
Введение
Компания, в которой я работаю, пишет свою собственную систему фильтрации трафика и защищает с помощью нее бизнес от DDoS-атак, ботов, парсеров, а также многого другого. В основе продукта лежит такой процесс, как реверсивное проксирование, с помощью которого мы в реальном времени анализируем большие объемы трафика и, в конце концов, пропускаем только легитимные пользовательские запросы, отсеивая все вредоносные.
Основной особенностью является то, что наши сервисы работают с нелимитированным входящим трафиком, поэтому очень важно использовать все ресурсы рабочих станций максимально эффективно. В этом нам помогает большой опыт разработки на современном C++, включая последние стандарты и набор библиотек под названием boost.
Реверсивное проксирование
Давайте вернемся к реверсивному проксированию и посмотрим, как можно реализовать его на C++ и boost.asio. В первую очередь нам понадобятся два объекта под названием серверная и клиентская сессии. Серверная сессия устанавливает и обслуживает соединение с браузером, клиентская устанавливает и обслуживает соединение с сервисом. Также вам понадобится потоковый буфер, инкапсулирующий внутри себя работу с памятью, в которую происходит чтение из сокета серверной сессии и из которой происходит запись в сокет клиентской сессии. Примеры серверных и клиентских сессий можно найти в документации к boost.asio. Как работать с потоковым буфером можно подсмотреть там же.
После того, как мы из примеров соберем прототип реверсивного прокси, станет ясно, что обслуживать нелимитированный входящий трафик такое приложение, вероятно, не будет. Тогда мы начнем наращивать сложность кода. Задумаемся о многопоточности, вокерах и пулах для io контекстов, а также многом другом. В частности, о преждевременных оптимизациях, связанных с копированием памяти между серверной и клиентской сессиями.
О каком копировании памяти идет речь? Дело в том, что при фильтрации трафик не всегда передается в неизменном виде. Посмотрите на пример ниже: в нем мы удаляем один хедер и добавляем вместо него два. Количество пользовательских запросов, над которыми производятся схожие действия, растет с усложнением логики внутри сервиса. Бездумно копировать данные в таких случаях ни в коем случае нельзя! Если меняется только 1% от всего запроса, а 99% остаются неизменными, то новую память вы должны выделять только под этот 1%. Поможет вам в этом boost::asio::const_buffer и boost::asio::mutable_buffer, с помощью которых вы сможете представить несколько непрерывных блоков памяти одной сущностью.
Пользовательский запрос:
Browser -> Proxy:
> POST / HTTP/1.1
> User-Agent: curl/7.29.0
> Host: 127.0.0.1:50080
> Accept: */*
> Content-Length: 5888903
> Content-Type: application/x-www-form-urlencoded
> ...
Proxy -> Service:
> POST / HTTP/1.1
> User-Agent: curl/7.29.0
> Host: 127.0.0.1:50080
> Accept: */*
> Transfer-Encoding: chunked
> Content-Type: application/x-www-form-urlencoded
> Expect: 100-continue
> ...
Service -> Proxy:
< HTTP/1.1 200 OK
Proxy -> Browser
< HTTP/1.1 200 OKПроблема
В итоге мы получили готовое приложение, которое умеет хорошо масштабироваться и наделено разного рода оптимизациями. Запустив его в продакшне, мы довольно-таки долго радовались тому, как хорошо и стабильно оно работает.
Со временем у нас стало появляться все больше и больше клиентов, с приходом которых вырос и трафик. В какой-то момент мы столкнулись с проблемой нехватки производительности во время отражения больших атак. Проанализировав сервис с помощью утилиты perf, мы обратили внимание, что все операции с кучей под нагрузкой находятся в топе. Затем мы воссоздали аналогичную ситуация на тестовом контуре с помошью yandex-tank и патронов, сгенерированных на основе реального трафика. Подцепившись к сервису через amplifier увидели следующую картину…
Скриншот amplifier (woslab):
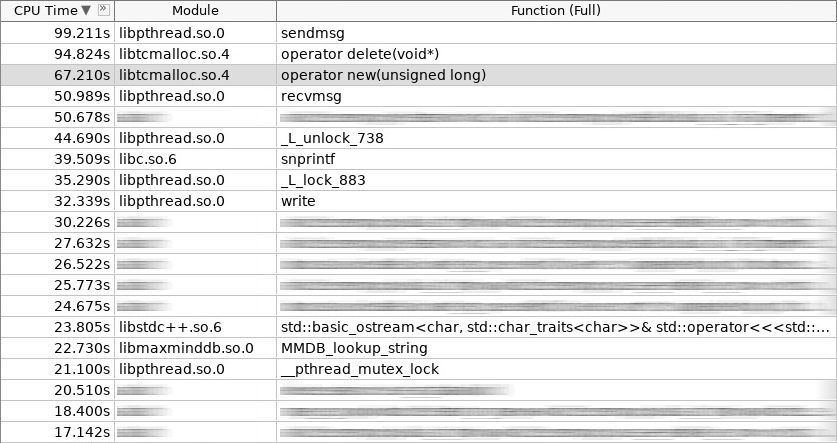
На скриншоте operator new работал 67 секунд, а operator delete и того больше — 97 секунд.
Такая ситуация нас расстроила. Как уменьшить время пребывания приложения в operator new и operator delete? Логично, что это можно сделать, отказавшись от постоянных аллокаций часто создаваемых и удаляемых объектов в куче. Мы остановились на трех подходах. Два из них стандартные: object pool и stack allocation. На первый подход хорошо ложатся клиентские сессии, которые организуются в пул на этапе старта приложения. Второй подход используется повсеместно везде, где пользовательский запрос обрабатывается от начала и до конца в одном и том же стеке, иными словами, в одном и том же хэндлере io контекста. Более подробно на этом останавливаться не будем. Лучше поговорим о третьем подходе, как наиболее сложном и интересном. Называется он slab allocation или slab распределением.
Идея slab распределения не нова. Она была придумана и реализована в Solaris, перекочевав позже в ядро Linux, и заключается в том, что часто используемые однотипные объекты проще хранить в пуле. Мы просто берем объект из пула, когда он нам нужен, а по завершении работы возвращаем его обратно. Никаких вызовов operator new и operator delete! Более того, минимум инициализации. В ядре slab распределение применяется для семафоров, дескрипторов файлов, процессов и потоков. В нашем же случае оно прекрасно легло на серверные и клиентские сессии, а также все то, что находится внутри них.
Диаграмма (slab распределение):

Помимо того, что slab аллокаторы есть в ядре, их реализации также существуют и в юзерспейсе. Их немного, а тех, что активно развиваются, так вообще единицы. Мы остановились на библиотеке под названием libsmall, которая является частью tarantool. В ней есть все необходимое.
- small::allocator
- small::slab_cache (thread local)
- small::slab
- small::arena
- small::quota
Структура small::slab — это пул с конкретным типом объектов. Структура small::slab_cache — это кэш, содержащий внутри себя различные списки пулов с конкретным типом объектов. Структура small::allocator — код, который выбирает необходимый кэш, ищет в нем подходящий пул, в котором распределяет запрашиваемый объект. Что делают объекты small::arena и small::quota будет понятно из примеров ниже.
Обертывание
Библиотека libsmall написана на C, а не на C++, поэтому нам пришлось разработать несколько оберток для прозрачной интеграции в стандартную библиотеку C++.
- variti::slab_allocator
- variti::slab
- variti::thread_local_slab
- variti::slab_allocate_shared
Класс variti::slab_allocator реализует минимальные требования, которые выдвигаются стандартом при написании своего собственного аллокатора. Внутри классов variti::slab инкапсулирована вся работа с билиотекой libsmall. Зачем нужен variti::thread_local_slab? Дело в том, что кэши slab распределения являются thread local объектами. Это означает, что у каждого потока свой набор кэшей. Сделано это для того, чтобы свести к нулю количество блокируемых операций при распределении нового объекта. Поэтому в памяти каждого потока мы размещаем свой экземпляр класса variti::slab, а доступ к нему регулируем с помощью обертки variti::thread_local_slab. Про шаблонную функцию variti::slab_allocate_shared расскажу позже.
Внутри класса variti::slab_allocator все достаточно просто. У него есть возможность ребайнда с одного типа на другой, например, с void на char. Из интересного, можно обратить внимание на преобазование nullptr в исключение std::bad_alloc в случае, когда внутри slab распределения заканчивается память. В остальном, это проброс вызовов внутрь обертки variti::thread_local_slab.
Сниппет (slab_allocator.hpp):
template <typename T>
class slab_allocator {
public:
using value_type = T;
using pointer = value_type*;
using const_pointer = const value_type*;
using reference = value_type&;
using const_reference = const value_type&;
template <typename U>
struct rebind {
using other = slab_allocator<U>;
};
slab_allocator() {}
template <typename U>
slab_allocator(const slab_allocator<U>& other) {}
T* allocate(size_t n, const void* = nullptr) {
auto p = static_cast<T*>(thread_local_slab::allocate(sizeof(T) * n));
if (!p && n)
throw std::bad_alloc();
return p;
}
void deallocate(T* p, size_t n) {
thread_local_slab::deallocate(p, sizeof(T) * n);
}
};
template <>
class slab_allocator<void> {
public:
using value_type = void;
using pointer = void*;
using const_pointer = const void*;
template <typename U>
struct rebind {
typedef slab_allocator<U> other;
};
};Давайте посмотрим, как реализованы конструктор и деструктор variti::slab. В конструкторе мы отводим суммарно для всех объектов не более 1 GiB памяти. Размер каждого пула в нашем случае не превышает 1 MiB. Минимальный объект, который мы можем распределить, имеет размер 2 байта (на самом деле libsmall увеличит его до минимально требуемого — 8 байтов). Остальные объекты, доступные через наше slab распределение, будут иметь размер кратный двум (задается константой 2.f). Итого, вы сможете распределить объекты размером 8, 16, 32 и т.д. Если же запрашиваемый объект имеет размер 24 байта, то произойдет оверхед по памяти. Распределение вернет вам этот объект, но размещен он будет в пуле, который соответствует объекту размером 32 байта. Оставшиеся 8 байт будут простаивать.
Сниппет (slab.hpp):
inline void* phys_to_virt_p(void* p)
{ return reinterpret_cast<char*>(p) + sizeof(std::thread::id); }
inline size_t phys_to_virt_n(size_t n)
{ return n - sizeof(std::thread::id); }
inline void* virt_to_phys_p(void* p)
{ return reinterpret_cast<char*>(p) - sizeof(std::thread::id); }
inline size_t virt_to_phys_n(size_t n)
{ return n + sizeof(std::thread::id); }
inline std::thread::id& phys_thread_id(void* p)
{ return *reinterpret_cast<std::thread::id*>(p); }
class slab : public noncopyable {
public:
slab() {
small::quota_init(& quota_, 1024 * 1024 * 1024);
small::slab_arena_create(&arena_, & quota_, 0, 1024 * 1024, MAP_PRIVATE);
small::slab_cache_create(&cache_, &arena_);
small::allocator_create(&allocator_, &cache_, 2, 2.f);
}
~slab() {
small::allocator_destroy(&allocator_);
small::slab_cache_destroy(&cache_);
small::slab_arena_destroy(&arena_);
}
void* allocate(size_t n) {
auto phys_n = virt_to_phys_n(n);
auto phys_p = small::malloc(&allocator_, phys_n);
if (!phys_p)
return nullptr;
phys_thread_id(phys_p) = std::this_thread::get_id();
return phys_to_virt_p(phys_p);
}
void deallocate(const void* p, size_t n) {
auto phys_p = virt_to_phys_p(const_cast<void*>(p));
auto phys_n = virt_to_phys_n(n);
assert(phys_thread_id(phys_p) == std::this_thread::get_id());
small::free(&allocator_, phys_p, phys_n);
}
private:
small::quota quota_;
small::slab_arena arena_;
small::slab_cache cache_;
small::allocator allocator_;
};Все эти ограничения касаются конкретного экземпляра класса variti::slab. Так как у каждого потока он свой (вспомните о thread local), то общий лимит на процесс составит не 1 GiB, а будет прямо пропорционален количеству потоков, в которых используется slab распределение.
Диаграмма (std::thread::id):
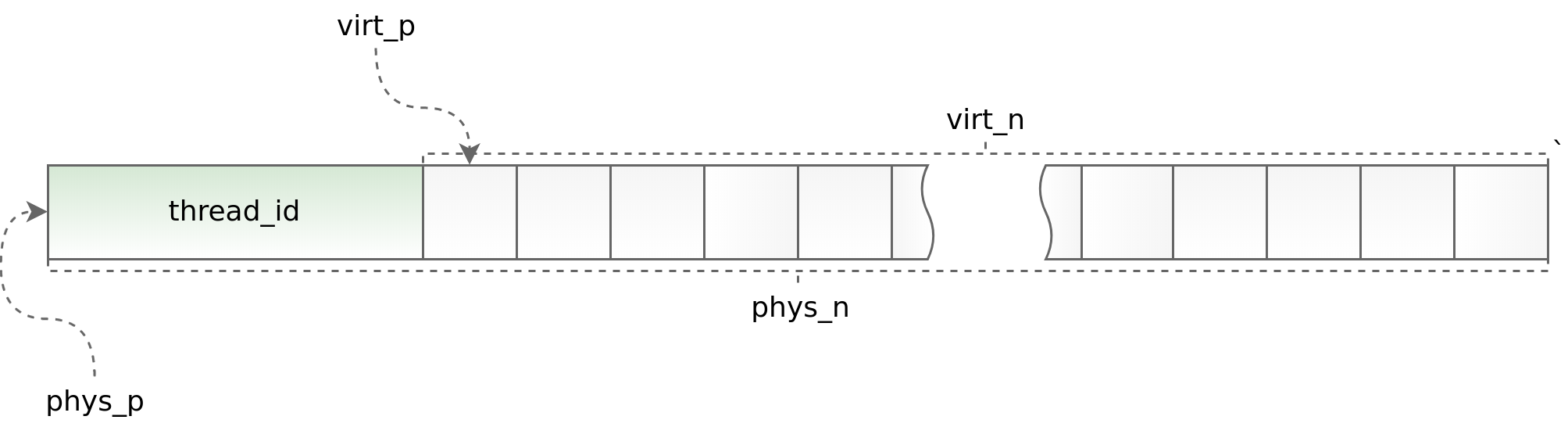
С одной стороны использование thread local позволяет ускорить работу slab распределения в многопоточном приложении, с другой — накладывает серьезные ограничения на архитектуру асинхронного приложения. Вы обязаны запрашивать и возвращать объект в одном и том же потоке. Делать это в рамках boost.asio порой очень проблематично. Для отслеживания заведомо ошибочных ситуаций мы в начале каждого объекта размещаем идентификатор потока, в котором вызывается метод allocate. Затем этот идентификатор сверяется в методе deallocate. Помогают в этом хелперы phys_to_virt_p и virt_to_phys_p.
Сниппет (thread_local_slab.hpp):
class thread_local_slab : public noncopyable {
public:
static void initialize();
static void finalize();
static void* allocate(size_t n);
static void deallocate(const void* p, size_t n);
};Сниппет (thread_local_slab.cpp):
static thread_local slab* slab_;
void thread_local_slab::initialize() { slab_ = new slab(slab_cfg_); }
void thread_local_slab::finalize() { delete slab_; }
void* thread_local_slab::malloc(size_t n) { return slab_->malloc(n); }
void thread_local_slab::free(const void* p, size_t n) { slab_->free(p, n); }Когда контроль над потоком теряется (при передаче объекта между различными io контекстами), осуществить корректное освобождение объекта позволяет умный указатель. Все, что он делает, это распределяет объект, запоминая его io контекст, а затем оборачивает в std::shared_ptr с кастомным делитером, который не сразу возвращает объект в распределение, а делает это в сохраненном ранее io контексте. Это хорошо работает, когда каждый io контекст запускается на одном потоке. В противном случае, к сожалению, такой подход не применим.
Сниппет (slab_helper.hpp):
template <typename T, typename Allocator, typename... Args>
std::shared_ptr<T> slab_allocate_shared(Allocator allocator, Args... args) {
T* p = allocator.allocate(1);
new ((void*)p) T(std::forward<Args>(args)...);
std::shared_ptr<T> ptr(p, [allocator](T* p) {
p->~T();
allocator.deallocate(p);
});
return ptr;
};
template <typename T, typename Allocator, typename... Args>
std::shared_ptr<T> slab_allocate_shared(Allocator allocator, boost::asio::io_service* io, Args... args) {
T* p = allocator.allocate(1);
new ((void*)p) T(std::forward<Args>(args)...);
std::shared_ptr<T> ptr(p, [allocator, io](T* p) {
io->post([allocator, p]() {
p->~T();
allocator.deallocate(p);
});
});
return ptr;
};Решение
После того, как работа над обертыванием libsmall была завершена, мы в первую очередь перевели на slab аллокаторы чанки внутри потокового буфера. Сделать это было довольно просто. Получив положительный результат, мы пошли дальше и применили slab аллокаторы сначала к самому потоковому буферу, а затем и ко всем объектам внутри серверной и клиентской сессий.
- variti::chunk
- variti::streambuf
- variti::server_session
- variti::client_session
При этом пришлось решить дополнительные задачи, а именно: перевести на slab аллокаторы простые объекты, составные объекты и коллекции. И если с первыми двумя классами объектов серьезных затруднений не возникло (составные объекты сводятся к простым), то при переводе коллекций мы столкнулись с серьезными трудностями.
- std::list
- std::deque
- std::vector
- std::string
- std::map
- std::unordered_map
Одно из главных ограничений при работе со slab распределением заключается в том, что количество разнотипных объектов не должно быть слишком большим (чем оно меньше, тем лучше). В таком контексте какие-то коллекции могут хорошо ложиться на концепцию slab аллокаторов, а какие-то нет.
Для std::list slab аллокаторы подходят замечательно. Эта коллекция реализована внутри с помощью связного списка, каждый элемент которого имеет фиксированный размер. Таким образом, с добавлением новых данных в std::list в slab распределении не появляются новые типы объектов. Обозначенное выше условие выполняется! Аналогично устроен и std::map. Разница лишь в том, что внутри него не связный список, а дерево.
В случае std::deque все сложнее. Эта коллекция реализована через непрерывный блок памяти, который содержит указатели на чанки. Пока чанков достатоточно, std::deque ведет себя также, как и std::list, но когда они заканчиваются, этот самый блок памяти перераспределяется. С точки зрения slab аллокаторов каждое перераспределение памяти — это объект с новым типом. Количество добавляемых в коллекцию объектов напрямую зависит от пользователя и может неподконтрольно расти. Эта ситуация не приемлема, поэтому мы либо заранее ограничили размер std::deque там, где это было возможно, либо отдали предпочтение std::list.
Если взять std::vector и std::string, то в них все еще сложнее. Реализация этих коллекций в чем-то схожа с std::deque, за исключением того, что их непрерывный блок памяти растет заметно быстрее. Мы заменили std::vector и std::string на std::deque, а в худшем случае на std::list. Да, мы потеряли в функциональности и где-то даже в производительности, но это повлияло на итоговую картину сильно меньше, чем те оптимизации, ради которых все и задумывалось.
Ровно то же самое мы проделали и с std::unordered_map, отказавшись от него в пользу самописаного variti::flat_map, реализованного через std::deque. При этом часто используемые ключи мы просто закэшировали в отдельных переменных, например, как это сделано с хедерами http запроса в nginx.
Вывод
Закончив полный перевод серверных и клиентский сессий на slab аллокаторы, мы сократили время работы с кучей более, чем в полтора раза.
Скриншот amplifier (coldslab):
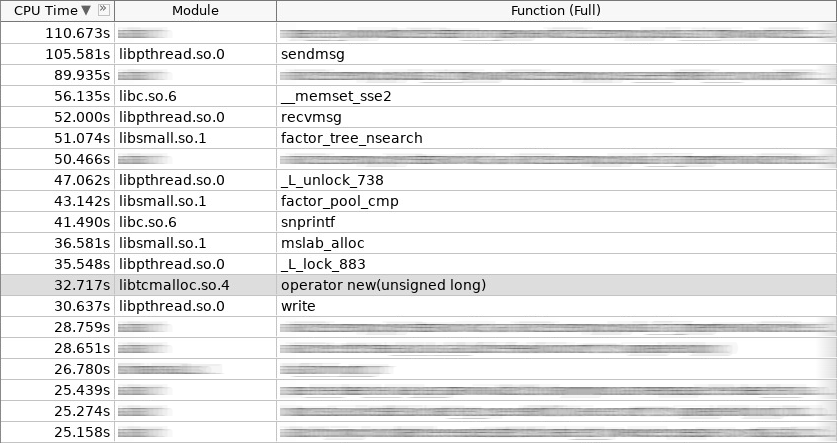
На скриншоте operator new работал 32 секунды, а operator delete — 24 секунды. К этому времени добавились другие функции работы с кучей: smalloc — 21 секунда, mslab_alloc — 37 секунд, smfree — 8 секунд, mslab_free — 21 секунда. Итого, 143 секунды против 161 секунды.
Но эти замеры производились сразу после запуска сервиса без первичной инициализации кэшей в slab распределении. После повторной стрельбы из yandex-tank общая картина улучшилась.
Скриншот amplifier (hotslab):
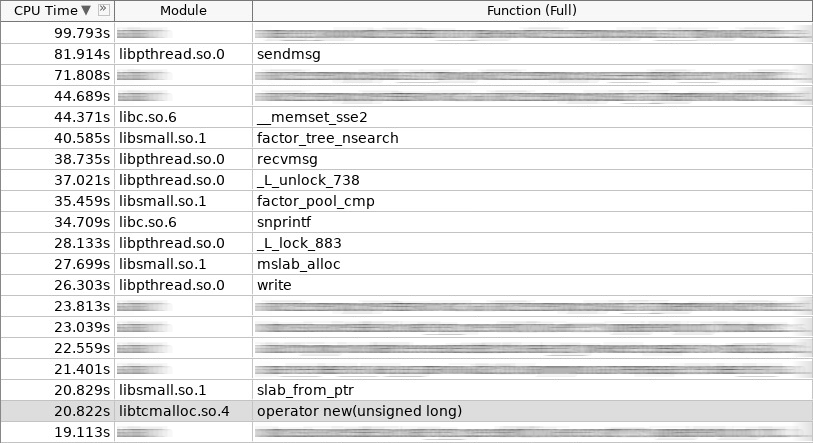
На скриншоте operator new работал 20 секунд, smalloc — 16 секунд, mslab_alloc — 27 секунд, operator delete — 16 секунд, smfree — 7 секунд, mslab_free — 17 секунд. Итого, 103 секунды против 161 секунды.
Таблица замеров:
woslab coldslab hotslab
operator new 67s 32s 20s
smalloc - 21s 16s
mslab_alloc - 37s 27s
operator delete 94s 24s 16s
smfree - 8s 7s
mslab_free - 21s 17s
summary 161s 143s 103s
В реальной жизни результат должен быть еще лучше, так как slab аллокаторы решают не только проблему долгого выделения и освобождения памяти, но и уменьшают фрагментацию. Без slab со временем работа operator new и operator delete должна была бы только замедлиться. Со slab — она всегда останется на одном и том же уровне.
Как мы видим, slab аллокаторы успешно решают проблему распределения памяти часто используемых объектов. Обратите на них внимание, если вопрос частого создания и удаления объектов для вас актуален. Но не забывайте об ограничениях, которые они накладывают на архитектуру вашего приложения! Далеко не все сложные объекты можно просто разместить в slab распределении. Иногда приходится отказываться от много! Ну и чем сложнее архитектура вашего приложения, тем чаще вам придется заботиться о возвращении объекта в корректный с точки зрения многопоточности кэш. Это может быть просто, когда вы сразу проработали архитектуру приложения с учетом использования slab аллокаторов, но точно вызовет трудности, когда вы решили их интергрировать уже на поздней стадии.
Приложение
Ознакомиться с исходным кодом можно тут!




