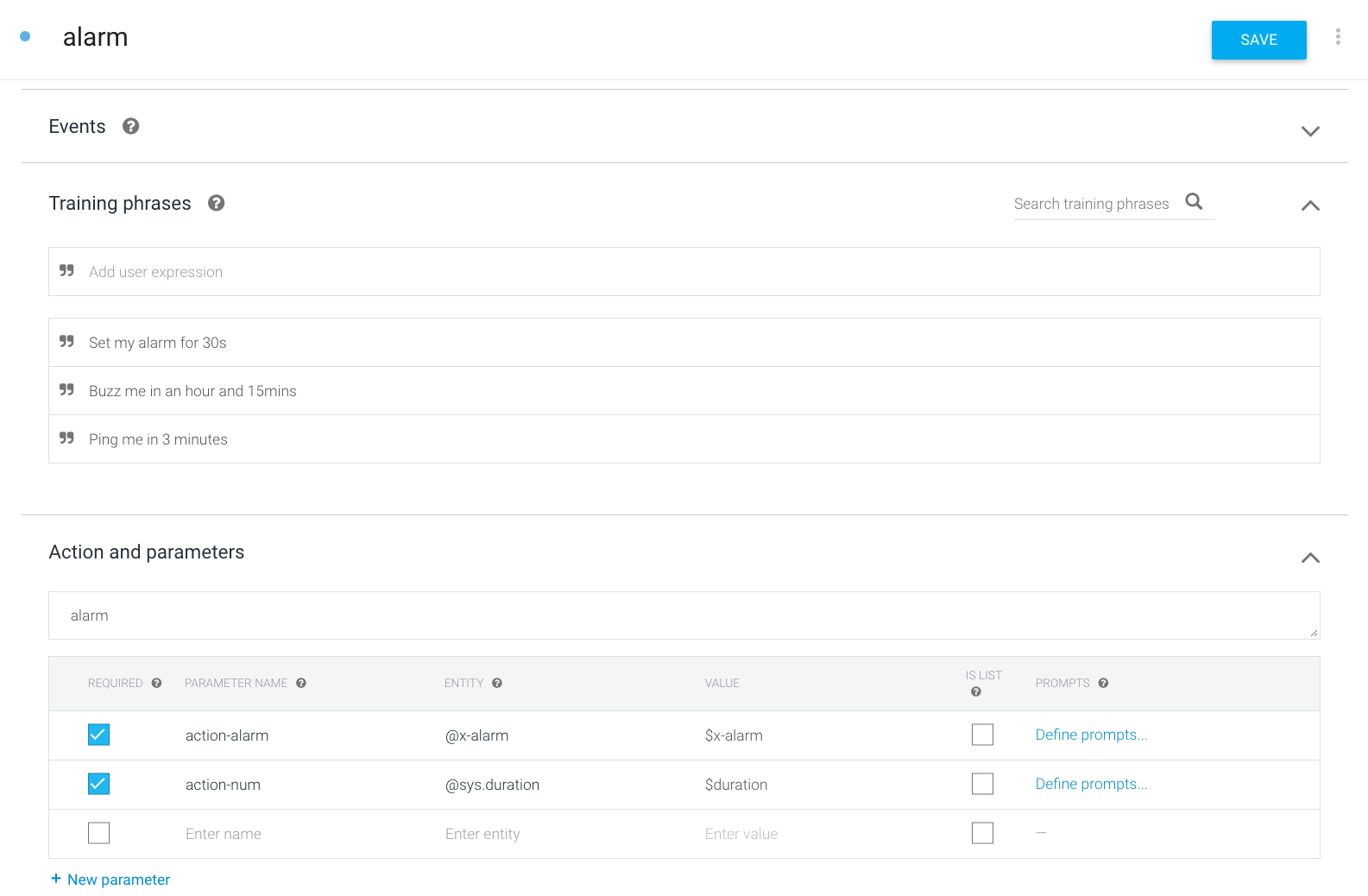
Ниже экран определения этого же интента в Google DialogFlow.

Как мы видим, помимо собственно списка требуемых элементов, каждый элемент в списке может быть дополнен некоторыми параметрами, например признаком, обязателен ли элемент для срабатывания интента, “prompts”, то есть вопросами, с помощью которых система должна уточнить у пользователя значение отсутствующего элемента и т.д.
Таким образом при работе с Amazon Alexa и Google DialogFlow, интент определяется с помощью списка параметров, а также минимального набора свойств параметров.
Детальный пример построения данной модели в Apache NlpCraft доступен по ссылке.
Как мы видим система конфигурирования интентов для данных систем совершенно проста и понятна, и это, разумеется, хорошо. Однако для более сложных моделей такой подход может оказаться недостаточно гибким. Не требуется ничего усложнять, если все что вам нужно — это осуществить заказ пиццы через внешний API, пример, отчего-то встречающийся в половине обзоров. Но если в вашей системе много интентов, или внутри функции интента присутствует сложная логика по выбору API или параметра — подобная простота может стать серьезным ограничением (Тут стоит отметить, что гибкости интентам добавляет поддержка flow, но об этом позже).
Теперь подробнее о проблемах
На самом деле при работе Google DialogFlow с данным примером все будет не так просто. Стандартный NER компонент sys.duration не покроет всех возможных вариантов задания временного периода. Так, например, в запросе “Ping me in 3 minutes” для определения периода “3 minutes” придется задействовать компонент sys.date-time, а в запросе “Set my alarm for 30s” — sys.date-period. То есть сущность “период“ для тестовых вопросов должна быть определена через стандартные sys.period, sys.date-period или sys.date-time. (Оставим в стороне вопрос почему так происходит или как избежать именно этой конкретной ситуации). Таким образом интент придется усложнить, он должен будет содержать помимо “признака действия”, один из трех необязательных элементов, определяющих “период”. Причем в итоге хотя бы один из этих трех опциональных NER компонентов для определения периода все же должен сработать.
Решить эту проблему конечно же можно просто наплодив побольше интентов (скоро вы в них запутаетесь) или создав собственный элемент “user:duration”, который учтет все ваши пожелания (если пойдете по этому пути — вам могут помочь “составные сущности“, подробнее — здесь)
Но в общем случае, для решения проблем подобного рода, Apache NlpCraft предлагает гибкую систему построения интентов. Суть ее в том, что с помощью элементов конфигурации вы можете определить дополнительные условия срабатывания интента, и отбросить те случаи, когда запрос содержит все необходимые сущности, но все же не удовлетворяет каким-то вашим особым требованиям.
Что можно сконфигурировать
Примеры
Приведу пару примеров определения интентов целиком с пояснениями:
Выше определен интент с идентификатором “alarm”, который должен сработать в случае если пользовательский запрос содержит:
Оба элемента могут быть получены как напрямую, так и из контекста беседы. Порядок элементов в запросе важен.
Еще пример
Выше определен интент с идентификатором “customSortReport”, который должен сработать в случае если пользовательский запрос содержит:
Кроме того, для успешного срабатывания интента необходимо чтобы перед проверяемым запросом произошло как минимум одно успешное срабатывание интента с идентификатором “login”.
Изощренных примеров я приводить не буду, думаю основная идея понятна.
Зачем нужна подобная гибкость
Задание таких достаточно сложных интентов преследует две основные цели:
Остановимся подробнее на втором пункте. Это достаточно сложная проблема, возникающая в ситуациях, когда требуется поддерживать множество интентов в рамках одной модели. Рассмотрим пример. Пусть модель содержит две сущности: “вопрос про время” и “город”, и пусть мы хотим поддержать следующую логику ответов:
Согласно данной логике создадим два интента:
Проблема в том, что интент “weather” имеет более высокий приоритет по причине более строго задания условия и будет вызван даже для запросов по малым городам. Если разработчик бросит в его колбеке определенное исключение (подробнее тут и тут, возможность передачи управления — одна из важных особенностей системы обработки интентов Apache NlpCraft), то управление будет возвращено матчеру интентов и для данного запроса отыщется другой, более подходящий интент — “adv”. Но в нашем случае естественнее добавить в интент “weather” фильтр, чтобы сразу избежать ложного срабатывания.
Обратите внимание на то, что с помощью фильтров не всегда можно решить проблему нежелательного срабатывания интента, и иногда все же проще воспользоваться механизмом передачи управления из функции обратно матчеру. Так было сделано для соблюдения баланса между возможностями, предоставляемыми фильтрами и удобством их использования. Изначально, в процессе проектировании Intent DSL, была предпринята попытка покрыть все возможные варианты матчинга, но сложность работы с такими фильтрами вышла за все допустимые рамки.
Настройка модели
Что еще пользователь Apache NlpCraft может настроить в модели, из того что может повлиять на работу с интентами:
Указанные выше настройки применяются ко всей модели, а не к какому-либо конкретному интенту. Подробное описание работы с моделями и их параметрами — здесь.
Заключение
Я постарался описать основные возможности достаточно мощной системы построения интентов, предоставляемой проектом Apache NlpCraft и привести несколько примеров ее использования. Хочу обратить внимание на то, что я не ставил перед собой задачи сравнения каких-то проектов с целью выявления победителя, и рассказать, кто же лучше и гибче других поддерживает определение интентов. Alexa, Google Dialogflow — мощные, отточенные системы, и полагаю, что в силу специфики их архитектуры, инструментария и т.д., функциональность построения интентов в них ограничена вполне осознанно. Apache NlpCraft — проект совершенно другого рода, спроектированный для решения иного типа задач и обладающий принципиально иными возможностями. С одной стороны он не имеет некоторых неоспоримых преимуществ вышеперечисленных проектов, особенно в области интеграций, автоматизации развертывания, WebUI. C другой стороны он свободен от множества естественных ограничений этих проектов и может предоставить своим пользователям максимально гибкий NLP инструментарий, а также практически полный контроль над матчингом пользовательских запросов.
Напомню, что такое интент. Интент — это сочетание функции и правила, по которому эта функция должна быть вызвана. Правило — это чаще всего шаблон, основанный на наборе ожидаемых именованных сущностей в тексте запроса. В большинстве существующих диалоговых систем данный шаблон — это просто список элементов.
Выше приведено окно отладки интента в Amazon Alexa. Отлаживаемая модель — система управления будильником. В основе модели две сущности и один интент.
Сущности:
- Признак действия. “Пользовательская” сущность, определяемая для данной конкретной модели. Мы определили ее через синонимы: wake, buzz и т.д.
- Период времени — in 3 mins, in 2 mins and 30 seconds и т.д. Здесь может быть использован как пользовательский элемент, так и какой-нибудь из стандартных. В данном случае sys.duration.
Правило задано очень простое — если в тексте запроса обнаружены обе эти сущности, функция интента должна быть вызвана.
Ниже экран определения этого же интента в Google DialogFlow.
Как мы видим, помимо собственно списка требуемых элементов, каждый элемент в списке может быть дополнен некоторыми параметрами, например признаком, обязателен ли элемент для срабатывания интента, “prompts”, то есть вопросами, с помощью которых система должна уточнить у пользователя значение отсутствующего элемента и т.д.
Таким образом при работе с Amazon Alexa и Google DialogFlow, интент определяется с помощью списка параметров, а также минимального набора свойств параметров.
Детальный пример построения данной модели в Apache NlpCraft доступен по ссылке.
Как мы видим система конфигурирования интентов для данных систем совершенно проста и понятна, и это, разумеется, хорошо. Однако для более сложных моделей такой подход может оказаться недостаточно гибким. Не требуется ничего усложнять, если все что вам нужно — это осуществить заказ пиццы через внешний API, пример, отчего-то встречающийся в половине обзоров. Но если в вашей системе много интентов, или внутри функции интента присутствует сложная логика по выбору API или параметра — подобная простота может стать серьезным ограничением (Тут стоит отметить, что гибкости интентам добавляет поддержка flow, но об этом позже).
Теперь подробнее о проблемах
На самом деле при работе Google DialogFlow с данным примером все будет не так просто. Стандартный NER компонент sys.duration не покроет всех возможных вариантов задания временного периода. Так, например, в запросе “Ping me in 3 minutes” для определения периода “3 minutes” придется задействовать компонент sys.date-time, а в запросе “Set my alarm for 30s” — sys.date-period. То есть сущность “период“ для тестовых вопросов должна быть определена через стандартные sys.period, sys.date-period или sys.date-time. (Оставим в стороне вопрос почему так происходит или как избежать именно этой конкретной ситуации). Таким образом интент придется усложнить, он должен будет содержать помимо “признака действия”, один из трех необязательных элементов, определяющих “период”. Причем в итоге хотя бы один из этих трех опциональных NER компонентов для определения периода все же должен сработать.
Решить эту проблему конечно же можно просто наплодив побольше интентов (скоро вы в них запутаетесь) или создав собственный элемент “user:duration”, который учтет все ваши пожелания (если пойдете по этому пути — вам могут помочь “составные сущности“, подробнее — здесь)
Но в общем случае, для решения проблем подобного рода, Apache NlpCraft предлагает гибкую систему построения интентов. Суть ее в том, что с помощью элементов конфигурации вы можете определить дополнительные условия срабатывания интента, и отбросить те случаи, когда запрос содержит все необходимые сущности, но все же не удовлетворяет каким-то вашим особым требованиям.
Что можно сконфигурировать
- Учет требуемого порядка элементов. То есть вы можете определить интент, который сработает для “ping me in 2 secs”, но не сработает для “in 2 secs ping me”.
- Задание ожидаемого предыдущего flow прямо в интенте (многие системы позволяют определять flow, но не прямо в определении интента).
Пример паттерна flow='i1[1, 3]* >> (i2|i3)+' означает, что для успешного срабатывания конфигурируемого интента, запросу должны предшествовать один, два или три запроса, соответствующих интенту “i1“, а перед ними — один или более запросов, соответствующих интентам “i2“ или “i3“. - Требуемое количество элементов одного типа в интенте. Определяется с помощью конкретного значения, диапазона или шаблона.
- Элементы интента могут быть помечены как доступные или недоступные из контекста беседы.
Пример — пусть погодный интент ожидает две сущности: ”city” и ”date”.
- На первый вопрос в беседе “дай мне погоду на завтра в Москве“ — мы можем ответить по найденным в тексте запроса элементам “city“ — Москва и “date” — завтра.
- Но на второй вопрос — “а на послезавтра?”, мы можем ответить только если возьмем значение “city” из контекста беседы.
- В конфигурации интента мы можем пометить каждый элемент — должен ли он быть доступен только из текущего предложения или может быть также получен из контекста.
- Каждый элемент может быть проверен на удовлетворение ряду условий с помощью специального DSL, предоставляющего широкие возможности по фильтрации. Фильтрация может осуществляться как по характеристикам сущностей, так и по NLP характеристикам самих слов, по которым сущность была обнаружена.
Пара нарочито экзотических примеров:
- isalpha(~nlp:origtext) == true — все буквы слова, соответствующего проверяемому элементу интента, должны быть в формате unicode.
- startidx != 0 — слово, соответствующее элементу интента, не должно быть первым в запросе.
- lowercase(~city:country) == 'france') — значение поля ”country” элемента “city” должно быть равно ‘france' без учета регистра.
Примеры
Приведу пару примеров определения интентов целиком с пояснениями:
intent=alarm
ordered = true
term~{id=='x:alarm'}
term(nums)~{
id=='nlpcraft:num' &&
~nlpcraft:num:unittype=='datetime' &&
~nlpcraft:num:isequalcondition==true
}[0,7]
Выше определен интент с идентификатором “alarm”, который должен сработать в случае если пользовательский запрос содержит:
- одну сущность типа “x:alarm”, а также
- от нуля до семи сущностей типа “nlpcraft:num” со значением поля “unittype” равным “datetime” и значением поля ”isequalcondition” равным true.
Оба элемента могут быть получены как напрямую, так и из контекста беседы. Порядок элементов в запросе важен.
Еще пример
intent=customSortReport
flow='login+'
term(sort)~{id == 'sort:best' || id == 'sort:worst'}
term(tbls)={groups @@ 'table'}+
Выше определен интент с идентификатором “customSortReport”, который должен сработать в случае если пользовательский запрос содержит:
- одну сущность типа “sort:best” или “sort:worst” (данная сущность может быть получена из текста запроса или извлечена из контекста беседы) и
- одну или более сущностей группы “table” (данные сущности должны быть представлены в запросе и не могут быть извлечены из контекста беседы).
Кроме того, для успешного срабатывания интента необходимо чтобы перед проверяемым запросом произошло как минимум одно успешное срабатывание интента с идентификатором “login”.
Изощренных примеров я приводить не буду, думаю основная идея понятна.
Зачем нужна подобная гибкость
Задание таких достаточно сложных интентов преследует две основные цели:
- Разумная минимизация их количества, возможность объединения логически схожих интентов. Так для примера “будильник” для Google DialogFlow мы можем создать всего один интент с условием:
term(period)~{ id == 'sys.period' || id == 'sys.date-period' || id == 'sys.date-time' } - Сведение к минимуму ложных срабатываний, то есть ситуаций, когда мы уже попали в функцию соответствующую интенту, и только в ней смогли разобраться, что попали в этот интент по ошибке и надо было бы выбрать другой.
Остановимся подробнее на втором пункте. Это достаточно сложная проблема, возникающая в ситуациях, когда требуется поддерживать множество интентов в рамках одной модели. Рассмотрим пример. Пусть модель содержит две сущности: “вопрос про время” и “город”, и пусть мы хотим поддержать следующую логику ответов:
- Возвращать прогноз погоды, если в вопросе нашлись обе сущности, но только для крупных городов, для малых у нас нет данных.
- Для малых городов, или если запрос был задан без указания города — возвращать рекламу.
- Прочие запросы игнорировать.
Согласно данной логике создадим два интента:
intent=weather
term(t1)={id == 'custom:weather:ask'}
term(t2)={id == 'nlpcraft:city'}
intent=adv
term(t1)={id == 'custom:weather:ask'}
term(t2)={id == 'nlpcraft:city'}?
Проблема в том, что интент “weather” имеет более высокий приоритет по причине более строго задания условия и будет вызван даже для запросов по малым городам. Если разработчик бросит в его колбеке определенное исключение (подробнее тут и тут, возможность передачи управления — одна из важных особенностей системы обработки интентов Apache NlpCraft), то управление будет возвращено матчеру интентов и для данного запроса отыщется другой, более подходящий интент — “adv”. Но в нашем случае естественнее добавить в интент “weather” фильтр, чтобы сразу избежать ложного срабатывания.
intent=weather
term(t1)={id == 'custom:weather:ask'}
term(t2)={
id == 'nlpcraft:city' &&
~nlpcraft:city:citymeta['population'] >= 100000
}
Обратите внимание на то, что с помощью фильтров не всегда можно решить проблему нежелательного срабатывания интента, и иногда все же проще воспользоваться механизмом передачи управления из функции обратно матчеру. Так было сделано для соблюдения баланса между возможностями, предоставляемыми фильтрами и удобством их использования. Изначально, в процессе проектировании Intent DSL, была предпринята попытка покрыть все возможные варианты матчинга, но сложность работы с такими фильтрами вышла за все допустимые рамки.
Настройка модели
Что еще пользователь Apache NlpCraft может настроить в модели, из того что может повлиять на работу с интентами:
- Указать минимальное и максимальное количество возможных слов в запросе. При несоответствии сконфигурированным значениям, предложение вообще не будет обработано, вне зависимости от содержимого интентов модели.
- Задать максимальное количество допустимых нераспознанных слов в запросе (регулировка степени уверенности в том, что запрос был разобран правильно), а также максимально возможное количество подозрительных, не встречающиеся в словаре, слов и т.д.
- Дополнительно сконфигурировать стоп-слова для модели: расширить перечень стандартных стоп-слов или исключить некоторые стандартные стоп-слова. Эта настройка может повлиять на количество учитываемых нераспознанных слов в запросе.
Указанные выше настройки применяются ко всей модели, а не к какому-либо конкретному интенту. Подробное описание работы с моделями и их параметрами — здесь.
Заключение
Я постарался описать основные возможности достаточно мощной системы построения интентов, предоставляемой проектом Apache NlpCraft и привести несколько примеров ее использования. Хочу обратить внимание на то, что я не ставил перед собой задачи сравнения каких-то проектов с целью выявления победителя, и рассказать, кто же лучше и гибче других поддерживает определение интентов. Alexa, Google Dialogflow — мощные, отточенные системы, и полагаю, что в силу специфики их архитектуры, инструментария и т.д., функциональность построения интентов в них ограничена вполне осознанно. Apache NlpCraft — проект совершенно другого рода, спроектированный для решения иного типа задач и обладающий принципиально иными возможностями. С одной стороны он не имеет некоторых неоспоримых преимуществ вышеперечисленных проектов, особенно в области интеграций, автоматизации развертывания, WebUI. C другой стороны он свободен от множества естественных ограничений этих проектов и может предоставить своим пользователям максимально гибкий NLP инструментарий, а также практически полный контроль над матчингом пользовательских запросов.




