
Первым делом, приступая к работе с новым набором данных, нужно понять его. Для того чтобы это сделать, нужно, например, выяснить диапазоны значений, принимаемых переменными, их типы, а также узнать о количестве пропущенных значений.
Библиотека pandas предоставляет нам множество полезных инструментов для выполнения разведочного анализа данных (Exploratory Data Analysis, EDA). Но, прежде чем воспользоваться ими, обычно нужно начать с функций более общего плана, таких как df.describe(). Правда, надо отметить, что возможности, предоставляемые подобными функциями, ограничены, а начальные этапы работы с любыми наборами данных при выполнении EDA очень часто сильно похожи друг на друга.

Автор материала, который мы сегодня публикуем, говорит, что он — не любитель выполнения повторяющихся действий. В результате он, в поисках средств, позволяющих быстро и эффективно выполнять разведочный анализ данных, нашёл библиотеку pandas-profiling. Результаты её работы выражаются не в виде неких отдельных показателей, а в форме довольно подробного HTML-отчёта, содержащего большую часть тех сведений об анализируемых данных, которые может понадобиться знать перед тем, как приступать к более плотной работе с ними.
Здесь будут рассмотрены особенности использования библиотеки pandas-profiling на примере набора данных Titanic.
Я решил поэкспериментировать с pandas-profiling на наборе данных Titanic из-за того, что в нём имеются данные разных типов и из-за наличия в нём пропущенных значений. Я полагаю, что библиотека pandas-profiling особенно интересна в тех случаях, когда данные ещё не очищены и требуют дальнейшей обработки, зависящей от их особенностей. Для того чтобы успешно выполнить подобную обработку, нужно знать о том, с чего начать, и на что обратить внимание. Здесь нам и пригодятся возможности pandas-profiling.
Для начала импортируем данные и используем pandas для получения показателей описательной статистики:
После выполнения этого фрагмента кода получится то, что показано на следующем рисунке.
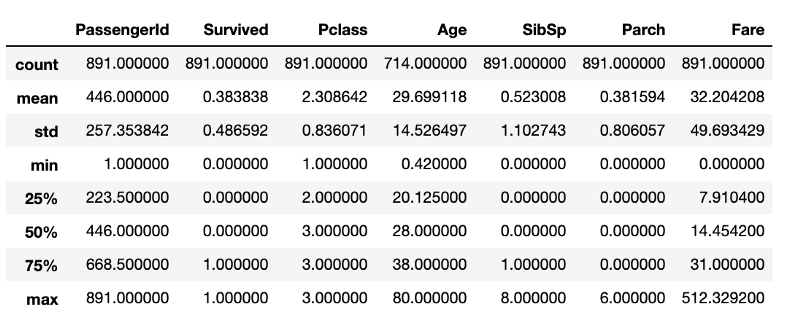
Показатели описательной статистики, полученные с помощью стандартных средств pandas
Хотя тут содержится масса полезных сведений, здесь нет всего, что было бы интересно узнать об исследуемых данных. Например, можно предположить, что во фрейме данных, в структуре
Теперь сделаем то же самое с использованием pandas-profiling:
Выполнение представленной выше строки кода позволит сформировать отчёт с показателями разведочного анализа данных. Код, показанный выше, приведёт к выводу найденных сведений о данных, но можно сделать так, чтобы в результате получился бы HTML-файл, который, например, можно кому-то показать.
Первая часть отчёта будет содержать раздел Overview (Обзор), дающий основные сведения о данных (количество наблюдений, количество переменных, и так далее). Кроме того, он будет содержать список предупреждений, уведомляющий аналитика о том, на что стоит обратить особое внимание. Эти предупреждения могут послужить подсказкой о том, на чём можно сосредоточить усилия при очистке данных.
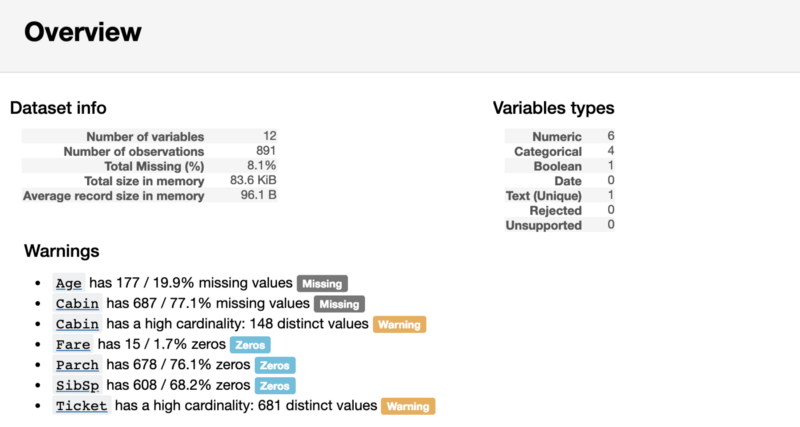
Раздел отчёта Overview
За разделом Overview в отчёте можно обнаружить полезные сведения о каждой переменной. В них, кроме прочего, входят небольшие диаграммы, описывающие распределение каждой переменной.

Сведения о числовой переменной Age
Как можно видеть из предыдущего примера, pandas-profiling даёт нам несколько полезных индикаторов, таких, как процент и количество пропущенных значений, а также показатели описательной статистики, которые мы уже видели. Так как
При рассмотрении категориальной переменной выводимые показатели немного отличаются от тех, что были найдены для числовой переменной.

Сведения о категориальной переменной Sex
А именно, вместо нахождения среднего, минимума и максимума, библиотека pandas-profiling нашла число классов. Так как
Если вы, как и я, любите исследовать код, то вас может заинтересовать то, как именно библиотека pandas-profiling вычисляет эти показатели. Узнать об этом, учитывая то, что код библиотеки открыт и доступен на GitHub, не так уж и сложно. Так как я не большой любитель использования «чёрных ящиков» в моих проектах, я взглянул на исходный код библиотеки. Например, вот как выглядит механизм обработки числовых переменных, представленный функцией describe_numeric_1d:
Хотя этот фрагмент кода и может показаться довольно большим и сложным, на самом деле, понять его очень просто. Речь идёт о том, что в исходном коде библиотеки имеется функция, которая определяет типы переменных. Если оказалось, что библиотека встретила числовую переменную, вышеприведённая функция найдёт показатели, которые мы рассматривали. В этой функции используются стандартные операции pandas по работе с объектами типа
После результатов анализа переменных pandas-profiling, в разделе Correlations, выведет корреляционные матрицы Пирсона и Спирмена.
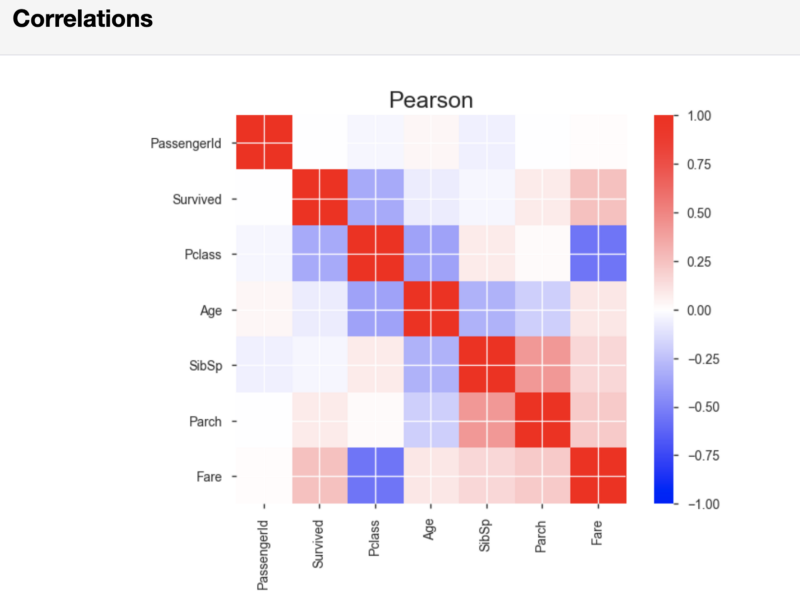
Корреляционная матрица Пирсона
Если нужно, то можно, в той строке кода, которая запускает формирование отчёта, задать показатели пороговых значений, применяемых при расчёте корреляции. Делая это, вы можете указать то, какая сила корреляции считается важной для вашего анализа.
И наконец, в отчёте pandas-profiling, в разделе Sample, выводится, в качестве примера, фрагмент данных, взятый из начала набора данных. Такой подход может привести к неприятным неожиданностям, так как первые несколько наблюдений могут представлять собой выборку, которая не отражает особенностей всего набора данных.
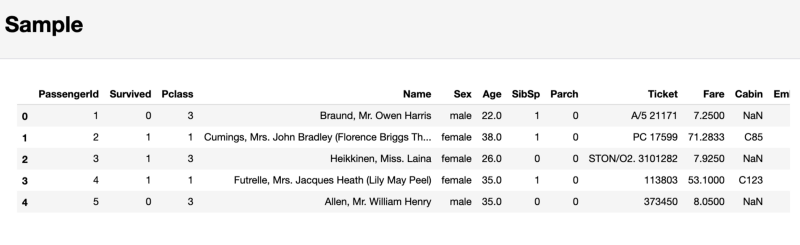
Раздел, содержащий образец исследуемых данных
В результате я не рекомендую обращать внимание на этот последний раздел. Вместо этого лучше воспользоваться командой
Подводя итог вышеизложенному, можно отметить, что библиотека pandas-profiling даёт в распоряжение аналитика некоторые полезные возможности, которые придутся кстати в тех случаях, когда нужно быстро получить общее приблизительное представление о данных или передать кому-нибудь отчёт о разведывательном анализе данных. При этом настоящая работа с данными, учитывающая их особенности, выполняется, как и без использования pandas-profiling, вручную.
Если вы хотите взглянуть на то, как выглядит весь разведывательный анализ данных в одном Jupyter-блокноте — взгляните на этот мой проект, созданный с помощью nbviewer. А в этом GitHub-репозитории можно найти соответствующий код.
Уважаемые читатели! С чего вы начинаете анализ новых наборов данных?

Библиотека pandas предоставляет нам множество полезных инструментов для выполнения разведочного анализа данных (Exploratory Data Analysis, EDA). Но, прежде чем воспользоваться ими, обычно нужно начать с функций более общего плана, таких как df.describe(). Правда, надо отметить, что возможности, предоставляемые подобными функциями, ограничены, а начальные этапы работы с любыми наборами данных при выполнении EDA очень часто сильно похожи друг на друга.
Автор материала, который мы сегодня публикуем, говорит, что он — не любитель выполнения повторяющихся действий. В результате он, в поисках средств, позволяющих быстро и эффективно выполнять разведочный анализ данных, нашёл библиотеку pandas-profiling. Результаты её работы выражаются не в виде неких отдельных показателей, а в форме довольно подробного HTML-отчёта, содержащего большую часть тех сведений об анализируемых данных, которые может понадобиться знать перед тем, как приступать к более плотной работе с ними.
Здесь будут рассмотрены особенности использования библиотеки pandas-profiling на примере набора данных Titanic.
Разведочный анализ данных средствами pandas
Я решил поэкспериментировать с pandas-profiling на наборе данных Titanic из-за того, что в нём имеются данные разных типов и из-за наличия в нём пропущенных значений. Я полагаю, что библиотека pandas-profiling особенно интересна в тех случаях, когда данные ещё не очищены и требуют дальнейшей обработки, зависящей от их особенностей. Для того чтобы успешно выполнить подобную обработку, нужно знать о том, с чего начать, и на что обратить внимание. Здесь нам и пригодятся возможности pandas-profiling.
Для начала импортируем данные и используем pandas для получения показателей описательной статистики:
# импорт необходимых пакетов
import pandas as pd
import pandas_profiling
import numpy as np
# импорт данных
df = pd.read_csv('/Users/lukas/Downloads/titanic/train.csv')
# вычисление показателей описательной статистики
df.describe()После выполнения этого фрагмента кода получится то, что показано на следующем рисунке.
Показатели описательной статистики, полученные с помощью стандартных средств pandas
Хотя тут содержится масса полезных сведений, здесь нет всего, что было бы интересно узнать об исследуемых данных. Например, можно предположить, что во фрейме данных, в структуре
DataFrame, имеется 891 строка. Если это нужно проверить, то потребуется ещё одна строка кода, определяющую размер фрейма. Хотя эти вычисления и не особенно ресурсозатратны, постоянное их повторение обязательно приведёт к потерям времени, которое, вероятно, лучше будет потратить на очистку данных.Разведочный анализ данных средствами pandas-profiling
Теперь сделаем то же самое с использованием pandas-profiling:
pandas_profiling.ProfileReport(df)Выполнение представленной выше строки кода позволит сформировать отчёт с показателями разведочного анализа данных. Код, показанный выше, приведёт к выводу найденных сведений о данных, но можно сделать так, чтобы в результате получился бы HTML-файл, который, например, можно кому-то показать.
Первая часть отчёта будет содержать раздел Overview (Обзор), дающий основные сведения о данных (количество наблюдений, количество переменных, и так далее). Кроме того, он будет содержать список предупреждений, уведомляющий аналитика о том, на что стоит обратить особое внимание. Эти предупреждения могут послужить подсказкой о том, на чём можно сосредоточить усилия при очистке данных.
Раздел отчёта Overview
Разведочный анализ переменных
За разделом Overview в отчёте можно обнаружить полезные сведения о каждой переменной. В них, кроме прочего, входят небольшие диаграммы, описывающие распределение каждой переменной.
Сведения о числовой переменной Age
Как можно видеть из предыдущего примера, pandas-profiling даёт нам несколько полезных индикаторов, таких, как процент и количество пропущенных значений, а также показатели описательной статистики, которые мы уже видели. Так как
Age — это числовая переменная, визуализация её распределения в виде гистограммы позволяет нам сделать вывод о том, что перед нами — скошенное вправо распределение.При рассмотрении категориальной переменной выводимые показатели немного отличаются от тех, что были найдены для числовой переменной.
Сведения о категориальной переменной Sex
А именно, вместо нахождения среднего, минимума и максимума, библиотека pandas-profiling нашла число классов. Так как
Sex — бинарная переменная, её значения представлены двумя классами.Если вы, как и я, любите исследовать код, то вас может заинтересовать то, как именно библиотека pandas-profiling вычисляет эти показатели. Узнать об этом, учитывая то, что код библиотеки открыт и доступен на GitHub, не так уж и сложно. Так как я не большой любитель использования «чёрных ящиков» в моих проектах, я взглянул на исходный код библиотеки. Например, вот как выглядит механизм обработки числовых переменных, представленный функцией describe_numeric_1d:
def describe_numeric_1d(series, **kwargs):
"""Compute summary statistics of a numerical (`TYPE_NUM`) variable (a Series).
Also create histograms (mini an full) of its distribution.
Parameters
----------
series : Series
The variable to describe.
Returns
-------
Series
The description of the variable as a Series with index being stats keys.
"""
# Format a number as a percentage. For example 0.25 will be turned to 25%.
_percentile_format = "{:.0%}"
stats = dict()
stats['type'] = base.TYPE_NUM
stats['mean'] = series.mean()
stats['std'] = series.std()
stats['variance'] = series.var()
stats['min'] = series.min()
stats['max'] = series.max()
stats['range'] = stats['max'] - stats['min']
# To avoid to compute it several times
_series_no_na = series.dropna()
for percentile in np.array([0.05, 0.25, 0.5, 0.75, 0.95]):
# The dropna() is a workaround for https://github.com/pydata/pandas/issues/13098
stats[_percentile_format.format(percentile)] = _series_no_na.quantile(percentile)
stats['iqr'] = stats['75%'] - stats['25%']
stats['kurtosis'] = series.kurt()
stats['skewness'] = series.skew()
stats['sum'] = series.sum()
stats['mad'] = series.mad()
stats['cv'] = stats['std'] / stats['mean'] if stats['mean'] else np.NaN
stats['n_zeros'] = (len(series) - np.count_nonzero(series))
stats['p_zeros'] = stats['n_zeros'] * 1.0 / len(series)
# Histograms
stats['histogram'] = histogram(series, **kwargs)
stats['mini_histogram'] = mini_histogram(series, **kwargs)
return pd.Series(stats, name=series.name)Хотя этот фрагмент кода и может показаться довольно большим и сложным, на самом деле, понять его очень просто. Речь идёт о том, что в исходном коде библиотеки имеется функция, которая определяет типы переменных. Если оказалось, что библиотека встретила числовую переменную, вышеприведённая функция найдёт показатели, которые мы рассматривали. В этой функции используются стандартные операции pandas по работе с объектами типа
Series, наподобие series.mean(). Результаты вычислений сохраняются в словаре stats. Гистограммы формируются с использованием адаптированной версии функции matplotlib.pyplot.hist. Адаптация направлена на то, чтобы функция могла бы работать с различными типами наборов данных.Показатели корреляции и образец исследуемых данных
После результатов анализа переменных pandas-profiling, в разделе Correlations, выведет корреляционные матрицы Пирсона и Спирмена.
Корреляционная матрица Пирсона
Если нужно, то можно, в той строке кода, которая запускает формирование отчёта, задать показатели пороговых значений, применяемых при расчёте корреляции. Делая это, вы можете указать то, какая сила корреляции считается важной для вашего анализа.
И наконец, в отчёте pandas-profiling, в разделе Sample, выводится, в качестве примера, фрагмент данных, взятый из начала набора данных. Такой подход может привести к неприятным неожиданностям, так как первые несколько наблюдений могут представлять собой выборку, которая не отражает особенностей всего набора данных.
Раздел, содержащий образец исследуемых данных
В результате я не рекомендую обращать внимание на этот последний раздел. Вместо этого лучше воспользоваться командой
df.sample(5), которая, случайным образом, выберет 5 наблюдений из набора данных.Итоги
Подводя итог вышеизложенному, можно отметить, что библиотека pandas-profiling даёт в распоряжение аналитика некоторые полезные возможности, которые придутся кстати в тех случаях, когда нужно быстро получить общее приблизительное представление о данных или передать кому-нибудь отчёт о разведывательном анализе данных. При этом настоящая работа с данными, учитывающая их особенности, выполняется, как и без использования pandas-profiling, вручную.
Если вы хотите взглянуть на то, как выглядит весь разведывательный анализ данных в одном Jupyter-блокноте — взгляните на этот мой проект, созданный с помощью nbviewer. А в этом GitHub-репозитории можно найти соответствующий код.
Уважаемые читатели! С чего вы начинаете анализ новых наборов данных?



