
Чтобы машины могли обрабатывать текст на русском и «понимать» его, в NLP используются универсальные языковые модели и трансформеры — BERT, RoBERTa, XLNet и другие — архитектуры от 100 миллионов параметров, обученные на миллиардах слов. Все оригинальные модели появляются обычно для английского, показывают state-of-the-art в какой-нибудь прикладной задаче и только спустя полгода-год появляются и для русского языка, без тюнинга архитектуры.

Чтобы корректнее обучать свою модель для русского или другого языка и адаптировать её, хорошо бы иметь какие-то объективные метрики. Их существует не так много, а для нашей локали и вовсе не было. Но мы их сделали, чтобы продолжить развитие русских моделей для общей задачи General Language Understanding.
Мы — это команда AGI NLP Сбербанка, лаборатория Noah’s Ark Huawei и факультет компьютерных наук ВШЭ. Проект Russian SuperGLUE — это набор тестов на «понимание» текста и постоянный лидерборд трансформеров для русского языка.
Проект включает:
Тесты фактически представляют собой расширенный тест Тьюринга. Задача модели — доказать, что она сойдёт за среднего носителя языка. Тесты затрагивают такие базовые, но неосознаваемые знания об объектах и их взаимодействии:
Пример вопроса: «Почему судья стучал молоточком?»
А: «В зале стало шумно».
Б: «Жюри огласило свой вердикт».
В этой подгруппе тестов робот должен был доказать свою начитанность и на основе всех русских текстов (а это вся литература, очень много новостей, учебников, баз знаний и статей из Интернета, включая Хабр) сделать вывод, почему судья так сделал.
В 2018 году, когда появились универсальные языковые модели и трансформеры, можно назвать «временем ImageNet в NLP». Что это значит? Раньше нельзя было построить ML-решение на 200 примеров от заказчика — а теперь можно! И вполне нормальную модель. Чем меньше примеров, тем дальше в лес (few-shot learning, one-shot learning, zero-shot learning...). Выборки не просто не хватает, а её практически и нет. Но актуальные модели справляются с этим, потому что они уже видели почти всю вариативность языка, — они обучены на десятках млрд слов на каждом языке, а языков может быть больше 100.
Появляются такие модели, конечно, в основном для английского, а для остальных берётся «что есть» и дотюнивается. Появился набор тестов, позволяющий всесторонне и очень тщательно оценить качество работы модели. Благодаря этим тестам появились метрики, позволяющие эти модели сравнивать между собой — и между своими промежуточными версиями и форками.
Каждая модель получила свой огромный обучающий корпус, но, по сути, они более-менее одинаковы, и главные отличия — в архитектуре и заточенности под определённый тип заданий:
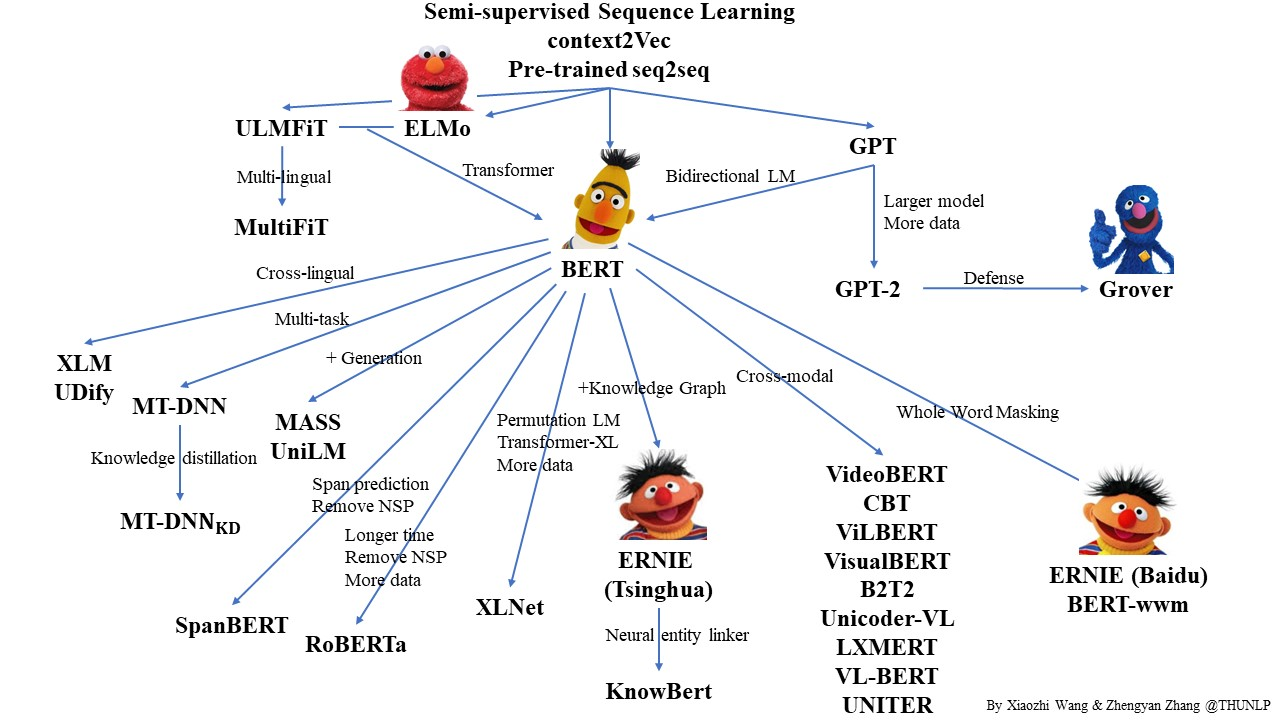
Некоторые модели мультиязычные, хотя в основном нет. На других языках работает, например, multilingual BERT, и даже частично переносит логику английского текста, хотя и обычно даёт качество чуть ниже модели, обученной на единственном языке. Насколько такая модель универсальна, если она оценивается только по своей англоязычной проходить тесты? Можно ли сказать, что такой «английский образ мышления» хуже подходит для японского дзен-процессинга или разбора исландских баз данных?
Benchmark-подход в машинном обучении подразумевает, что мы оцениваем вклад модели не в одну прикладную задачу, а сразу во много, и берём среднюю оценку.
Текст: «Сконструировали чудо-сани воспитанники Дома юношеского технического творчества. Базируются они на танке, который ребята сделали ранее, только срезали башенку, соорудили новый корпус и расписали хохломой — поскольку нас ждёт год Петуха».
Вопрос: «Есть ли между конструкцией и действиями в тексте причинно-следственная связь?»
А она есть!
Прежде чем мы разберёмся с этим примером, расскажу, как обычно составляются такие тесты. Англоязычный проект SuperGLUE, устроен так: набираются списки однотипных заданий, у которых содержание достаточно сложное — затрагивает знания о мире, здравый смысл, логику, целеполагание — а формат ответа простой, обычно — бинарная классификация. Часть из которых идёт на обучение модели, меньшая часть — на валидацию, и кусочек — на тест. Пример из начала главы как раз такой: в нём даётся пара предложений, и нужно ответить, есть ли между ними причинно-следственная связь или нет. Примеры в англоязычном наборе тестов сильно заточены под американские реалии — баскетбол, звёзды Голливуда и т. д. Собрать аналог мы решили, распарсив новостные сайты — и были поражены сложными примерами. Конкретно в данном случае, связь есть, потому что танк расписан хохломой в честь наступления года Петуха ¯\_(ツ)_/¯
Русский язык хоть по структуре и логике похож на английский, но имеет ряд системных отличий, который необходимо учитывать при обучении — например, порядок слов гораздо более свободный, поэтому связанные слова могут находиться друг от друга на большом расстоянии: значит, для того же word2vec нужно увеличивать окно.
Когда модель обучается с заданными параметрами на многих языках, измерить разницу очень сложно, потому что для русского языка лидерборда нет. Точнее, не было до недавних пор.
Чтобы такая шкала была — нужно взять английские тесты и по аналогии создать собственные. Это не перевод и даже не локализация, а именно конструирование огромного экзамена, который учитывает многообразие нашего языка. В тест включены задания на бинарную классификацию — логическую, на знание, на здравый смысл и на понимание языка независимо от всяческих речевых оборотов.
Мы это сделали и открываем всё это вот здесь на сайте. Там же находится лидерборд по уже имеющимся русским моделям.
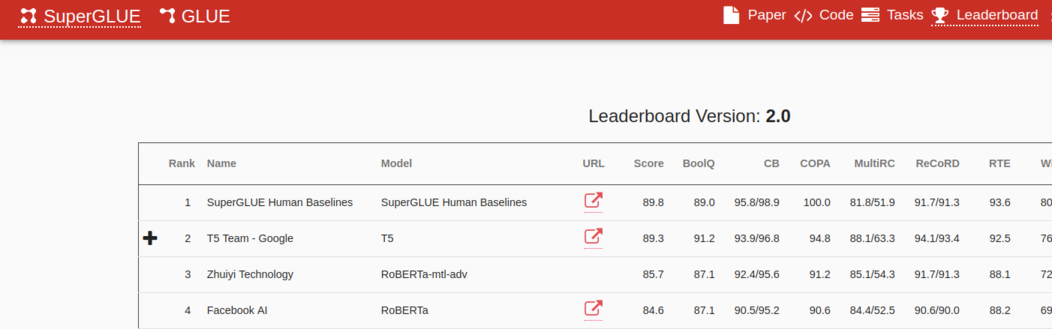
Такой подход существует и хорошо отработан для английского языка для моделей SuperGLUE, а для русского оценить все модели (BERT, RoBERTa, XLNet и так далее) было нельзя. Но теперь можно, и можно их сравнить между собой по самым разным параметрам. Что означает быстрое развитие их архитектуры.
Пока мы обижаем роботов. Средний человек справляется с заданием на 80,2 % успешно. На момент написания статьи машина справляется с заданием на 54,6 % успешно.
Разница видна в двух местах: во-первых, люди теряют концентрацию и совершают свои обычные человеческие ошибки. Когда испытуемый сыт, бодр, бдителен и имеет хороший уровень сахара в крови, ему нет равных. Длится это обычно шесть-восемь минут. Продлить этот период можно, объяснив, что он, как Джон Коннор, участвует в войне машин с человеком. Это даст 15 минут концентрации. После же человек расслабится и будет делать любые задания на 93-97 %.
Во-вторых, человека легко сбить. Не тебя, дорогой читатель, ты статистически обгонишь любого робота. А вот обычный человек не может сопоставить иногда даже простые вещи. На «все кракозябры чёрные», «некоторые кракозябры могут быть коровами», «все коровы чёрные или зелёные», «если вы видите чёрную корову — это кракозябра?» ломаются даже лучшие из нас, пропустившие курс логики.
Роботы способны прочитать «Войну и мир» и с лёгкостью простроить все логические связи между всеми, в сущности. Возможно, это выявит сразу пару десятков багов. А, возможно, если добавить всю мировую литературу, новости и огромное количество статей и научных работ — робот сможет даже пересказать главное. И ответить на вопрос, что хотел сказать автор.
Во всех остальных местах люди их уделывают. Но, как видно на английском лидерборде, разрыв постепенно сокращается — лучшая модель Т5 проходит тест на 89,3 %, а человек — на 89,8 %.
Мужчина чувствовал себя обязанным присутствовать на мероприятии:
А: «Друг предлагал ему пойти, но он отклонил предложение».
Б: «Он обещал своему другу, что пойдёт».
Как видите, тут простая логика.
Политик был признан виновным в мошенничестве:
А: «Он начал кампанию за переизбрание».
Б: «Он был отстранён от должности».
Здесь роботы колеблются, поскольку обучались на русском корпусе.
Вопрос на логику:
Как отмечается в сообщении, данная информация опубликована на странице «Обращение за визой США», а также при входе в консульский отдел посольства. Как ранее разъяснили в посольстве США, при обращении за визой на сайте заявители видят объявление, в котором говорится: «Пожалуйста, примите во внимание: не разрешается проносить (а) электронные устройства (за исключением мобильного телефона, размеры которого не превышают 3 см х 13 см х 6 см); (б) предметы, которые могут быть использованы как оружие; (с) большие сумки, включая портфели, рюкзаки, чемоданы, спортивные сумки и т. п. Поскольку сотрудники посольства не принимают на хранение такие предметы, их владельцам может быть запрещён вход в здание посольства».
Вопрос роботу: «А можно я пойду в посольство США с планшетом?»
Как видите, по такому примеру очень хорошо видно, как важно иметь NLP для чат-ботов (чтобы бот прочитал документ и ответил человеку по делу), и то, как удобно запускать NLP-модели в договоры, например, при валютном контроле для проверки соответствия легальности и счёту.
Но пойдём дальше:
«В первом периоде преимущество было на стороне наших хоккеистов, однако вратарь хозяев играл безупречно».
Вопрос: «В первом периоде наши хоккеисты играли лучше вратаря хозяев?»
Здесь ожидается ответ: ********, а именно — что данных недостаточно или вопрос поставлен некорректно. Машина так и делает с невозмутимым видом. Потому что она не за наших, а за абстрактную справедливость.
«Нам надо совместно проводить жёсткую политику: этого не должно быть, мы не должны травить людей. На нашей стороне это карается жёстко — это уголовно наказуемое деяние», — сказал он. Русый отметил, что если белорусские специалисты выявляют на рынке фальсифицированное продовольствие, тут же сообщают российским коллегам, потому что должна быть немедленная реакция».
Роботу нужно определить намерения стороны. Хотят ли белорусы, чтобы люди травились?
Ещё один блок вопросов тестирует эрудированность, начитанность и умение мыслить творчески. С последним у роботов плохо, но с первыми двумя качествами можно выкрутиться и из сложных ситуаций. Чтобы правильно отвечать, надо агрегировать знания, как можно и нельзя, как взаимодействуют объекты. Фрукты зелёные — скорее всего, их нельзя кушать, жёлтые — скорее всего, созрели. Если Морфеус предлагает выбирать вам между жёлтым и зелёным фруктом, значит, его можно паковать за хранение наркотиков, потому что таблетки у него в кармане. Примерно так. Вот самый простой пример:
«Никто не присоединяется к Facebook, чтобы быть грустным и одиноким. Но новое исследование психолога Университета Висконсина Джорджа Линкольна утверждает, что именно такими он и заставляет нас себя чувствовать».
Джордж Линкольн заставляет нас так себя чувствовать? Если нет — а кто тогда?
Более сложные вопросы выглядят так: вам дают прочитать все рассказы о Шерлоке Холмсе и спрашивают, существовал ли Шерлок Холмс в реальности. Робот проводит серьёзную дедуктивную работу и в конце концов решает, что либо да, либо нет, либо теория параллельных вселенных верна.
Ну и, конечно:
«Вы в пустыне и бредёте по песку. Вы смотрите под ноги и видите черепаху. Она перевёрнута на спину, и её брюшко жарится на палящем солнце. Она шевелит лапками и пытается перевернуться, но не может без вашей помощи. Но вы не помогаете. Почему?»
Шучу, конечно, пока этого нет. Но, думаю, машины очень быстро найдут правильные ответы на тест Войта-Кампфа.
Самый сложный тест из имеющихся — это, пожалуй, общая диагностика. На ней моделям предстоит классифицировать причинно-следственные связи в зависимости от разнообразных лингвистических явлений, намешанных в текст задания. Полный тест выложен в репозитории и на сайте.
Пока что результаты ниже, чем в английском, но в наших силах это исправить!

Некоторые задания (например, RUSSE — смысл слова в контексте) машина делает на 10-15% выше уровня человека!
Лучший результат показывает модель Russian monolingual BERT из DeepPavlov. Также результат чуть хуже показывают оригинальный multilingual BERT. В планах добавление и других моделей DeepPavlov, обученные на корпусе диалогов, а также «общеславянскую» модель BERT, знающую русский, чешский, польский и болгарский языки.
Для каждой модели доступна не только общая оценка, но и балл за каждый набор заданий. Их всего девять:
Достаточно просто. Нужно скачать задания с сайта, потом взять скрипты обучения последнего слоя трансформеров на заданиях и отправить архив с размеченными тестовыми файлами в личный кабинет.
Подробную инструкцию можно найти здесь.
Модель можно и непублично оценить, отправив размеченный тест и получив подробный результат. Мы приглашаем всех исследователей и разработчиков добавлять и улучшать свои модели для русского языка. Только предстоит оценить такие архитектуры, как T5, GPT-3 и другие — открытых реализаций на русском для них пока нет.
P.S. Если хотите добавить нетрансформерные модели (Elmo, ULMFit...) или внести любые предложения — приглашаем в наш репозиторий!
Facebook Research, Google и Amazon — борются за первое место в англоязычном лидерборде. У каждой из компаний есть много внутренних применений. В России этим занимается не так много компаний: DeepPavlov, Сбербанк, Huawei.
На подготовку тестов и лидерборда ушло три месяца работы нашей команды в Сбербанке, коллег из «Ноева ковчега» Huawei и ФКН ВШЭ.
Другие материалы:
Чтобы корректнее обучать свою модель для русского или другого языка и адаптировать её, хорошо бы иметь какие-то объективные метрики. Их существует не так много, а для нашей локали и вовсе не было. Но мы их сделали, чтобы продолжить развитие русских моделей для общей задачи General Language Understanding.
Мы — это команда AGI NLP Сбербанка, лаборатория Noah’s Ark Huawei и факультет компьютерных наук ВШЭ. Проект Russian SuperGLUE — это набор тестов на «понимание» текста и постоянный лидерборд трансформеров для русского языка.
Проект включает:
- Тесты навыков: здравый смысл, целеполагание, логика.
- Тестирование уровня человека для сравнения.
- Оценку существующих моделей — BERT, RоBERTa и другие.
- Ответы на вопрос, как оценить свою модель.
Тесты фактически представляют собой расширенный тест Тьюринга. Задача модели — доказать, что она сойдёт за среднего носителя языка. Тесты затрагивают такие базовые, но неосознаваемые знания об объектах и их взаимодействии:
Пример вопроса: «Почему судья стучал молоточком?»
А: «В зале стало шумно».
Б: «Жюри огласило свой вердикт».
В этой подгруппе тестов робот должен был доказать свою начитанность и на основе всех русских текстов (а это вся литература, очень много новостей, учебников, баз знаний и статей из Интернета, включая Хабр) сделать вывод, почему судья так сделал.
Почему модели нужно оценивать независимо?
В 2018 году, когда появились универсальные языковые модели и трансформеры, можно назвать «временем ImageNet в NLP». Что это значит? Раньше нельзя было построить ML-решение на 200 примеров от заказчика — а теперь можно! И вполне нормальную модель. Чем меньше примеров, тем дальше в лес (few-shot learning, one-shot learning, zero-shot learning...). Выборки не просто не хватает, а её практически и нет. Но актуальные модели справляются с этим, потому что они уже видели почти всю вариативность языка, — они обучены на десятках млрд слов на каждом языке, а языков может быть больше 100.
Появляются такие модели, конечно, в основном для английского, а для остальных берётся «что есть» и дотюнивается. Появился набор тестов, позволяющий всесторонне и очень тщательно оценить качество работы модели. Благодаря этим тестам появились метрики, позволяющие эти модели сравнивать между собой — и между своими промежуточными версиями и форками.
Каждая модель получила свой огромный обучающий корпус, но, по сути, они более-менее одинаковы, и главные отличия — в архитектуре и заточенности под определённый тип заданий:
Некоторые модели мультиязычные, хотя в основном нет. На других языках работает, например, multilingual BERT, и даже частично переносит логику английского текста, хотя и обычно даёт качество чуть ниже модели, обученной на единственном языке. Насколько такая модель универсальна, если она оценивается только по своей англоязычной проходить тесты? Можно ли сказать, что такой «английский образ мышления» хуже подходит для японского дзен-процессинга или разбора исландских баз данных?
Benchmark-подход в машинном обучении подразумевает, что мы оцениваем вклад модели не в одну прикладную задачу, а сразу во много, и берём среднюю оценку.
Собираем тесты или проблемы русского здравого смысла
Текст: «Сконструировали чудо-сани воспитанники Дома юношеского технического творчества. Базируются они на танке, который ребята сделали ранее, только срезали башенку, соорудили новый корпус и расписали хохломой — поскольку нас ждёт год Петуха».
Вопрос: «Есть ли между конструкцией и действиями в тексте причинно-следственная связь?»
А она есть!
Прежде чем мы разберёмся с этим примером, расскажу, как обычно составляются такие тесты. Англоязычный проект SuperGLUE, устроен так: набираются списки однотипных заданий, у которых содержание достаточно сложное — затрагивает знания о мире, здравый смысл, логику, целеполагание — а формат ответа простой, обычно — бинарная классификация. Часть из которых идёт на обучение модели, меньшая часть — на валидацию, и кусочек — на тест. Пример из начала главы как раз такой: в нём даётся пара предложений, и нужно ответить, есть ли между ними причинно-следственная связь или нет. Примеры в англоязычном наборе тестов сильно заточены под американские реалии — баскетбол, звёзды Голливуда и т. д. Собрать аналог мы решили, распарсив новостные сайты — и были поражены сложными примерами. Конкретно в данном случае, связь есть, потому что танк расписан хохломой в честь наступления года Петуха ¯\_(ツ)_/¯
Русский язык хоть по структуре и логике похож на английский, но имеет ряд системных отличий, который необходимо учитывать при обучении — например, порядок слов гораздо более свободный, поэтому связанные слова могут находиться друг от друга на большом расстоянии: значит, для того же word2vec нужно увеличивать окно.
Когда модель обучается с заданными параметрами на многих языках, измерить разницу очень сложно, потому что для русского языка лидерборда нет. Точнее, не было до недавних пор.
Чтобы такая шкала была — нужно взять английские тесты и по аналогии создать собственные. Это не перевод и даже не локализация, а именно конструирование огромного экзамена, который учитывает многообразие нашего языка. В тест включены задания на бинарную классификацию — логическую, на знание, на здравый смысл и на понимание языка независимо от всяческих речевых оборотов.
Мы это сделали и открываем всё это вот здесь на сайте. Там же находится лидерборд по уже имеющимся русским моделям.
Такой подход существует и хорошо отработан для английского языка для моделей SuperGLUE, а для русского оценить все модели (BERT, RoBERTa, XLNet и так далее) было нельзя. Но теперь можно, и можно их сравнить между собой по самым разным параметрам. Что означает быстрое развитие их архитектуры.
А что люди?
Пока мы обижаем роботов. Средний человек справляется с заданием на 80,2 % успешно. На момент написания статьи машина справляется с заданием на 54,6 % успешно.
Разница видна в двух местах: во-первых, люди теряют концентрацию и совершают свои обычные человеческие ошибки. Когда испытуемый сыт, бодр, бдителен и имеет хороший уровень сахара в крови, ему нет равных. Длится это обычно шесть-восемь минут. Продлить этот период можно, объяснив, что он, как Джон Коннор, участвует в войне машин с человеком. Это даст 15 минут концентрации. После же человек расслабится и будет делать любые задания на 93-97 %.
Во-вторых, человека легко сбить. Не тебя, дорогой читатель, ты статистически обгонишь любого робота. А вот обычный человек не может сопоставить иногда даже простые вещи. На «все кракозябры чёрные», «некоторые кракозябры могут быть коровами», «все коровы чёрные или зелёные», «если вы видите чёрную корову — это кракозябра?» ломаются даже лучшие из нас, пропустившие курс логики.
Роботы способны прочитать «Войну и мир» и с лёгкостью простроить все логические связи между всеми, в сущности. Возможно, это выявит сразу пару десятков багов. А, возможно, если добавить всю мировую литературу, новости и огромное количество статей и научных работ — робот сможет даже пересказать главное. И ответить на вопрос, что хотел сказать автор.
Во всех остальных местах люди их уделывают. Но, как видно на английском лидерборде, разрыв постепенно сокращается — лучшая модель Т5 проходит тест на 89,3 %, а человек — на 89,8 %.
Покажем немного вопросов теста
Мужчина чувствовал себя обязанным присутствовать на мероприятии:
А: «Друг предлагал ему пойти, но он отклонил предложение».
Б: «Он обещал своему другу, что пойдёт».
Как видите, тут простая логика.
Политик был признан виновным в мошенничестве:
А: «Он начал кампанию за переизбрание».
Б: «Он был отстранён от должности».
Здесь роботы колеблются, поскольку обучались на русском корпусе.
Вопрос на логику:
Как отмечается в сообщении, данная информация опубликована на странице «Обращение за визой США», а также при входе в консульский отдел посольства. Как ранее разъяснили в посольстве США, при обращении за визой на сайте заявители видят объявление, в котором говорится: «Пожалуйста, примите во внимание: не разрешается проносить (а) электронные устройства (за исключением мобильного телефона, размеры которого не превышают 3 см х 13 см х 6 см); (б) предметы, которые могут быть использованы как оружие; (с) большие сумки, включая портфели, рюкзаки, чемоданы, спортивные сумки и т. п. Поскольку сотрудники посольства не принимают на хранение такие предметы, их владельцам может быть запрещён вход в здание посольства».
Вопрос роботу: «А можно я пойду в посольство США с планшетом?»
Как видите, по такому примеру очень хорошо видно, как важно иметь NLP для чат-ботов (чтобы бот прочитал документ и ответил человеку по делу), и то, как удобно запускать NLP-модели в договоры, например, при валютном контроле для проверки соответствия легальности и счёту.
Но пойдём дальше:
«В первом периоде преимущество было на стороне наших хоккеистов, однако вратарь хозяев играл безупречно».
Вопрос: «В первом периоде наши хоккеисты играли лучше вратаря хозяев?»
Здесь ожидается ответ: ********, а именно — что данных недостаточно или вопрос поставлен некорректно. Машина так и делает с невозмутимым видом. Потому что она не за наших, а за абстрактную справедливость.
«Нам надо совместно проводить жёсткую политику: этого не должно быть, мы не должны травить людей. На нашей стороне это карается жёстко — это уголовно наказуемое деяние», — сказал он. Русый отметил, что если белорусские специалисты выявляют на рынке фальсифицированное продовольствие, тут же сообщают российским коллегам, потому что должна быть немедленная реакция».
Роботу нужно определить намерения стороны. Хотят ли белорусы, чтобы люди травились?
Ещё один блок вопросов тестирует эрудированность, начитанность и умение мыслить творчески. С последним у роботов плохо, но с первыми двумя качествами можно выкрутиться и из сложных ситуаций. Чтобы правильно отвечать, надо агрегировать знания, как можно и нельзя, как взаимодействуют объекты. Фрукты зелёные — скорее всего, их нельзя кушать, жёлтые — скорее всего, созрели. Если Морфеус предлагает выбирать вам между жёлтым и зелёным фруктом, значит, его можно паковать за хранение наркотиков, потому что таблетки у него в кармане. Примерно так. Вот самый простой пример:
«Никто не присоединяется к Facebook, чтобы быть грустным и одиноким. Но новое исследование психолога Университета Висконсина Джорджа Линкольна утверждает, что именно такими он и заставляет нас себя чувствовать».
Джордж Линкольн заставляет нас так себя чувствовать? Если нет — а кто тогда?
Более сложные вопросы выглядят так: вам дают прочитать все рассказы о Шерлоке Холмсе и спрашивают, существовал ли Шерлок Холмс в реальности. Робот проводит серьёзную дедуктивную работу и в конце концов решает, что либо да, либо нет, либо теория параллельных вселенных верна.
Ну и, конечно:
«Вы в пустыне и бредёте по песку. Вы смотрите под ноги и видите черепаху. Она перевёрнута на спину, и её брюшко жарится на палящем солнце. Она шевелит лапками и пытается перевернуться, но не может без вашей помощи. Но вы не помогаете. Почему?»
Шучу, конечно, пока этого нет. Но, думаю, машины очень быстро найдут правильные ответы на тест Войта-Кампфа.
Самый сложный тест из имеющихся — это, пожалуй, общая диагностика. На ней моделям предстоит классифицировать причинно-следственные связи в зависимости от разнообразных лингвистических явлений, намешанных в текст задания. Полный тест выложен в репозитории и на сайте.
Оцениваем модели для русского
Пока что результаты ниже, чем в английском, но в наших силах это исправить!
Некоторые задания (например, RUSSE — смысл слова в контексте) машина делает на 10-15% выше уровня человека!
Лучший результат показывает модель Russian monolingual BERT из DeepPavlov. Также результат чуть хуже показывают оригинальный multilingual BERT. В планах добавление и других моделей DeepPavlov, обученные на корпусе диалогов, а также «общеславянскую» модель BERT, знающую русский, чешский, польский и болгарский языки.
Для каждой модели доступна не только общая оценка, но и балл за каждый набор заданий. Их всего девять:
- LiDiRus (Linguistic Diagnostic for Russian) или просто общая диагностика — её мы полностью адаптировали с английского варианта.
- DaNetQA — набор вопросов на здравый смысл и знание, с ответом да или нет (собрали с нуля).
- RCB (Russian Commitment Bank) — классификация наличия причинно-следственных связей между текстом и гипотезой из него (собрали с нуля по новостям и худлиту).
- PARus (Plausible Alternatives for Russian) — целеполагание, выбор из альтернативных вариантов на основе здравого смысла (собрали с нуля по новостям и худлиту из корпуса Тайга).
- MuSeRC (Multi-Sentence Reading Comprehension) — машинное чтение. Задания содержат текст и вопрос к нему, но такой, на который можно ответить, сделав вывод из текста (найти ответ поиском нельзя).
- RuCoS (Russian reading comprehension with Commonsense) — машинное чтение. Модели даётся новостной текст, а также его краткое содержание, в котором стоит пропуск — пропуск нужно восстановить, выбрав из вариантов. (Тут опять новостные сайты нам помогли.)
- TERRa (Textual Entailment Recognition for Russian) — классификация наличия причинно-следственных связей между предложениями (собрали с нуля по новостям и худлиту).
- RUSSE (Russian Semantic Evaluation) — задача распознавания смысла слова в контексте (word sense disambiguation). (Этот датасет был единственный готовый, спасибо семинару.)
- RWSD (Russian Winograd Schema Dataset) — задания на логику, с добавленными неоднозначностями («Если бы у Ивана был осёл, он бы его бил»). Создан по аналогии с класической Winograd Schema (тут тоже пришлось переводить, как и в диагностике).
- Все датасеты взвешены, случайное угадывание даёт результат около 50 %.
Как добавить свою модель на лидерборд?
Достаточно просто. Нужно скачать задания с сайта, потом взять скрипты обучения последнего слоя трансформеров на заданиях и отправить архив с размеченными тестовыми файлами в личный кабинет.
Подробную инструкцию можно найти здесь.
Модель можно и непублично оценить, отправив размеченный тест и получив подробный результат. Мы приглашаем всех исследователей и разработчиков добавлять и улучшать свои модели для русского языка. Только предстоит оценить такие архитектуры, как T5, GPT-3 и другие — открытых реализаций на русском для них пока нет.
P.S. Если хотите добавить нетрансформерные модели (Elmo, ULMFit...) или внести любые предложения — приглашаем в наш репозиторий!
FAQ
Facebook Research, Google и Amazon — борются за первое место в англоязычном лидерборде. У каждой из компаний есть много внутренних применений. В России этим занимается не так много компаний: DeepPavlov, Сбербанк, Huawei.
На подготовку тестов и лидерборда ушло три месяца работы нашей команды в Сбербанке, коллег из «Ноева ковчега» Huawei и ФКН ВШЭ.
Другие материалы:
- Вопросы оценки интеллекта.
- Материалы теста и лидерборд ещё раз, там же открытый код.
- Аналогичный английский проект.




