
Введение
В реляционных базах данных внешние ключи (foreign key) используются для обеспечения целостности связей между таблицами. Простыми словами, внешний ключ — это столбец (или несколько столбцов), ссылающийся на первичный ключ другой таблицы. Таблица с внешним ключом называется дочерней, а с первичным — родительской. При вставке строки в дочернюю таблицу проверяется наличие значения внешнего ключа в родительской таблице. Эти дополнительные операции иногда могут вызывать проблемы с блокировками и приводить к взаимоблокировкам. В этой статье мы изучим, почему это происходит, и как решать подобные проблемы.
Будем использовать две таблицы: Department (Отдел) и Employee (Сотрудник). Столбец DepId в таблице Employee определен как внешний ключ, поэтому значения этого столбца будут проверяться на наличие соответствующих значений в столбце DepartmentId таблицы Department.
CREATE TABLE [Department](
[DepartmentId] [int] NOT NULL PRIMARY KEY,
[DepartmentName] [varchar](10) NULL,
)
GO
CREATE TABLE [dbo].[Employee](
[EmployeeId] [int] NOT NULL PRIMARY KEY,
[FirstName] [varchar](50) NULL,
[LastName] [varchar](50) NULL,
[DepID] [int] NOT NULL,
[IsActive] [bit] NULL
) ON [PRIMARY]
ALTER TABLE [dbo].[Employee] WITH CHECK ADD FOREIGN KEY([DepID])
REFERENCES [dbo].[Department]([DepartmentId])
GO
CREATE NONCLUSTERED INDEX [IX_DepId] ON Employee
(
[DepID] ASC
)Что происходит за кулисами INSERT
Исследуем, какие операции выполняются при вставке данных в дочернюю таблицу (Employee).
Сначала вставим строку в родительскую таблицу (Department).
INSERT INTO Department (DepartmentId ,DepartmentName)
VALUES (1,'Sales')Перед выполнением следующего запроса включим отображение фактического плана выполнения и вставим строку в таблицу Employee (дочернюю).
INSERT INTO Employee (EmployeeId,FirstName,LastName,DepID,IsActive)
VALUES(1,'Brandon','Lord',1,0)
Clustered Index Insert вставляет данные в кластерный индекс, а также обновляет некластерные индексы. Если внимательно посмотреть на этот оператор, то можно заметить, что для него не указано имя объекта. Причина этого как раз в том, что при вставке данных в кластерный индекс таблицы Employee, эти данные одновременно добавляются в некластерный индекс. Эти два индекса можно увидеть во всплывающей подсказке оператора Clustered Index Insert.

Clustered Index Seek проверяет существование значения внешнего ключа в родительской таблице.
Nested Loops сравнивает вставленные значения внешних ключей со значениями, возвращаемые оператором Clustered Index Seek. В результате этого сравнения на выходе получается результат, который указывает, существует значение в родительской таблице или нет.
Assert оценивает результат оператора Nested Loops. Если Nested Loops возвращает NULL, то результат Assert будет ноль, и запрос вернет ошибку. В противном случае операция INSERT выполнится успешно.

Взаимные блокировки
При вставке данных в столбец с внешним ключом выполняются дополнительные операции по проверке существования данных в родительской таблице. В некоторых случаях, например, при массовой вставке, эта проверка может привести к взаимоблокировкам, когда несколько транзакций пытаются обратиться к одним и тем же данным. Попробуем смоделировать эту ситуацию. Сначала вставим данные в таблицу Department.
DECLARE @Counter AS INT=1
WHILE @Counter <=10000
BEGIN
SET @Counter = @Counter+1
INSERT INTO Department VALUES(@Counter,CONCAT('Column' , @Counter))
ENDПосле этого создадим глобальную временную таблицу, которая поможет со вставкой строк в Employee.
CREATE TABLE ##Emp (Id INT,EmpFname VARCHAR(50),EmpLname VARCHAR(50),DepId INT,IsActive bit)
DECLARE @Counter AS INT=1
DECLARE @RoundNumber AS INT
WHILE @Counter <=10000
BEGIN
SET @Counter = @Counter+1
SELECT @RoundNumber = ROUND(((10000) * RAND() + 1), 0)
INSERT INTO ##Emp VALUES(@Counter,'EmpFname', 'EmpLname',@RoundNumber , 0)
ENDСледующие запросы выполним в разных сессиях. Сначала "Часть 1" первого запроса:
--- Запрос-1:
--*** Часть 1 ***--
BEGIN TRAN
INSERT INTO [dbo].Department (DepartmentId, DepartmentName)
VALUES (10000,N'Lauren')
--- *** ---
-- *** Часть 2 ***--
INSERT INTO [Employee]
SELECT * FROM ##Emp WITH(NOLOCK)
WHERE DepId <=10000
--- *** ---И первую часть второго запроса:
--- Запрос-2:
--*** Часть 1 ***--
BEGIN TRAN
INSERT INTO [dbo].Department (DepartmentId,DepartmentName)
VALUES (10001, N'Lauren')
--- *** ---
--*** Часть 2 ***--
INSERT INTO [Employee]
SELECT * FROM ##Emp WITH(NOLOCK)
WHERE DepId <=9999
--- *** ---А теперь — вторые части запросов.

В результате возникла взаимная блокировка.
Давайте проанализируем, что произошло:
Первая часть Запроса-1 открывает транзакцию и вставляет строку в таблицу Department. Страница данных Department блокируется монопольной блокировкой намерения (IX, intent exclusive lock), а вставленная строка — монопольной блокировкой (X, exclusive lock).
Первая часть Запроса-2 также открывает транзакцию и вставляет строку в Department. Страница данных таблицы Department блокируется монопольной блокировкой намерения (IX), а вставленная строка — монопольной блокировкой (X). На данный момент проблем с блокировками нет.
Вторая часть Запроса-1, он начинает сканировать первичные ключи таблицы Department для проверки ссылочной целостности вставленных строк. Однако одна из строк заблокирована монопольной блокировкой в Запросе-2. В этом случае Запрос-1 должен дождаться завершения Запроса-2.
Запрос-2 блокируется при попытке прочитать строки, вставленные в Department в Запросе-1. У нас получилась взаимная блокировка.
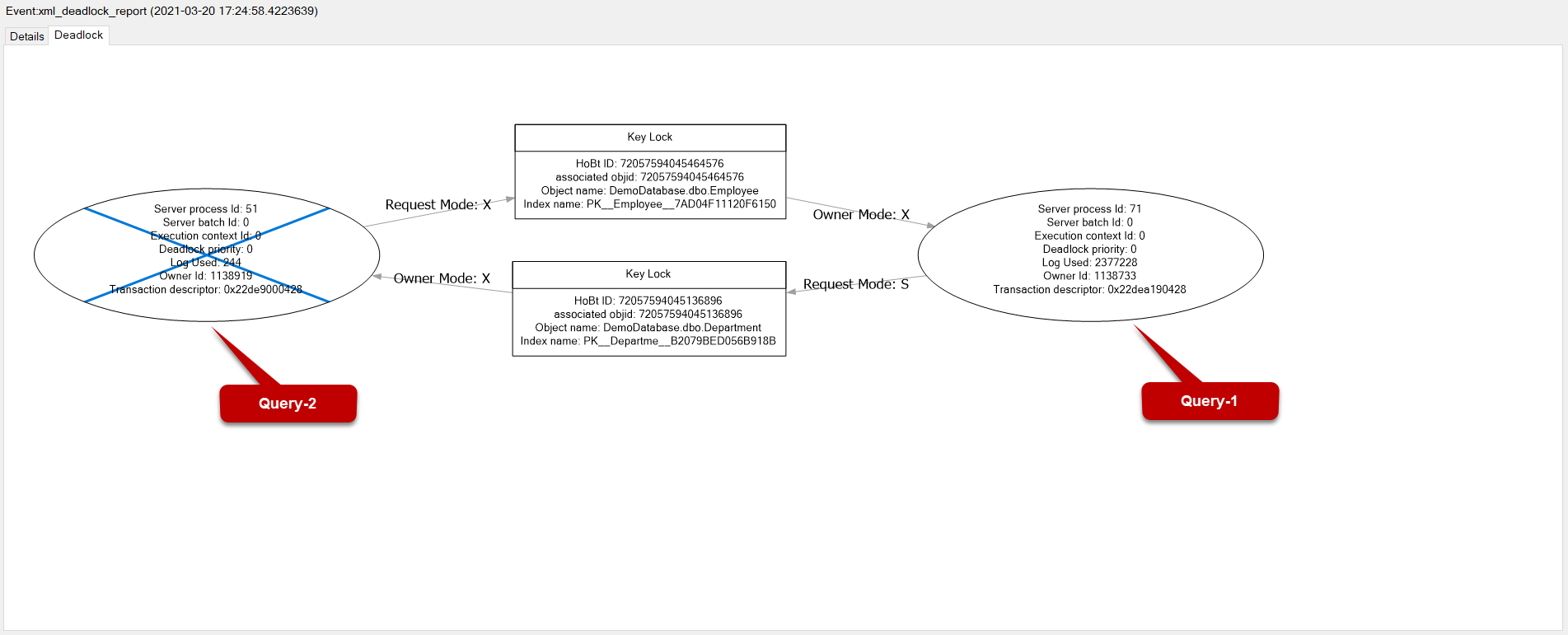
Приведенный ниже граф взаимных блокировок иллюстрирует то, о чем мы говорили. Сессия 71 (Запрос-1) получил монопольную блокировку (X) для строк таблицы Employee и хочет получить разделяемую блокировку (S) для строк таблицы Department. В это же время сессия 51 получила эксклюзивную блокировку (X) для строк таблицы Department и хочет получить монопольную блокировку (X) для строк таблицы Employee. В результате между этими двумя сессиями возникает борьба за ресурсы, и SQL Server завершает одну из сессий.
Устранение взаимных блокировок
Мы с вами увидели, что при массовых INSERT проверка целостности внешнего ключа вызывает проблему с блокировками. На самом деле эта проблема связана с методом доступа к данным родительской таблицы. Взглянув на план выполнения второй части запросов, мы увидим оператор Merge Join.
INSERT INTO [Employee]
SELECT * FROM ##Emp WITH(NOLOCK)
WHERE DepId <=9999
Соединение Merge Join является самым эффективным, но требует предварительной сортировки входных данных. В нашем случае при сканировании родительской таблицы Merge Join сталкивается с заблокированной строкой, и не может продолжить сканирование, пока блокировка не будет снята.
Мы можем изменить метод доступа к данным с помощью OPTION (LOOP JOIN). При использовании хинта LOOP JOIN, оптимизатор запросов SQL Server сгенерирует другой план выполнения и заменит оператор Merge Join оператором Nested Loops, а оператор Clustered Index Scan будет заменен оператором Clustered Index Seek. С помощью Clustered Index Seek доступ к данным родительской таблицы осуществляется напрямую, поэтому не требуется ждать заблокированных строк. С другой стороны, оператор Nested Loops выполняет построчное чтение, а Merge Join — одно последовательное чтение. Эти два изменения метода доступа к данным снижают вероятность блокировки запроса из-за наличия других блокировок.
INSERT INTO [Employee]
SELECT * FROM ##Emp WITH(NOLOCK)
WHERE DepId <=9999
OPTION (LOOP JOIN)
Row Count Spool используется для подсчета количества строк, возвращаемых оператором Clustered Index Seek, и передачи этой информации в оператор Nested Loops. Этот оператор используется оптимизатором запросов SQL Server для проверки существования строк, но не содержащихся в них данных.
Заключение
В этой статье мы узнали, как внешние ключи влияют на план запроса INSERT и добавляют некоторые операции в процесс его выполнения. Также мы увидели, что в некоторых ситуациях внешние ключи могут приводить к взаимным блокировкам. Для устранения проблем с блокировками можно использовать хинт LOOP JOIN.
Материал подготовлен в рамках курса «MS SQL Server Developer». Всех желающих приглашаем на открытый урок «SQL Server и Docker». На открытом уроке мы поговорим о контейнерах, а также рассмотрим развертывание SQL Server в контейнерах.
РЕГИСТРАЦИЯ




